



1. Introduction▲
1-1. Pourquoi IPv6Â ?▲
IP v4 montre ses limites devant l'accroissement énorme de la demande d'adresses sur l'internet :
- le gaspillage d'adresses induit par la notion de classes a déjà été en partie résolu avec CIDR, mais ne répond pas à l'accroissement prévisible de la demande ;
- l'historique de la distribution des adresses a créé une parcellisation des blocs d'adressages qui contraint les routeurs à avaler des tables de routage interminables, ce qui ralentit leurs performances et nécessite des ressources matérielles sans cesse croissantes.
Alors qu'aujourd'hui, en France, environ 50 % des foyers sont connectés et disposent d'une seule adresse IPv4, l'avenir laisse imaginer qu'un jour plus ou moins proche, chaque foyer disposera de plusieurs dizaines d'objets potentiellement connectables à l'internet et que les technologies palliatives telles que NAT ne répondront plus au besoin.
Les pays « émergents » sont de plus en plus demandeurs, non seulement de ressources énergétiques fossiles, mais aussi d'adresses IP. Pour l'énergie fossile, le problème est délicat. Il l'est aussi pour les adresses IP, mais un protocole est plus facile et surtout plus rapide à élaborer que du pétrole, du gaz ou du charbon.
Une recherche de solution a été initiée en 1990 et a débouché en 1994 sur le choix d'IPv6. Ce n'est donc pas à proprement parler une nouveauté, bien que ce protocole soit encore en phase d'expérimentation.
1-2. Comment IPv6Â ?▲
Nous allons nous donner comme objectif de réaliser un réseau local connecté à l'internet, utilisant IPv6 tel que mis à disposition par le fournisseur Free. D'autres solutions sont possibles bien sûr.
Ce réseau local est constitué de postes de travail équipés de GNU/Linux (Ubuntu « Hardy Heron », Debian « Etch » ou « Lenny »). Une passerelle (Debian Etch) assure le routage NAT en IPv4 vers l'internet via une « FreeBox » dont les fonctions de routeur ne sont pas activées. Nous aurions pu bien évidemment choisir l'option de la simplicité, en utilisant tout bonnement les fonctions de routeur IPv4 de la Freebox, mais où aurait été le plaisir ?
L'objectif est d'arriver à ce que chaque station du LAN puisse disposer d'une adresse IPv6 « publique » et que donc, chaque station puisse accéder et être jointe directement par d'autres nœuds de l'internet.
Comme nous sommes encore loin de disposer d'un internet « full IPv6 », il nous faudra fonctionner en mode hybride, IPv4 avec NAT et IPv6.
2. CaractĂ©ristiques gĂ©nĂ©rales▲
Il n'est pas ici question de faire un cours complet sur IPv6. Il existe un excellent ouvrage intitulé « IPv6 Théorie et Pratique » publié et mis en ligne par les éditions O'Reilly. Nous nous contenterons du strict minimum pour pouvoir pratiquer.
2-1. La longueur▲
Une adresse v6 est écrite sur 128 bits, à comparer aux 32 bits d'IP v4. Pour donner un ordre de grandeur « à la louche », alors que IP v4 peut fournir environ 4 milliards d'adresses (232, soit environ 4 x 109), IP v6 peut en fournir plus d'un quadrillion de fois autant (2128 soit environ 3 x 1038), permettant ainsi de distribuer un peu plus d'un trilliard d'adresses par mètre carré…
Bien sûr ces chiffres ne veulent pas dire grand-chose, si ce n'est que l'humanité devrait être à l'abri d'une pénurie d'adresses pour quelque temps.
Nous verrons que comme à chaque fois que l'homme a la sensation de disposer d'une ressource à profusion, il s'empresse de la gaspiller. Mais tout de même l'opulence est telle qu'elle dépasse les capacités de gaspillage humain.
2-2. Le format d'Ă©criture▲
Il n'est plus question ici d'utiliser une écriture similaire à celle qui est habituellement employée pour IP v4 :
- l'écriture est désormais faite en hexadécimal ;
- les mots sont constitués de 16 bits ;
- ils sont séparés par un « : ».
Exemple :
2a01:05d8:52f3:500d:021b:fcff:fe71:1486Vous le voyez, c'est quand mĂŞme moins lisible que l'IP v4.
2-2-1. Simplifications▲
Pour « simplifier » l'écriture, dans chaque mot, il est possible d'omettre les zéros non significatifs (à gauche). Ainsi, notre exemple précédent peut s'écrire :
2a01:5d8:52f3:500d:21b:fcff:fe71:1486Bien sûr, il peut se faire que l'on ait des adresses contenant des mots entiers égaux à 0, par exemple :
2a01:05d8:52f3:500d:0000:0000:0000:0001Dans un tel cas, nous pouvons bien sûr simplifier comme suit :
2a01:5d8:52f3:500d:0:0:0:1ce qui n'est déjà pas si mal, mais nous pouvons aller encore plus loin en remplaçant une série de mots nuls par « :: ». Ceci nous donne :
2a01:5d8:52f3:500d::1Pour des raisons assez évidentes, ce dernier type de simplification ne peut être utilisé qu'une seule fois dans l'adresse. Si nous écrivions :
2a01::12::1seriez-vous capable de dire combien il y a de mots nuls dans la première simplification et combien il en reste dans la seconde ?
Exercice inverse : nous avons l'adresse (très simplifiée)
2a01:5d8::1Comme nous savons qu'il doit y avoir huit mots au total et qu'il n'y en a que trois de significatifs, c'est qu'il y en a cinq qui sont nuls :
2a01:5d8:0:0:0:0:0:1et donc finalement :
2a01:05d8:0000:0000:0000:0000:0000:0001sans aucune simplification.
2-2-2. PrĂ©fixe et jeton▲
Comme pour IP v4, une adresse v6 donne deux informations :
- un identifiant de réseau (préfixe) ;
- un identifiant de nœud dans le réseau (jeton).
Le préfixe est constitué d'un certain nombre de bits de masque, en partant du poids le plus fort, exactement comme en notation CIDR avec IP v4. Ainsi, l'adresse notée 2a01:5d8:52f3:500d:21b:fcff:fe71:1486/64 indique que les 64 premiers bits seront communs à tous les nœuds qui sont dans le même réseau IP. Autrement dit :
- 2a01:5d8:52f3:500d::/64 est l'adresse du réseau ;
- 21b:fcff:fe71:1486 (le jeton) est représentatif du nœud dans ce réseau.
Notez que dans cet exemple, qui n'est pas du tout imaginaire, l'administrateur dispose de 64 bits pour identifier les machines de son réseau, ce qui fait quand même pas mal de nœuds adressables.
3. Adressage(s) d'un nĹ“ud▲
Avec IP v4, attribuer plusieurs adresses IP à un même nœud n'est pas courant. C'est en revanche tout à fait banal avec IP v6. Cette démarche pourra vous paraitre curieuse, mais c'est parce que vous ne savez pas encore tout de ce merveilleux protocole…
3-1. PortĂ©e des adresses▲
Nous disposerons d'adresses dont la portée est plus ou moins grande, en fonction des besoins.
3-1-1. Scope link▲
La portée « lien local » permet aux nœuds connectés au même réseau physique de communiquer entre eux. Ces adresses ne doivent pas passer les routeurs. La portée est similaire à celle des adresses MAC sur le réseau Ethernet.
Quel que soit le réseau sur lequel nous nous trouvons, chaque nœud disposera d'une adresse de portée locale dans le réseau FE80::/10 (premier gaspillage, calculez le nombre de nœuds possibles…). Ainsi, l'adresse fe80::21b:11ff:fe52:bfab est une adresse de type « lien local ».
3-1-2. Scope Global▲
La portée globale, en revanche, est une adresse qui permettra de communiquer avec tout nœud situé sur l'internet. C'est l'équivalent d'une adresse « publique » IP v4. Ces adresses doivent être routées partout dans le monde.
3-1-3. Et pour les grands rĂ©seaux d'entreprise ?▲
La notion d'adresse « privée » telle qu'utilisée en IP v4 a disparu des RFC IP v6. Ces adresses ne sont par définition pas routables sur l'internet, mais permettent de structurer de gros réseaux d'entreprise, sans nécessiter de connectivité à l'internet. Le RFC 4193 (Unique Local IPv6 Unicast Addresses). Si vous êtes dans ce cas…
4. ParticularitĂ©s▲
4-1. Autoconfiguration▲
Il y a de nombreuses nouveautés dans IPv6, dont une qui n'est certes pas économe elle non plus, mais qui permet une configuration assez simple des nœuds du réseau.
Avec IPv4, nous ne connaissons que deux moyens vraiment exploitables pour disposer d'une configuration IP valide :
- la configuration entièrement manuelle ;
- la configuration automatique via DHCP.
Certes, il existe un ersatz d'autoconfiguration, mais qui n'est utilisable que sur un petit réseau, sans passerelle vers l'extérieur.
IPv6 propose un moyen d'autoconfiguration efficace, mais gourmand, encore appelé « configuration sans état ». Le « jeton » va être créé automatiquement, le plus souvent à partir de l'adresse MAC de l'interface à configurer. Cette méthode nécessite d'absorber 64 bits sur les 128 disponibles (encore un gaspillage).
L'IEEE a défini un identificateur global à 64 bits (format EUI-64). Les adaptateurs Ethernet disposent d'une adresse MAC codée sur 48 bits. L'IETF a fourni un algorithme de conversion qui permet de passer d'un identifiant MAC à un identifiant EUI-64
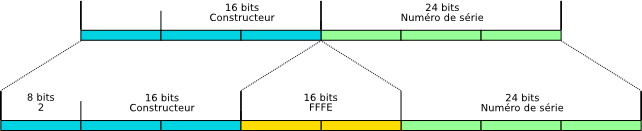
4-1-1. Exemple▲
Nous disposons de l'adresse MACÂ :
00:1B:11:52:BF:AB- l'identifiant constructeur est : 1B:11
- le numéro de série est : 52:BF:AB
Ceci nous donnera en octets :
02:1b:11:ff:fe:52:bf:abEt en mots de 16 bits comme il sied Ă une adresse IP v6 BCBGÂ :
21b:11ff:fe52:bfabNous pouvons donc tout de suite construire une adresse de type « lien local » en ajoutant le préfixe idoine :
fe80::21b:11ff:fe52:bfab4-1-2. VĂ©rification▲
~$ ifconfig eth0
eth0 Lien encap:Ethernet HWaddr 00:1B:11:52:BF:AB
inet adr:192.168.10.47 Bcast:192.168.10.255 Masque:255.255.255.0
adr inet6: fe80::21b:11ff:fe52:bfab/64 Scope:Lien
...Le préfixe utilisé ici est spécifique au lien local. Si nous disposons d'un préfixe distribué par notre fournisseur d'accès, nous pourrons aussi construire une adresse de type globale :
~$ ifconfig eth0
eth0 Lien encap:Ethernet HWaddr 00:1B:11:52:BF:AB
inet adr:192.168.10.47 Bcast:192.168.10.255 Masque:255.255.255.0
adr inet6: 2a01:5d8:52f3:500d:21b:11ff:fe52:bfab/64 Scope:Global
adr inet6: fe80::21b:11ff:fe52:bfab/64 Scope:LienNotez que :
- le préfixe distribué par notre fournisseur d'accès est ici : 2a01:5d8:52f3:500d::/64 ;
- le « jeton » est rigoureusement le même sur les deux adresses IPv6.
4-1-3. ConfidentialitĂ©▲
Cette méthode peut présenter une atteinte à la vie privée. En effet, l'adresse MAC est en quelque sorte une signature. Il devient donc possible de « tracer » une machine sur un réseau (ordinateur portable en particulier). Le RFC3041 propose une méthode alternative à partir d'un tirage aléatoire.
4-2. Configuration dĂ©terminĂ©e▲
Il reste possible cependant de faire appel à des méthodes plus connues en IPv4 :
- une configuration manuelle, fort peu intéressante en IPv6, sauf dans certains cas très particuliers ;
- une configuration de type DHCP qui, à l'heure où je rédige ces lignes, n'a pas encore fait la preuve de sa réelle utilité. Il n'existe à ce jour que peu d'implémentations complètes de DHCPv6, comme décrit dans le RFC3315.
Ce type de configuration est appelé « configuration avec état ».
4-3. DurĂ©e de vie d'une adresse▲
IPv6 est conçu pour un adressage dynamique des nœuds. L'expérience montre avec IP v4 que l'adressage statique s'avère trop contraignant dans bien des cas. IP v6 prévoit donc qu'un nœud puisse changer d'adresse IP, même s'il reste connecté 24/7 à l'internet. Ceci est rendu possible par :
- la possibilité d'attribuer plusieurs adresses IP à la même interface ;
- la définition d'un mode d'obsolescence progressif d'une adresse.
Pour anticiper un peu sur la suite, voici un exemple :
~# ip -6 addr ls dev eth0
1: eth0: <BROADCAST,MULTICAST,UP,10000> mtu 1500
inet6 2a01:e35:2e52:9840:220:18ff:fe2d:d291/64 scope global dynamic
valid_lft 86331sec preferred_lft 86331sec
inet6 2a01:5d8:52e5:2984:220:18ff:fe2d:d291/64 scope global deprecated dynamic
valid_lft 86331sec preferred_lft -69sec
...Comme nous le voyons ici, eth0 dispose de deux adresses de scope global. Elles disposent toutes deux de deux paramètres :
- valid_lft (durée de vie de validité) ;
- preferred_lft (durée de vie de préférence).
L'adresse 2a01:5d8:52e5:2984:220:18ff:fe2d:d291 est affublée d'un valid_lft positif, mais d'un preferred_lft négatif, ce qui confère à cette adresse des propriétés spéciales :
- elle est toujours valide (valid_lft positif)Â ;
- elle est « deprecated » (preferred_lft négatif).
Autrement dit, cet hôte, lorsqu'il va initier une nouvelle connexion IP n'utilisera pas cette adresse, mais l'autre : 2a01:e35:2e52:9840:220:18ff:fe2d:d291. En revanche, l'adresse dépréciée pourra continuer a être utilisée sur les connexions déjà en cours.
Nous comprendrons mieux comment ces choses se passent lorsque nous étudierons la façon d'obtenir une adresse globale sans état.
4-4. ICMP et ARP▲
Nous sommes en IPv6, mais en dessous, il y a toujours Ethernet (du moins sur notre LAN). ARP permet, avec IPv4, d'obtenir l'adresse MAC Ă laquelle il faut envoyer l'information, suivant l'adresse IP du destinataire.
Ce mécanisme doit bien sûr exister aussi en IPv6, mais il est pris en charge par ICMP et ARP n'existe plus. Nous verrons comment un peu plus loin.
5. Le lien local▲
Nous allons sans tarder effectuer une première manipulation. Pour l'instant, nous ne disposons que de deux hôtes, connectés entre eux par un simple HUB, sans aucune passerelle vers l'internet. L'un des deux hôtes est déjà démarré et configuré en IP v6. Il dispose d'un « sniffeur » (l'incontournable Wireshark).
L'objectif est de contrôler ce qu'il se passe lorsque le second hôte est mis en service. Cet hôte dispose d'une interface dont l'adresse MAC est :
00:0d:88:37:73:e9Voyons d'abord l'ensemble des trames capturées :
No. Time Source Destination Protocol Info
1 0.000000 :: ff02::1:ff37:73e9 ICMPv6 Neighbor solicitation
2 0.999924 fe80::20d:88ff:fe37:73e9 ff02::2 ICMPv6 Router solicitation
3 4.999740 fe80::20d:88ff:fe37:73e9 ff02::2 ICMPv6 Router solicitation
4 8.999580 fe80::20d:88ff:fe37:73e9 ff02::2 ICMPv6 Router solicitationIl y a plusieurs choses Ă dire ici.
5-1. Neighbor solicitation▲
L'hôte qui démarre cherche à autoconfigurer son lien local, en utilisant le principe vu plus haut. Il va donc préalablement s'assurer que l'adresse IP qu'il compte exploiter n'est pas déjà utilisée.
Pour ce faire, il exploite une nouvelle fonctionnalité d'ICMP qui est appelée « Neighbor discovery » (Découverte du voisinage).
- L'adresse source est ici non spécifiée (::, à rapprocher en IP v4 de l'adresse 0.0.0.0) ;
- l'adresse de destination est intéressante : ff02::1:ff37:73e9. Il s'agit d'une adresse de diffusion (multicast) dont nous étudierons le détail plus loin.
Il n'y a pas de réponse à ce message, ce qui veut dire que l'adresse convoitée n'est pas en usage sur le lien local. Notre hôte adopte donc l'adresse :
fe80::20d:88ff:fe37:73e9construite comme nous l'avons vu plus haut.
Viennent ensuite trois messages de type « Router solicitation » (découverte de routeurs) qui restent sans réponse, ce qui est rassurant, puisqu'il n'y en a pas sur notre réseau embryonnaire.
Voyons plus en détail la première trame :
Frame 1 (78 bytes on wire, 78 bytes captured)
...
Ethernet II, Src: D-Link_37:73:e9 (00:0d:88:37:73:e9), Dst: IPv6-Neighbor-Discovery_ff:37:73:e9 (33:33:ff:37:73:e9)
Destination: IPv6-Neighbor-Discovery_ff:37:73:e9 (33:33:ff:37:73:e9)
Address: IPv6-Neighbor-Discovery_ff:37:73:e9 (33:33:ff:37:73:e9)
.... ...1 .... .... .... .... = IG bit: Group address (multicast/broadcast)
.... ..1. .... .... .... .... = LG bit: Locally administered address (this is NOT the factory default)
Source: D-Link_37:73:e9 (00:0d:88:37:73:e9)
Address: D-Link_37:73:e9 (00:0d:88:37:73:e9)
.... ...0 .... .... .... .... = IG bit: Individual address (unicast)
.... ..0. .... .... .... .... = LG bit: Globally unique address (factory default)
Type: IPv6 (0x86dd)
Internet Protocol Version 6
0110 .... = Version: 6
.... 0000 0000 .... .... .... .... .... = Traffic class: 0x00000000
.... .... .... 0000 0000 0000 0000 0000 = Flowlabel: 0x00000000
Payload length: 24
Next header: ICMPv6 (0x3a)
Hop limit: 255
Source: :: (::)
Destination: ff02::1:ff37:73e9 (ff02::1:ff37:73e9)
Internet Control Message Protocol v6
Type: 135 (Neighbor solicitation)
Code: 0
Checksum: 0x0ad9 [correct]
Target: fe80::20d:88ff:fe37:73e9 (fe80::20d:88ff:fe37:73e9)La source (l'hĂ´te qui cherche Ă s'autoconfigurer avec l'IPv6 fe80::20d:88ff:fe37:73e9) dispose de l'adresse MAC 00:0d:88:37:73:e9 et envoie un message ICMP de type: 135 (Neighbor solicitation) sur une adresse de broadcast IPv6 ff02::1:ff37:73e9, ce qui correspond Ă une adresse MAC multicast de la forme 33:33:ff:37:73:e9.
Si d'aventure, un autre hôte disposait d'une adresse MAC dont les trois derniers octets seraient 37:73:e9, ce dernier répondrait à la sollicitation en envoyant son adresse IPv6 ainsi que son adresse MAC complète. Dans le cas où l'adresse IPv6 serait identique à celle convoitée par notre poste qui démarre, il y aurait alors conflit et l'autoconfiguration ne pourrait se faire.
5-2. Neighbor advertisement▲
Vous aimeriez ben savoir ce qu'il se passerait si, par un hasard extraordinaire, l'adresse construite à partir de l'adresse MAC était déjà en service sur le lien ? Rien de plus simple ! Faisons la manip. Nous allons exploiter la possibilité du multiadressage d'un nœud pour attribuer à la machine « espion » l'adresse convoitée par le nouvel arrivant.
Sur la machine munie du « Wireshark » (la commande « ip -6 » fonctionne avec IP v6 exactement comme la commande « ip » le fait avec IP v4) :
# ip -6 addr add fe80::20d:88ff:fe37:73e9/64 dev eth0Vérification :
# ifconfig eth0
eth0 Lien encap:Ethernet HWaddr 00:10:B5:40:B7:04
adr inet6: fe80::210:b5ff:fe40:b704/64 Scope:Lien
adr inet6: fe80::20d:88ff:fe37:73e9/64 Scope:Lien
...Voyons maintenant le démarrage de notre cobaye :
No. Time Source Destination Protocol Info
1 0.000000 :: ff02::1:ff37:73e9 ICMPv6 Neighbor solicitation
2 0.000077 fe80::20d:88ff:fe37:73e9 ff02::1 ICMPv6 Neighbor advertisementSi la première trame est identique au cas précédent, nous observons ici une réponse « Neighbor advertisement » de fe80::20d:88ff:fe37:73e9 (l'adresse que nous avons manuellement ajoutée à notre espion). Le processus s'arrête là , il n'y a pas de découverte de routeurs et pour cause, notre cobaye n'a pu autoconfigurer son interface.
Voyons le détail de la trame 2 :
Frame 2 (86 bytes on wire, 86 bytes captured)
...
Ethernet II, Src: AcctonTe_40:b7:04 (00:10:b5:40:b7:04), Dst: IPv6-Neighbor-Discovery_00:00:00:01 (33:33:00:00:00:01)
Destination: IPv6-Neighbor-Discovery_00:00:00:01 (33:33:00:00:00:01)
Address: IPv6-Neighbor-Discovery_00:00:00:01 (33:33:00:00:00:01)
.... ...1 .... .... .... .... = IG bit: Group address (multicast/broadcast)
.... ..1. .... .... .... .... = LG bit: Locally administered address (this is NOT the factory default)
Source: AcctonTe_40:b7:04 (00:10:b5:40:b7:04)
Address: AcctonTe_40:b7:04 (00:10:b5:40:b7:04)
.... ...0 .... .... .... .... = IG bit: Individual address (unicast)
.... ..0. .... .... .... .... = LG bit: Globally unique address (factory default)
Type: IPv6 (0x86dd)
Internet Protocol Version 6
0110 .... = Version: 6
.... 0000 0000 .... .... .... .... .... = Traffic class: 0x00000000
.... .... .... 0000 0000 0000 0000 0000 = Flowlabel: 0x00000000
Payload length: 32
Next header: ICMPv6 (0x3a)
Hop limit: 255
Source: fe80::20d:88ff:fe37:73e9 (fe80::20d:88ff:fe37:73e9)
Destination: ff02::1 (ff02::1)
Internet Control Message Protocol v6
Type: 136 (Neighbor advertisement)
Code: 0
Checksum: 0x72ec [correct]
Flags: 0xa0000000
1... .... .... .... .... .... .... .... = Router
.0.. .... .... .... .... .... .... .... = Not adverted
..1. .... .... .... .... .... .... .... = Override
Target: fe80::20d:88ff:fe37:73e9 (fe80::20d:88ff:fe37:73e9)
ICMPv6 Option (Target link-layer address)
Type: Target link-layer address (2)
Length: 8
Link-layer address: 00:10:b5:40:b7:04Notre espion signale par un message ICMP de type 136 que l'adresse IPv6 fe80::20d:88ff:fe37:73e9 est attachée à l'interface dont l'adresse MAC est 00:10:b5:40:b7:04. Ce message est envoyé à tous les hôtes du réseau (ff02::1, ce qui correspond à l'adresse MAC multicast 33:33:00:00:00:01). Notre postulant à l'adresse IPv6 fe80::20d:88ff:fe37:73e9 en est donc informé.
Voyons l'état de la configuration IP v6 du cobaye :
2: eth0: mtu 1500 qlen 1000
inet6 fe80::20d:88ff:fe37:73e9/64 scope link tentative
valid_lft forever preferred_lft foreverLe « scope link » que nous observions tout à l'heure s'est transformé en « scope link tentative ». Autrement dit, cette adresse ne sera pas exploitable, l'hôte n'est pas configuré.
Moralité : en cas de duplication d'adresse, le processus d'autoconfiguration montre ses limites. Dans un tel cas, nous devrons résoudre manuellement le conflit.
Notez aussi au passage que tout ceci ressemble furieusement Ă ce que fait ARP en IPv4. Mais ici, c'est de l'ICMP.
5-3. Avec deux interfaces▲
A priori, il n'y a pas de problèmes, dans la mesure où la construction de l'adresse se fait à partir de l'adresse MAC. Nous devrions trouver deux adresses IPv6 différentes :
eth0 Link encap:Ethernet HWaddr 00:10:b5:40:b7:04
adr inet6: fe80::210:b5ff:fe40:b704/64 Scope:Lien
...
eth1 Link encap:Ethernet HWaddr 00:0c:6e:63:e6:ed
inet adr:192.168.10.30 Bcast:192.168.10.255 Masque:255.255.255.0
adr inet6: fe80::20c:6eff:fe63:e6ed/64 Scope:Lien
...C'est bien, c'est comme on avait prévu :-)
5-4. Et les routes ?▲
Il y a plusieurs façons d'afficher les routes IPv6, dont la classique commande « route », avec quelques aménagements :
~# route -A inet6
Table de routage IPv6 du noyau
Destination Next Hop Flag Met Ref Use If
::1/128 :: Un 0 1 4 lo
fe80::/128 :: Un 0 2 0 lo
fe80::/128 :: Un 0 2 0 lo
fe80::20c:6eff:fe63:e6ed/128 :: Un 0 1 0 lo
fe80::210:b5ff:fe40:b704/128 :: Un 0 1 0 lo
fe80::/64 :: U 256 0 0 eth1
fe80::/64 :: U 256 0 0 eth0
ff00::/8 :: U 256 0 0 eth1
ff00::/8 :: U 256 0 0 eth0
::/0 :: !n -1 1 1 loPour l'instant, contentons-nous de noter ceci : la route pour fe080::/64 peut passer aussi bien par eth0 que par eth1…
5-5. Un petit ping…▲
Nous avons sur un même lien local deux nœuds autoconfigurés en IPv6 :
- l'un dispose de l'adresse fe80::20c:6eff:fe63:e6ed ;
- l'autre de l'adresse fe80::21b:11ff:fe52:bfab (sur eth0).
Depuis ce dernier nœud, nous tentons un ping (ipv6) sur fe80::20c:6eff:fe63:e6ed :
~$ ping6 -c4 fe80::20c:6eff:fe63:e6ed
connect: Invalid argumentPourquoi tant de haine ?
Vous pensez bien que la remarque préalable sur les routes n'a pas été faite par hasard. Avec les adresses de type lien local, il faut préciser sur quelle interface nous désirons travailler. La commande ping6 propose diverses syntaxes. La plus courte est sans doute :
ping 6 <adresse de la cible>%ethxVoyons ceci :
:~$ ping6 -c4 fe80::20c:6eff:fe63:e6ed%eth0
PING fe80::20c:6eff:fe63:e6ed%eth0(fe80::20c:6eff:fe63:e6ed) 56 data bytes
64 bytes from fe80::20c:6eff:fe63:e6ed: icmp_seq=1 ttl=64 time=3.54 ms
64 bytes from fe80::20c:6eff:fe63:e6ed: icmp_seq=2 ttl=64 time=0.121 ms
64 bytes from fe80::20c:6eff:fe63:e6ed: icmp_seq=3 ttl=64 time=0.123 ms
64 bytes from fe80::20c:6eff:fe63:e6ed: icmp_seq=4 ttl=64 time=0.120 ms
--- fe80::20c:6eff:fe63:e6ed%eth0 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3002ms
rtt min/avg/max/mdev = 0.120/0.976/3.543/1.482 msNettement plus efficace. Nous verrons plus loin que cette limitation n'intervient pas avec des adresses de type global.
6. Hello World▲
Fort de ces quelques observations, nous allons maintenant connecter une station directement sur notre Freebox, configurée pour fonctionner en IPv6.
6-1. Configuration▲
Cette machine, une Debian « lenny » (testing, à l'heure où ces lignes sont écrites), dispose d'une interface eth0 configurée en IPv4 DHCP. Nous aurons donc aussi une connectivité IPv4, ce qui pour l'instant est nécessaire, si nous voulons accéder à la plupart des ressources de l'internet. En effet, peu de sites proposent actuellement une connectivité IPv6.
Nous démarrons cette machine et :
~# ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:1b:11:52:bf:ab
inet adr:82.243.80.13 Bcast:82.243.80.255 Masque:255.255.255.0
adr inet6: 2a01:5d8:52f3:500d:21b:11ff:fe52:bfab/64 Scope:Global
adr inet6: fe80::21b:11ff:fe52:bfab/64 Scope:Lien
...Nous observons deux adresses IPv6Â :
- fe80::21b:11ff:fe52:bfab/64 qui correspond au lien local, comme nous l'avons vu ;
- 2a01:5d8:52f3:500d:21b:11ff:fe52:bfab/64 qui est une adresse globale, fournie par notre opérateur.
6-2. Anatomie de l'adresse « globale »▲
Déjà , nous pouvons observer que le jeton (partie représentative du nœud) est le même pour les adresses globales et lien local. C'est normal, elles sont toutes les deux autoconfigurées de la même manière.
6-2-1. Adresse de Free autoconfigurĂ©e ?▲
Oui, vous ne rêvez pas, en IPv6 Free vous octroie 264 adresses publiques. Votre réseau « local » sera donc entièrement intégré à l'internet (avec tous les risques que cela comprend). Plus besoin de NAT, donc. Lorsque notre télévision, notre réfrigérateur, notre lave-linge, notre lave-vaisselle, notre four à chaleur tournante, notre congélateur, etc. seront connectés à l'internet, ce qui nous permettra, via notre téléphone/pda/baladeur-mp3 de recevoir toutes les alertes électroménagères où que nous soyons dans le vaste monde, nous n'aurons pas de problèmes de pénurie d'adresses IP.
En fait, en IPv6, votre fournisseur ne vous procurera non plus une adresse IP, mais un bloc d'adresses IP. Actuellement au moins un /64, pour permettre l'autoconfiguration. Autrement dit, votre fournisseur vous alloue un préfixe.
En IPv4, en revanche, vous ne disposerez toujours que d'une seule adresse IP publique, bien sûr.
6-2-2. Le prĂ©fixe Free▲
Dans l'exemple, ce préfixe est :
2a01:5d8:52f3:500d::/64Il est construit de la manière suivante :
- 2a01:5d8::/32 qui est un préfixe fourni à Free pour l'ensemble de ses besoins ;
- les 32 bits suivants ne sont rien d'autre que votre adresse IPv4. Ici 52f3:500d peut s'écrire en hexadécimal 0x52.0xf3.0x50.0x0d, ce qui donne 82.243.80.13 en décimal, conformément à ce qui a été observé plus haut avec la commande ifconfig.
Au final le préfixe que Free vous alloue est entièrement à votre usage, exception faite d'une adresse particulière qui, comme nous le verrons plus bas, est celle de la passerelle par défaut. Il en faut aussi une en IPv6, bien entendu. Cette adresse est conventionnellement : <votre préfixe>::1. Ainsi, dans l'exemple, ce sera 2a01:5d8:52f3:500d::1.
~$ ping6 -c 4 2a01:5d8:52f3:500d::1
PING 2a01:5d8:52f3:500d::1(2a01:5d8:52f3:500d::1) 56 data bytes
64 bytes from 2a01:5d8:52f3:500d::1: icmp_seq=1 ttl=64 time=6.38 ms
64 bytes from 2a01:5d8:52f3:500d::1: icmp_seq=2 ttl=64 time=0.666 ms
64 bytes from 2a01:5d8:52f3:500d::1: icmp_seq=3 ttl=64 time=0.657 ms
64 bytes from 2a01:5d8:52f3:500d::1: icmp_seq=4 ttl=64 time=0.662 ms
--- 2a01:5d8:52f3:500d::1 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3000ms
rtt min/avg/max/mdev = 0.657/2.092/6.386/2.479 msAh tiens, nous n'avons pas eu besoin ici de spécifier le nom de l'interface dans la commande ping ?
Non, car la table des routes dit :
~$ route -A inet6
Table de routage IPv6 du noyau
Destination Next Hop Flag Met Ref Use If
::1/128 :: Un 0 1 25 lo
2a01:5d8:52f3:500d:21b:11ff:fe52:bfab/128 :: Un 0 1 3080 lo
2a01:5d8:52f3:500d::/64 :: UAe 256 0 17 eth0
fe80::21b:11ff:fe52:bfab/128 :: Un 0 1 10 lo
fe80::/64 :: U 256 0 0 eth0
ff00::/8 :: U 256 0 0 eth0
::/0 fe80::207:cbff:fe1f:f5a UGDAe 1024 0 1 eth0
::/0 :: !n -1 1 1 loIl n'y a donc aucune ambiguïté sur le chemin à prendre.
Notons, puisque nous y sommes, la route par défaut :
::/0 fe80::207:cbff:fe1f:f5a UGDAe 1024 0 1 eth0oĂą l'adresse IP de la passerelle est une adresse de type lien local.
6-3. Et ARP dans tout ça ?▲
Nous l'avons déjà dit, ARP n'existe plus, mais la pile IPv6 doit tout de même conserver une table d'équivalence entre adresses IPv6 et adresses MAC.
La commande arp en version 6 n'existe pas, mais la commande ip permet d'afficher le voisinage, aussi bien en IPv4 qu'en IPv6.
~# ping6 -c 1 fe80::207:cbff:fe1f:f5a%eth0
PING fe80::207:cbff:fe1f:f5a%eth0(fe80::207:cbff:fe1f:f5a) 56 data bytes
64 bytes from fe80::207:cbff:fe1f:f5a: icmp_seq=1 ttl=64 time=1.55 ms
--- fe80::207:cbff:fe1f:f5a%eth0 ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 1.557/1.557/1.557/0.000 ms
~# ip -6 neigh show dev eth0
fe80::207:cbff:fe1f:f5a lladdr 00:07:cb:1f:0f:5a router REACHABLENotre passerelle par défaut dispose d'une adresse lien local autoconfigurée, son adresse MAC est 00:07:cb:1f:0f:5a. Profitons de l'occasion pour vérifier que l'adresse globale 2a01:5d8:52f3:500d::1 correspond bien à notre passerelle par défaut.
Un ping sur cette adresse :
~# ping6 -c 1 2a01:5d8:52f3:500d::1
PING 2a01:5d8:52f3:500d::1(2a01:5d8:52f3:500d::1) 56 data bytes
64 bytes from 2a01:5d8:52f3:500d::1: icmp_seq=1 ttl=64 time=5.39 ms
...Un ping sur l'adresse lien local de la passerelle :
~$ ping6 -c 1 fe80::207:cbff:fe1f:f5a%eth0
PING fe80::207:cbff:fe1f:f5a%eth0(fe80::207:cbff:fe1f:f5a) 56 data bytes
64 bytes from fe80::207:cbff:fe1f:f5a: icmp_seq=1 ttl=64 time=0.646 ms
...Enfin, nous affichons le voisinage :
~$ ip -6 neigh show dev eth0
fe80::207:cbff:fe1f:f5a lladdr 00:07:cb:1f:0f:5a router REACHABLE
2a01:5d8:52f3:500d::1 lladdr 00:07:cb:1f:0f:5a router REACHABLELa même adresse MAC 00:07:cb:1f:0f:5a correspond bien aux deux adresses IPv6. À titre purement informatif, faisons quelque chose d'équivalent en IPv4 :
~# route -n
Table de routage IP du noyau
Destination Passerelle Genmask Indic Metric Ref Use Iface
82.243.80.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
0.0.0.0 82.243.80.254 0.0.0.0 UG 0 0 0 eth0
~# ping -c 1 82.243.80.254
PING 82.243.80.254 (82.243.80.254) 56(84) bytes of data.
64 bytes from 82.243.80.254: icmp_seq=1 ttl=64 time=36.8 ms
...
~# arp -an
? (82.243.80.254) at 00:07:CB:1F:0F:5A [ether] on eth0Nous remarquons que, en IPv4 comme en IPv6, l'adresse MAC de la passerelle par défaut est toujours la même
7. DNS, DHCPÂ ???▲
Nous sommes déjà assez rompus aux protocoles de l'internet. Même si nous ne les manipulons qu'au travers d'IPv4, nous ne sommes plus des « newbies », nous savons que la configuration IP n'est pas miraculeuse, que nous avons besoin, en plus d'une adresse IP, de quelques renseignements supplémentaires pour pouvoir exploiter les ressources de l'internet :
- une adresse de passerelle par défaut ;
- au moins une adresse de DNS pour résoudre les noms en adresses IP.
Avec IPv4, ces informations nous sont communiquées par le fournisseur d'accès de façon automatique. Par DHCP si le processus de connexion est assimilé à une connexion sur un réseau local (cas de Free), ou par PPP(oE) lors de l'identification RADIUS. Mais qu'en est-il en IPv6 ?
7-1. DHCP▲
Il existe bien un RFC décrivant un protocole DHCPv6, mais il reste pour l'heure (où ces lignes sont écrites) expérimental. Nous avons vu que le mécanisme d'autoconfiguration était privilégié pour l'obtention de son adresse IP. Ici, donc, foin de DHCP. Mais alors, comment notre machine a-t-elle fait pour découvrir l'adresse de la passerelle par défaut ? Car nous avons vu sur la page précédente que cette adresse était bien connue.
Autoconfiguration, soit. Mais comment notre système fait-il pour connaître le préfixe que nous attribue notre fournisseur d'accès ?
7-2. DNS▲
Disposons-nous d'une adresse de DNS IPv6Â ? Et d'abord, comment fonctionne DNS en IPv6Â ?
7-2-1. RĂ©solution des noms▲
Il y a déjà longtemps que les DNS (Bind en particulier) savent diffuser à leurs clients aussi bien des adresses IPv4 que des adresses IPv6, pour un nom d'hôte donné. Exemple :
~# host www.kame.net
www.kame.net has address 203.178.141.194
www.kame.net has IPv6 address 2001:200:0:8002:203:47ff:fea5:3085Pour ne pas trop vous donner le vertige, n'entrons pas de suite dans les détails de la manip. Disons simplement pour l'instant qu'il est possible de :
- demander Ă un DNS l'adresse IPv6 d'un hĂ´te en l'interrogeant sur son IPv4Â ;
- demander à un DNS l'adresse IPv4 d'un hôte en l'interrogeant sur son adresse IPv6 (si le DNS dispose d'une adresse IPv6 bien sûr).
En réalité, un DNS dispose :
- du champ « A » pour enregistrer l'IPv4 correspondant à un nom d'hôte ;
- du champ « AAAA » pour enregistrer l'IPv6 correspondant à un nom d'hôte.
Si le DNS en question dispose d'une adresse IPv4 et d'une adresse IPv6, les clients pourront l'interroger en IPv4 comme en IPv6 pour obtenir le champ A comme le champ AAAA pour un hôte donné.
Autrement dit, un DNS est capable de fournir des adresses IPv4 comme IPv6 pourvu qu'il les connaisse et ce, qu'il soit interrogé aussi bien par une requête IPv4 qu'une requête IPv6.
7-2-2. Les DNS de Free▲
Comment connaître les adresses IP (v4 comme v6) des DNS que Free met à la disposition de ses clients ?
Les adresses IPv4 sont assez simples à retrouver, puisqu'elles figurent dans les informations fournies par DHCP, que nous trouvons sur notre Debian dans /var/lib/dhcp/dhclient.eth0.leases :
lease {
interface "eth0";
...
option domain-name-servers 212.27.54.252,212.27.53.252;
...
}Nous avons donc deux DNS identifiés par leur IPv4 :
- 212.27.54.252Â ;
- 212.27.53.252.
Les adresses IPv6 sont elles aussi assez simples à trouver si l'on sait comment faire, mais pour l'instant, nous ne savons pas encore. Il vous faudra donc vous contenter de me croire sur parole :
- 2a01:5d8:e0ff::2Â ;
- 2a01:5d8:e0ff::1.
Nous allons interroger ces DNS en mode IPv4 et en mode IPv6 à propos de www.kame.net et comparer les résultats :
~$ host -4 www.kame.net 212.27.54.252
Using domain server:
Name: 212.27.54.252
Address: 212.27.54.252#53
Aliases:
www.kame.net has address 203.178.141.194
www.kame.net has IPv6 address 2001:200:0:8002:203:47ff:fea5:3085~$ host -6 www.kame.net 2a01:5d8:e0ff::2
Using domain server:
Name: 2a01:5d8:e0ff::2
Address: 2a01:5d8:e0ff::2#53
Aliases:
www.kame.net has address 203.178.141.194
www.kame.net has IPv6 address 2001:200:0:8002:203:47ff:fea5:3085Quel que soit le serveur interrogé, en mode IPv4 comme en mode IPv6, nous obtenons bien les adresses IPv4 et IPv6 de la cible.
Bon. Mais comment notre système fait-il pour connaître la ou les adresses de DNS que notre fournisseur nous procure ?
7-3. Ă€ la dĂ©couverte du monde IPv6▲
Il existe une trousse à outils nommée ndisc6 (IPv6 diagnostic tools for Linux and BSD), facile à installer sur Debian, Ubuntu et dérivées par un aptitude install ndisc6. Bien entendu, les autres distributions récentes proposent également cette trousse, qui contient quatre outils de base.
Dans un premier temps, nous nous contenterons d'utiliser ces outils, sans trop savoir comment ils fonctionnent, juste pour voir les informations que l'on peut en tirer.
7-3-1. ndisc6▲
Permet de lancer une « découverte des voisins ». Comparable à la commande arping du monde IPv4. Utilisons cet outil pour scruter notre passerelle par défaut. Commençons par son adresse de type lien local, telle que nous l'avons découverte avec la commande route -A inet6 :
:~$ ndisc6 fe80::207:cbff:fe1f:f5a eth0
Solicitation de fe80::207:cbff:fe1f:f5a (fe80::207:cbff:fe1f:f5a) sur eth0...
Adresse cible de lien : 00:07:CB:1F:0F:5A
de fe80::207:cbff:fe1f:f5a~$ ndisc6 2a01:5d8:52f3:500d::1 eth0
Solicitation de 2a01:5d8:52f3:500d::1 (2a01:5d8:52f3:500d::1) sur eth0...
Adresse cible de lien : 00:07:CB:1F:0F:5A
de 2a01:5d8:52f3:500d::1Ne nous Ă©ternisons pas sur cet outil qui pour l'instant ne nous apprend rien de bien nouveau. En gros, un ping6 suivi d'un ip -6 neigh show nous en apprend tout autant.
7-3-2. rdisc6▲
Cet outil est magique. Voyons tout de suite ce qu'il est capable de nous apprendre :
~$ rdisc6 eth0
Solicitation de ff02::2 (ff02::2) sur eth0...
Limite de saut (TTL) : 64 ( 0x40)
Conf. d'adresse par DHCP : Non
Autres réglages par DHCP : Non
Préférence du routeur : moyen
Durée de vie du routeur : 1800 (0x00000708) secondes
Temps d'atteinte : non indiqué (0x00000000)
Temps de retransmission : non indiqué (0x00000000)
Préfixe : 2a01:5d8:52f3:500d::/64
Durée de validité : 86400 (0x00015180) secondes
Durée de préférence : 86400 (0x00015180) secondes
Recursive DNS server : 2a01:5d8:e0ff::2
Recursive DNS server : 2a01:5d8:e0ff::1
DNS servers lifetime : 600 (0x00000258) secondes
MTU : 1480 octets (valide)
Adresse source de lien : 00:07:CB:1F:0F:5A
de fe80::207:cbff:fe1f:f5aLà , nous sommes servis. Nous apprenons que :
- il n'y a pas de DHCP dans le coup ;
- le préfixe qui nous est attribué est bien 2a01:5d8:52f3:500d::/64 ;
- les durées de validité et de préférence sont identiques et de 86 400 secondes (24 heures) ;
- les DNS proposés sont 2a01:5d8:e0ff::2 et 2a01:5d8:e0ff::1 ;
- le routeur (passerelle par défaut) est fe80::207:cbff:fe1f:f5a.
Nous sentons bien ici qu'il faudra approfondir cette question. Nous avons récupéré toutes les informations nécessaires, comme nous l'aurions fait en IPv4 par DHCP, mais ici, ce n'est pas DHCP. Alors, qu'est-ce que c'est ?
De plus, que représente cette adresse ff02::2 qui semble être la source de toutes ces informations ?
7-3-3. tcptraceroute6▲
Comme son nom l'indique, cette commande est Ă©quivalente au tcptraceroute du monde IPv4Â :
:~$ tcptraceroute6 www.kame.net
traceroute vers orange.kame.net (2001:200:0:8002:203:47ff:fea5:3085) de 2a01:5d8:52f3:500d:21b:11ff:fe52:bfab, port 80, du port 56328, 30 sauts max, 60 octet/paquet
1 2a01:5d8:52f3:500d::1 (2a01:5d8:52f3:500d::1) 0.586 ms 0.493 ms 0.514 ms
2 2a01:5d8:e000:9d1::4 (2a01:5d8:e000:9d1::4) 48.728 ms 48.941 ms 48.161 ms
3 2a01:5d8:e000:9d1::fe (2a01:5d8:e000:9d1::fe) 50.412 ms 49.901 ms *
...
22 lo0.alaxala1.k2.wide.ad.jp (2001:200:0:4800::7800:1) 342.425 ms 342.790 ms 339.848 ms
23 orange.kame.net (2001:200:0:8002:203:47ff:fea5:3085) 343.017 ms [ouvert] 342.494 ms 338.770 msComme vous le constatez, il n'y a rien de fondamentalement nouveau, si ce n'est que nous Ă©voluons dans un monde IPv6.
- le « hop » 1 nous confirme une fois encore l'adresse IP (globale) de notre passerelle par défaut ;
- le « hop » 22 nous apprend que la cible www.kame.net se situe au Japon et que son port 80 est ouvert.
7-3-4. traceroute6▲
Nous n'allons pas nous intéresser à cette commande, qui est équivalente au traceroute du monde IPv4 et qui ne nous apprendra rien de plus ici.
8. Les questions▲
Le lecteur attentif aura pu constater que cette page pose beaucoup de questions, mais n'apporte guère de réponses sur les mécanismes mis en œuvre, signe évident qu'il y a encore de la lecture en perspective…
Si nous avons appris qu'il existe un mécanisme qui remplace DHCP, nous ne savons toujours pas exactement lequel. Ami lecteur, ne rate surtout pas la page suivante, qui va enfin commencer à répondre à ces questions.
9. ICMPv6, multicast, ndp…▲
9-1. ICMPv6▲
Ce protocole, qui ressemble beaucoup à l'ICMP du monde IPv4, a été enrichi de nouveaux messages, c'est lui qui sert à véhiculer les informations de configuration, dans le cas qui nous intéresse. En effet, nous n'allons maintenant plus tarder à voir que ce sont des messages ICMP qui contiennent les questions et les réponses que nous avons obtenues avec l'outil rdisc6, exactement de la même manière que lors du démarrage de la pile IPv6 sur une interface réseau.
9-2. Multicast▲
IPv6 cherche par tous les moyens à éviter la diffusion (broadcast), en préférant adopter des solutions « multicast ». Nous allons découvrir que certaines adresses multicast sont définies pour répondre à des requêtes bien précises, et que les équipements du réseau qui sont censés disposer des réponses à ces requêtes écoutent sur ces adresses multicast.
Ainsi :
- ff02::2 est une adresse multicast destinée à recevoir des requêtes du type « router discovery (Sollicitation d'un routeur) ». Tous les routeurs accessibles dans le voisinage le seront par cette adresse multicast. C'est ce que fait notre commande rdisc6 sur la page précédente ;
- ff02::1 est une autre adresse multicast, qui sert dans l'autre sens. Toutes les stations d'un réseau doivent être capables d'écouter sur cette adresse ce que les routeurs ont à leur dire.
9-3. NDP▲
« Neighbor Discovery Protocol (découverte des voisins) ». Ce protocole permet aux nœuds d'un réseau de découvrir leur voisinage. Pour ce qui nous intéresse principalement ici, c'est grâce à lui qu'une station qui démarre découvre les routeurs qui lui sont accessibles et que ceux-ci lui communiquent les paramètres nécessaires à sa configuration IPv6. Car vous l'avez deviné, ce sont les routeurs qui transmettent ces informations que nous avons mises en évidence grâce à rdisc6.
NDP utilise des messages ICMPv6 et les adresses multicast ff02::1 et ff02::2.
9-3-1. Capture du protocole▲
Nous allons lancer notre wireshark favori à l'écoute d'ICMPv6 sur eth0 et refaire un rdisc6 eth0 pour voir…
No. Time Source Destination Protocol Info
1 0.000000 fe80::21b:11ff:fe52:bfab ff02::2 ICMPv6 Router solicitation
2 0.004925 fe80::207:cbff:fe1f:f5a ff02::1 ICMPv6 Router advertisement- Notre station (fe80::21b:11ff:fe52:bfab) envoie un « Router solicitation (sollicitation de routeurs) » sur l'adresse multicast ff02::2 ;
- Notre routeur (fe80::207:cbff:fe1f:f5a, la passerelle par défaut) répond un « Router advertisement (annonce de routeur) » sur l'adresse multicast ff02::1.
9-3-2. Analyse de l'Ă©change▲
9-3-2-1. La question▲
Elle est assez simple, nous allons tronquer un peu le détail, pour ne garder que ce qu'il y a de plus intéressant :
Frame 1 (62 bytes on wire, 62 bytes captured)
...
Ethernet II, Src: 00:1b:11:52:bf:ab (00:1b:11:52:bf:ab), Dst: 33:33:00:00:00:02 (33:33:00:00:00:02)
Destination: 33:33:00:00:00:02 (33:33:00:00:00:02)
Address: 33:33:00:00:00:02 (33:33:00:00:00:02)
.... ...1 .... .... .... .... = IG bit: Group address (multicast/broadcast)
.... ..1. .... .... .... .... = LG bit: Locally administered address (this is NOT the factory default)
Source: 00:1b:11:52:bf:ab (00:1b:11:52:bf:ab)
Address: 00:1b:11:52:bf:ab (00:1b:11:52:bf:ab)
.... ...0 .... .... .... .... = IG bit: Individual address (unicast)
.... ..0. .... .... .... .... = LG bit: Globally unique address (factory default)
Type: IPv6 (0x86dd)
Internet Protocol Version 6
...
Source: fe80::21b:11ff:fe52:bfab (fe80::21b:11ff:fe52:bfab)
Destination: ff02::2 (ff02::2)
Internet Control Message Protocol v6
Type: 133 (Router solicitation)
Code: 0
Checksum: 0xab1e [correct]Notez, sur la couche Ethernet, les adresses multicast utilisées.
Pour le reste, nous découvrons bien sur ICMPv6 un message de type 133 (Router solicitation).
9-3-2-2. La rĂ©ponse▲
Ça va être un peu plus copieux ici.
Frame 2 (158 bytes on wire, 158 bytes captured)
...
Ethernet II, Src: 00:07:cb:1f:0f:5a (00:07:cb:1f:0f:5a), Dst: 33:33:00:00:00:01 (33:33:00:00:00:01)
Destination: 33:33:00:00:00:01 (33:33:00:00:00:01)
Address: 33:33:00:00:00:01 (33:33:00:00:00:01)
.... ...1 .... .... .... .... = IG bit: Group address (multicast/broadcast)
.... ..1. .... .... .... .... = LG bit: Locally administered address (this is NOT the factory default)
Source: 00:07:cb:1f:0f:5a (00:07:cb:1f:0f:5a)
Address: 00:07:cb:1f:0f:5a (00:07:cb:1f:0f:5a)
.... ...0 .... .... .... .... = IG bit: Individual address (unicast)
.... ..0. .... .... .... .... = LG bit: Globally unique address (factory default)
Type: IPv6 (0x86dd)
Internet Protocol Version 6
...
Source: fe80::207:cbff:fe1f:f5a (fe80::207:cbff:fe1f:f5a)
Destination: ff02::1 (ff02::1)
Internet Control Message Protocol v6
Type: 134 (Router advertisement)
Code: 0
Checksum: 0xfc50 [correct]
Cur hop limit: 64
Flags: 0x00
0... .... = Not managed
.0.. .... = Not other
..0. .... = Not Home Agent
...0 0... = Router preference: Medium
Router lifetime: 1800
Reachable time: 0
Retrans timer: 0
ICMPv6 Option (Prefix information)
Type: Prefix information (3)
Length: 32
Prefix length: 64
Flags: 0xc0
1... .... = Onlink
.1.. .... = Auto
..0. .... = Not router address
...0 .... = Not site prefix
Valid lifetime: 86400
Preferred lifetime: 86400
Prefix: 2a01:5d8:52f3:500d::
ICMPv6 Option (Recursive DNS Server)
Type: Recursive DNS Server (25)
Length: 40
Reserved
Lifetime: 600
Recursive DNS Servers: 2a01:5d8:e0ff::2 (2a01:5d8:e0ff::2)
Recursive DNS Servers: 2a01:5d8:e0ff::1 (2a01:5d8:e0ff::1)
ICMPv6 Option (MTU)
Type: MTU (5)
Length: 8
MTU: 1480
ICMPv6 Option (Source link-layer address)
Type: Source link-layer address (1)
Length: 8
Link-layer address: 00:07:cb:1f:0f:5aTout est dit dans un seul paquet ICMP. Notez que ce message « Neighbor advertisement » est périodiquement émis par les routeurs, même s'il n'a pas été sollicité par un nœud du réseau, ce qui permet si nécessaire de reconfigurer dynamiquement les hôtes.
10. IPv6 global sur son LAN▲
Tout ceci est bien amusant, mais comment exploiter au mieux ce monde IPv6 sur son LAN, car IPv6 ne se suffit pas à lui-même pour l'instant. Les ressources IPv6 sont encore rares sur le vaste internet, et l'usage d'IPv4 est encore le plus souvent nécessaire.
- Comment les choses peuvent-elles se passer si l'on fait cohabiter sur le mĂŞme hĂ´te une pile IPv4 et une pile IPv6Â ?
- Je n'ai qu'une IPv4 publique et 264 IPv6 globales. Comment gérer ça sur mon LAN ?
- Je voudrais bien utiliser l'autoconfiguration. Je n'ai donc pas besoin de DHCPv6Â ?
- Mais si j'ai bien compris, il faut 64 bits pour le jeton si je veux faire de l'autoconfiguration. Comme le préfixe fourni par Free est un préfixe de 64 bits, 64+64=128, je ne peux donc pas créer de sous-réseaux, malgré mes 264 adresses possibles ?
- Si je ne peux créer de sous-réseaux, je ne peux utiliser un routeur IPv6 entre ma Freebox et mon LAN ?
Voilà beaucoup de questions auxquelles il faudra répondre pour résoudre le problème.
10-1. IPv4 et IPv6 ensemble▲
C'est tout à fait possible. Depuis déjà pas mal de temps GNU/Linux installe par défaut les deux piles, et c'est IPv6 qui est prioritaire. Nous pourrons vérifier que, dans le cas où une ressource de l'internet dispose d'une adresse IPv6 et d'une adresse IPv4, c'est IPv6 qui sera employé.
Maintenant, il reste le problème qu'en IPv4, je n'ai qu'une seule adresse publique à ma disposition pour tout mon LAN et je dois donc obligatoirement faire du NAT. Je sais faire depuis longtemps, ce n'est pas un problème pour moi, un routeur NAT avec IPTables, je maîtrise parfaitement. En revanche, j'ai bien compris que mes configurations IPv6 vont se faire à partir des informations que le routeur IPv6 (dont je n'ai pas du tout la maîtrise) m'envoie via des messages ICMPv6. Un « switch » ? pourquoi pas, mais alors, adieu IPv4 qui a besoin d'un routeur.
Il faudrait que mon « machin à deux pattes » que je place entre ma Freebox et le switch de mon LAN agisse comme un routeur NAT pour IPv4 et soit transparent pour IPv6. Un petit dessin ?
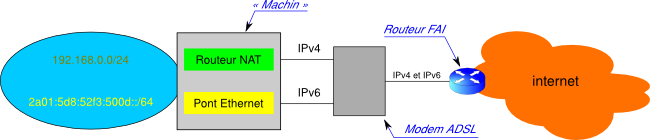
Le moyen simple pour que notre « machin » soit transparent au niveau IP est qu'il traite les paquets sur la couche inférieure, à savoir la couche Ethernet. Ce sont les ponts qui savent faire ce genre de choses.
Nous avons de la chance, GNU/Linux sait parfaitement faire le pont et sait donc résoudre notre problème, à la condition que nous soyons capables de lui expliquer qu'il ne doit le faire que pour les trames Ethernet qui transportent de l'IPv6 et surtout pas de l'IPv4, il n'y aurait plus de routage NAT IPv4 sinon. Nous verrons que GNU/Linux sait faire un pont intelligent.
10-2. IPv4 par routage NAT▲
Ce n'est pas une nouveauté. Nous disposons d'un réseau local, par exemple 192.168.0.0/24, avec son DHCP, son DNS cache et son routeur NAT, qui dispose d'une interface dans notre réseau local (par exemple 192.168.0.1) et une autre patte dans le réseau du fournisseur d'accès (par exemple 82.243.80.13).
Pour que tout ceci fonctionne en harmonie, Netfilter fait du masquage d'adresse, il faut écrire plein de règles IPtables bien senties, ce qui permet d'en profiter pour que notre routeur serve aussi de pare-feu.
Si nous désirons abriter un serveur dans notre LAN, qui soit visible depuis l'internet, c'est un peu plus compliqué. Il faut faire sur le routeur du « prerouting ». C'est-à -dire qu'il va falloir, toujours avec Netfilter/IPTables, indiquer que les requêtes entrant sur le routeur par le port qui correspond au service que nous voulons exposer (par exemple le port 80 pour http) devront être redirigées vers l'adresse IP locale de notre serveur sur le LAN. Il ne faut pas être manchot de l'iptables, mais ça se fait assez bien.
Bien entendu, ce genre d'ouverture augmente considérablement les risques d'intrusion sur votre LAN et il vaudrait mieux dans un tel cas disposer d'un routeur NAT à trois pattes, avec une DMZ pour y placer les machines exposées. Ceci complique encore un peu la configuration Netfilter/IPTables, mais ça reste toujours réalisable si l'on est un artiste du filtrage.
Lorsque nous utilisons sur les stations de notre LAN des applications qui sont à la fois client et serveur (ceci peut arriver dans certains protocoles apparentés au « peer to peer »), la configuration IPtables peut alors devenir à la fois un casse-tête et une passoire.
Mais comme le haut débit existe déjà depuis le début du siècle, nous avons largement eu le temps de nous familiariser avec toutes ces subtilités.
10-3. IPv6 par pontage Ethernet▲
De ceci, nous avons moins l'habitude et il convient peut-ĂŞtre ici de faire un point sur cette nouvelle situation.
10-3-1. Avantages▲
Toutes les stations de notre LAN vont avoir une adresse IPv6 publique. Plus besoin de NAT, plus besoin de « PREROUTING » tout ceci est terminé. Chacune de nos stations sera désormais directement accessible (sauf précautions particulières) depuis l'internet.
Si nous disposons d'un nom de domaine, il sera relativement facile de configurer un DNS capable de résoudre publiquement les adresses de tous nos hôtes locaux. Nous allons enfin pouvoir jouer comme les grands.
10-3-2. InconvĂ©nients▲
Oui mais, et la sécurité dans tout ça ? Jouer comme les grands c'est bien, mais il faut en avoir les compétences. La gestion de la sécurité devra se faire à plusieurs niveaux, chacun des hôtes du réseau local (qui n'est par le fait plus du tout un réseau local, mais bel et bien un morceau de l'internet) devra faire l'objet d'une attention toute particulière.
Iptables a son équivalent IPv6 et se nomme de façon originale : ip6tables, qui nous permettra de réaliser notre filtrage en IPv6, de façon tout à fait analogue à ce que nous savons faire en IPv4.
11. Un pont avec GNU/Linux▲
Réaliser une telle chose n'étant pas courante, nous allons détailler quelque peu. La station que nous avons connectée à notre « Freebox » est maintenant munie de deux interfaces :
- eth0 est sur la Freebox ;
- eth1 est connectée à un switch qui accueillera les hôtes de notre « LAN ».
C'est cette station qui va jouer le rôle de «machin ».
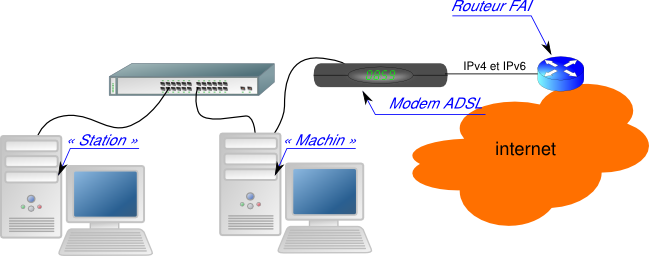
Machin reçoit pour eth0 une IPv4 et une IPv6 de la part de notre fournisseur :
~# ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:05:5d:df:fe:35
inet adr:82.243.80.13 Bcast:82.243.80.255 Masque:255.255.255.0
adr inet6: 2a01:5d8:52f3:500d:205:5dff:fedf:fe35/64 Scope:Global
adr inet6: fe80::205:5dff:fedf:fe35/64 Scope:Lien
...C'est bien, mais dans un premier temps, nous voulons juste en faire un pont Ethernet tout simple.
11-1. Les outils nĂ©cessaires▲
Nous sommes sur une Debian « testing ». Il nous faut les paquets :
- bridge-utils.
Description : « Utilities for configuring the Linux Ethernet bridge This package contains utilities for configuring the Linux Ethernet bridge in Linux 2.4 or later. The Linux Ethernet bridge can be used for connecting multiple Ethernet devices together. The connecting is fully transparent: hosts connected to one Ethernet device see hosts connected to the other Ethernet devices directly. »
Le pont Ethernet de Linux peut être utilisé pour connecter plusieurs interfaces Ethernet ensemble. La connexion est complètement transparente : les hôtes connectés à une interface voient directement les hôtes connectés aux autres interfaces ; - ebtables.
Description : Ethernet bridge frame table administration Ebtables is used to set up, maintain, and inspect the tables of Ethernet frame rules in the Linux kernel. It is analogous to iptables, but operates at the MAC layer rather than the IP layer.
Ebtales est Ă la couche Ethernet ce qu'iptables est Ă la couche IP.
Un aptitude install bridge-utils ebtables fera l'affaire.
11-2. Construire le pont▲
Bon gros avertissement…
Toute la manipulation qui suit est faite localement sur le machin. Si vous devez la faire à distance, voyez d'abord cette page de mise en garde sur les pertes de contrôle IP. Vous voilà prévenu.
Pour bien comprendre à quel point IP n'est pas nécessaire pour le bon fonctionnement d'un pont Ethernet, nous allons nous passer de toute configuration IP.
~# ifdown eth0
Internet Systems Consortium DHCP Client V3.1.0
Copyright 2004-2007 Internet Systems Consortium.
All rights reserved.
For info, please visit http://www.isc.org/sw/dhcp/
Listening on LPF/eth0/00:05:5d:df:fe:35
Sending on LPF/eth0/00:05:5d:df:fe:35
Sending on Socket/fallback
DHCPRELEASE on eth0 to 82.243.80.254 port 67Puis, nous activons eth0 et eth1, mais sans les configurer :
~# ifconfig eth0 up
~# ifconfig eth1 up
~# ifconfig
eth0 Link encap:Ethernet HWaddr 00:05:5d:df:fe:35
adr inet6: fe80::205:5dff:fedf:fe35/64 Scope:Lien
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
...
eth1 Link encap:Ethernet HWaddr 00:05:5d:e1:f7:ac
adr inet6: fe80::205:5dff:fee1:f7ac/64 Scope:Lien
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
...Nous n'avons sur nos deux interfaces qu'une adresse IPv6 de type lien local. Nous allons maintenant utiliser brctl pour construire le pont :
~# brctl addbr br0
~# brctl addif br0 eth0
~# brctl addif br0 eth1
~# ts2b7:~# brctl show
bridge name bridge id STP enabled interfaces
br0 8000.00055ddffe35 no eth0
eth1Nous avons bien un pont br0. Un pont, ça dispose au moins de deux bouts, ils sont ici eth0 et eth1. Si tout se passe comme nous le souhaitons, les paquets ethernet devraient passer ce pont selon les règles en usage sur ce type d'équipement.
Nous allons maintenant activer ce pont :
ifconfig br0 upVérifions la configuration IP de tout ceci :
~# ifconfig
br0 Link encap:Ethernet HWaddr 00:05:5d:df:fe:35
adr inet6: fe80::205:5dff:fedf:fe35/64 Scope:Lien
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
...
eth0 Link encap:Ethernet HWaddr 00:05:5d:df:fe:35
adr inet6: fe80::205:5dff:fedf:fe35/64 Scope:Lien
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
...
eth1 Link encap:Ethernet HWaddr 00:05:5d:e1:f7:ac
adr inet6: fe80::205:5dff:fee1:f7ac/64 Scope:Lien
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
...Nous n'avons que des IPv6 lien local. Notez que br0 apparaît comme une interface à part entière, avec l'adresse MAC de l'interface eth0. Pour qu'il n'y ait absolument aucune ambigüité dans cette manip, nous allons jusqu'à supprimer ces adresses IPv6 locales :
~# ip -6 addr del fe80::205:5dff:fedf:fe35/64 dev br0
~# ip -6 addr del fe80::205:5dff:fedf:fe35/64 dev eth0
~# ip -6 addr del fe80::205:5dff:fee1:f7ac/64 dev eth1Ce qui nous donne maintenant :
~# ifconfig
br0 Link encap:Ethernet HWaddr 00:05:5d:df:fe:35
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
...
eth0 Link encap:Ethernet HWaddr 00:05:5d:df:fe:35
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
...
eth1 Link encap:Ethernet HWaddr 00:05:5d:e1:f7:ac
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
...Plus aucune trace d'IP, v4 comme v6.
11-3. Passer le pont▲
Il suffit de passer le pont C'est tout de suite l'aventure Laisse-moi tenir ton jupon J't'emmèn' visiter la nature…
Bref, nous démarrons la station. Une station toute simple, avec une distribution Ubuntu des familles. Sitôt fini le démarrage, empressons-nous de consulter la configuration réseau :
~$ ifconfig
eth0 Lien encap:Ethernet HWaddr 00:0C:6E:AD:B6:99
inet adr:82.243.80.13 Bcast:82.243.80.255 Masque:255.255.255.0
adr inet6: 2a01:5d8:52f3:500d:20c:6eff:fead:b699/64 Scope:Global
adr inet6: fe80::20c:6eff:fead:b699/64 Scope:Lien
...Ça marche, nous avons notre IPv4 publique et aussi nos deux IPv6. Si nous avons une IPv4 publique sur eth0 c'est bien que la couche IPv4 de notre station n'a pas « vu » le « machin » non ?
Voyons la table de routage IPv4Â :
~$ route -n
Table de routage IP du noyau
Destination Passerelle Genmask Indic Metric Ref Use Iface
82.243.80.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
0.0.0.0 82.243.80.254 0.0.0.0 UG 100 0 0 eth0Ça se confirme, pour IPv4, le « machin » n'intervient pas dans les routes.
Et les routes IPv6Â ?
~$ route -A inet6
Table de routage IPv6 du noyau
Destination Next Hop Flags Metric Ref Use Iface
::1/128 :: U 0 4 1 lo
2a01:5d8:52f3:500d:20c:6eff:fead:b699/128 :: U 0 152 1 lo
2a01:5d8:52f3:500d::/64 :: UA 256 0 0 eth0
fe80::20c:6eff:fead:b699/128 :: U 0 3 1 lo
fe80::/64 :: U 256 0 0 eth0
ff00::/8 :: U 256 0 0 eth0
::/0 fe80::207:cbff:fe1f:f5a UGDA 1024 74 0 eth0Là encore, le « machin » n'est pas visible.
Un petit traceroute IPv4 vers www.kame.net ?
~$ sudo traceroute www.kame.net
traceroute to www.kame.net (203.178.141.194), 64 hops max, 40 byte packets
1 82.243.80.254 (82.243.80.254) 37 ms 37 ms 37 ms
2 213.228.20.254 (213.228.20.254) 44 ms * 37 ms
...
23 orange.kame.net (203.178.141.194) 308 ms 308 ms 308 msLe « hop » 1 est bien la passerelle par défaut du fournisseur d'accès. Il n'y a plus de doutes à avoir pour IPv4.
Et pour ipV6Â ?
~/.ssh$ sudo traceroute6 www.kame.net
traceroute to www.kame.net (2001:200:0:8002:203:47ff:fea5:3085) from 2a01:5d8:52f3:500d:20c:6eff:fead:b699, 30 hops max, 16 byte packets
1 2a01:5d8:52f3:500d::1 (2a01:5d8:52f3:500d::1) 1.549 ms 0.594 ms 0.575 ms
2 2a01:5d8:e000:9d1::4 (2a01:5d8:e000:9d1::4) 51.501 ms 48.268 ms 48.146 ms
...
24 orange.kame.net (2001:200:0:8002:203:47ff:fea5:3085) 336.759 ms 337.563 ms 336.053 msLà encore, le « hop » 1 correspond bien à la passerelle du fournisseur. Plus de doutes non plus pour IPv6.
Nous avons rempli la première partie du contrat, le « Machin » est complètement invisible, aussi bien en IPv4 qu'en IPv6. L'est-il aussi au niveau Ethernet ? Des ponts, il y en a plein les switch et ces derniers sont bien invisibles au niveau Ethernet. Vérifions tout de même.
11-3-1. VĂ©rifications de routine▲
Un 'tit coup de rdisc6Â :
~$ rdisc6 eth0
Solicitation de ff02::2 (ff02::2) sur eth0...
Limite de saut (TTL) : 64 ( 0x40)
Conf. d'adresse par DHCP : Non
Autres réglages par DHCP : Non
Préférence du routeur : moyen
Durée de vie du routeur : 1800 (0x00000708) secondes
Temps d'atteinte : non indiqué (0x00000000)
Temps de retransmission : non indiqué (0x00000000)
Préfixe : 2a01:5d8:52f3:500d::/64
Durée de validité : 86400 (0x00015180) secondes
Durée de préférence : 86400 (0x00015180) secondes
Recursive DNS server : 2a01:5d8:e0ff::2
Recursive DNS server : 2a01:5d8:e0ff::1
DNS servers lifetime : 600 (0x00000258) secondes
MTU : 1480 octets (valide)
Adresse source de lien : 00:07:CB:1F:0F:5A
de fe80::207:cbff:fe1f:f5aOK, le routeur IPv6 habituel.
~$ ping6 -c 3 fe80::207:cbff:fe1f:f5a%eth0
PING fe80::207:cbff:fe1f:f5a%eth0(fe80::207:cbff:fe1f:f5a) 56 data bytes
64 bytes from fe80::207:cbff:fe1f:f5a: icmp_seq=1 ttl=64 time=1.73 ms
64 bytes from fe80::207:cbff:fe1f:f5a: icmp_seq=2 ttl=64 time=0.701 ms
64 bytes from fe80::207:cbff:fe1f:f5a: icmp_seq=3 ttl=64 time=0.699 ms
--- fe80::207:cbff:fe1f:f5a%eth0 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2001ms
rtt min/avg/max/mdev = 0.699/1.044/1.732/0.486 ms
~$ ip -6 neigh show
fe80::207:cbff:fe1f:f5a dev eth0 lladdr 00:07:cb:1f:0f:5a router DELAYLe voisinage, c'est bien le routeur du fournisseur d'accès et pas notre pont, preuve que c'est un pont:-)
11-4. Couper les ponts IPv4▲
Nous allons maintenant réaliser un pont qui ne fonctionnera que pour IPv6. Mais avant, prenons quelques précautions, car il n'y aura plus de connectivité IPv4 pour notre station de travail.
DNS Free (IPv4)Â :
option domain-name-servers 212.27.54.252,212.27.53.252;(information prise dans les logs du client dhcp).
11-4-1. Sur le « machin »▲
Commençons par couper le pont IPv4 au moyen d'ebtables :
~# ebtables -t broute -A BROUTING -p ! ipv6 -j DROPÀ ce niveau, notre station de travail ne dispose plus d'IPv4. Il nous faut maintenant configurer le « machin » en routeur NAT IPv4. C'est une formalité.
11-4-1-1. Une IPv4 dynamique pour eth0▲
Bien que notre IPv4 soit fixe, la configuration est tout de même récupérée par DHCP :
~# dhclient eth0
Internet Systems Consortium DHCP Client V3.1.0
Copyright 2004-2007 Internet Systems Consortium.
All rights reserved.
For info, please visit http://www.isc.org/sw/dhcp/
Listening on LPF/eth0/00:05:5d:df:fe:35
Sending on LPF/eth0/00:05:5d:df:fe:35
Sending on Socket/fallback
DHCPDISCOVER on eth0 to 255.255.255.255 port 67 interval 7
DHCPOFFER from 82.243.80.254
DHCPREQUEST on eth0 to 255.255.255.255 port 67
DHCPACK from 82.243.80.254
bound to 82.243.80.13 -- renewal in 604800 seconds.11-4-1-2. Une IPv4 fixe pour eth1▲
Nous allons nous faire un petit 192.168.254.0/24 pour changer un peu de la routine :
~# ip addr add 192.168.254.1/24 dev eth111-4-1-3. Un masquerade pour eth0▲
Nous faisons du NAT sur tout ce qui sort par eth0Â :
~# iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE11-4-1-4. Activer le routage▲
(Ne pas oublier ce détail, si l'on souhaite garder sa chevelure intacte…)
echo 1 > /proc/sys/net/ipv4/ip_forward11-4-1-5. VĂ©rifications▲
~# ifconfig
br0 Link encap:Ethernet HWaddr 00:05:5d:df:fe:35
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
...
eth0 Link encap:Ethernet HWaddr 00:05:5d:df:fe:35
inet adr:82.243.80.13 Bcast:82.243.80.255 Masque:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
...
eth1 Link encap:Ethernet HWaddr 00:05:5d:e1:f7:ac
inet adr:192.168.254.1 Bcast:0.0.0.0 Masque:255.255.255.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
...Tout Ă l'air normal.
~# route -n
Table de routage IP du noyau
Destination Passerelle Genmask Indic Metric Ref Use Iface
82.243.80.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
192.168.254.0 0.0.0.0 255.255.255.0 U 0 0 0 eth1
0.0.0.0 82.243.80.254 0.0.0.0 UG 0 0 0 eth0Tout à l'air normal aussi. Notre routeur NAT IPv4 devrait être opérationnel.
11-4-2. Sur la station de travail▲
Commençons par désactiver eth0
:~$ sudo ifdown eth0Réactivation de eth0, mais sans configuration :
:~$ sudo ifconfig eth0 upAjout d'une adresse IPv4 compatible avec celle que nous avons mise sur eth1 du « Machin » :
~$ sudo ip addr add 192.168.254.2/24 dev eth0Ajout d'une route par défaut qui pointe sur « Machin » :
~$ sudo ip route add default via 192.168.254.1 dev eth0Vérifications d'usage :
:~$ route -n
Table de routage IP du noyau
Destination Passerelle Genmask Indic Metric Ref Use Iface
192.168.254.0 0.0.0.0 255.255.255.0 U 0 0 0 eth0
0.0.0.0 192.168.254.1 0.0.0.0 UG 0 0 0 eth0Si nous désirons être efficaces, il faut maintenant renseigner le système sur les DNS à consulter pour la résolution des noms. Éditons /etc/resolv.conf pour qu'il ressemble à ceci :
~$ cat /etc/resolv.conf
nameserver 212.27.54.252
nameserver 212.27.53.252Et voyons si ça roule :
~$ ping -c 1 www.kame.net
PING www.kame.net (203.178.141.194) 56(84) bytes of data.
64 bytes from orange.kame.net (203.178.141.194): icmp_seq=1 ttl=43 time=313 ms
--- www.kame.net ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 313.359/313.359/313.359/0.000 ms
~$ ping6 -c 1 www.kame.net
PING www.kame.net(orange.kame.net) 56 data bytes
64 bytes from orange.kame.net: icmp_seq=1 ttl=47 time=340 ms
--- www.kame.net ping statistics ---
1 packets transmitted, 1 received, 0% packet loss, time 0ms
rtt min/avg/max/mdev = 340.627/340.627/340.627/0.000 msÇa roule. En IPv4 comme en IPv6, nous pouvons faire ping sur la tortue. Je vous laisse vérifier par vous-même, avec des traceroute biens sentis, que le « Machin » est vu comme un routeur en IPv4 et comme rien du tout en IPv6.
11-5. Fignolage▲
Bien entendu, il reste quelques opérations cosmétiques à réaliser :
- faire un peu de filtrage sanitaire en IPv4 sur le Machin ;
- installer un DNS cache pour que nos clients du LAN n'aient pas à connaître les DNS du fournisseur d'accès ;
- installer un DHCP sur le LAN pour que nos clients se configurent automatiquement en IPv4Â ;
- et surtout, automatiser tout ça pour que nous ne soyons pas obligé de ressortir nos notes au prochain reboot du Machin.
Les trois premiers points, voilĂ longtemps que nous savons faire. Voyons plutĂ´t comment automatiser la configuration du Machin.
12. Automatiser le machin▲
La suite s'adresse principalement aux (heureux) utilisateurs de Debian et dérivées. En effet la configuration du réseau est assez particulière sur ces distributions et très différente de la façon de faire sur les « Red-Hat like » ou autres « Slackware / Gentoo / Suse like ».
Debian utilise un fichier /etc/network/interfaces et plusieurs répertoires contenant des scripts à exécuter en « pre-up, up, down et postdown ». Le paquet « bridge-utils » a déjà installé les scripts /etc/network/if-pre-up.d/bridge et /etc/network/if-postdown.d/bridge auxquels il est inutile et même déconseillé de toucher. Tout va pouvoir se faire à partir du fichier /etc/network/interfaces :
auto br0
iface br0 inet manual
bridge_ports eth0 eth1
bridge_maxwait 0
pre-up ebtables -t broute -A BROUTING -p ! ipv6 -j DROP
down ebtables -t broute -F
auto eth0
iface eth0 inet dhcp
up iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
down iptables -t nat -F
auto eth1
iface eth1 inet static
address 192.168.254.1
netmask 255.255.255.0- iface br0 inet manual indique que l'interface br0 sera configurée par les scripts ifupdown ;
- bridge_ports eth0 eth1 et bridge_maxwait 0 sont des directives qui seront utilisées par ces scripts pour configurer le pont ;
- pre-up ebtables -t broute -A BROUTING -p ! ipv6 -j DROP (fondamental) permettra d'interdire le pont au trafic IPv4, lorsque le pont est activé ;
- down ebtables -t broute -F remettra les choses à plat en ce qui concerne les tables du pont lorsque ce dernier est désactivé.
Ce n'est pas dans mes habitudes, mais si vous souhaitez avoir plus d'informations sur les directives de configuration des interfaces réseau sous Debian, je vous dirai man interfaces (lorsque l'on veut jouer avec IPv6, il faut savoir donner de sa personne).
En ce qui concerne l'interface eth0, la ligne up iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE est tout à fait minimaliste, nous sommes là pour vérifier que ça fonctionne. Dans la pratique, il faudra ici invoquer un script qui écrive de vraies règles de filtrage IPv4.
De même, il faudra éventuellement réfléchir à des règles ebtables et IP6tables pour protéger au moins notre machin contre d'éventuelles attaques IPv6.
12-1. Quelques vĂ©rifications▲
Voyons la configuration IP des divers composants :
~# ifconfig
br0 Link encap:Ethernet HWaddr 00:05:5d:df:fe:35
adr inet6: 2a01:5d8:52f3:500d:205:5dff:fedf:fe35/64 Scope:Global
adr inet6: fe80::205:5dff:fedf:fe35/64 Scope:Lien
...
eth0 Link encap:Ethernet HWaddr 00:05:5d:df:fe:35
inet adr::82.243.80.13 Bcast::82.243.80.255 Masque:255.255.255.0
adr inet6: fe80::205:5dff:fedf:fe35/64 Scope:Lien
...
eth1 Link encap:Ethernet HWaddr 00:05:5d:e1:f7:ac
inet adr:192.168.254.1 Bcast:192.168.254.255 Masque:255.255.255.0
adr inet6: fe80::205:5dff:fee1:f7ac/64 Scope:Lien
...L'adresse globale IPv6 sur br0 n'est pas fondamentale si le machin ne doit pas lui-même accéder à l'internet par IPv6. Eth0 et eth1 disposent de leurs adresses IPv4 convenablement, les adresses IPv6 sont totalement inutiles ici, mais ne sont pas gênantes.
Les routes IPv4Â :
~# ip route ls
82.243.80.0/24 dev eth0 proto kernel scope link src 82.243.80.13
192.168.254.0/24 dev eth1 proto kernel scope link src 192.168.254.1
default via 82.243.80.254 dev eth0Tout ceci est parfait. Les routes IPv6 maintenant :
~# ip -6 route ls
2a01:5d8:52f3:500d::/64 dev br0 proto kernel metric 256 expires 85974sec mtu 1480 advmss 1420 hoplimit 4294967295
fe80::/64 dev eth0 metric 256 expires 21332903sec mtu 1500 advmss 1440 hoplimit 4294967295
fe80::/64 dev eth1 metric 256 expires 21332903sec mtu 1500 advmss 1440 hoplimit 4294967295
fe80::/64 dev br0 metric 256 expires 21332903sec mtu 1480 advmss 1420 hoplimit 4294967295
default via fe80::207:cbff:fe1f:f5a dev br0 proto kernel metric 1024 expires 1369sec mtu 1480 advmss 1440 hoplimit 64Notez encore une fois que ceci n'est pas nécessaire si le machin ne doit pas lui-même accéder à l'internet en IPv6.
Vérification des « ebtables » :
~# ebtables -t broute -L
Bridge table: broute
Bridge chain: BROUTING, entries: 1, policy: ACCEPT
-p ! IPv6 -j DROPC'est bon.
Et IPtables (IPv4)Â ?
~# iptables-save
# Generated by iptables-save v1.4.0 on Tue May 6 14:59:45 2008
*nat
:PREROUTING ACCEPT [738:380896]
:POSTROUTING ACCEPT [0:0]
:OUTPUT ACCEPT [127:9544]
-A POSTROUTING -o eth0 -j MASQUERADEImpeccable.
Attention toutefois, un ifdown br0 fera tomber toutes les interfaces et pas seulement br0. Il faudrait sans doute étudier le script /etc/network/if-postdown.d/bridge du paquetage bridge-utils ou créer un script /etc/network/if-down.d/bridge spécifique pour améliorer ce comportement.
13. Le bridge et la couche IP▲
13-1. DĂ©sagrĂ©ments en perspective▲
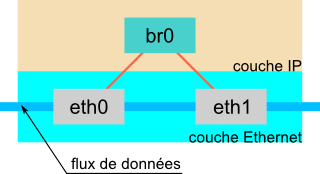
Lorsque le pont est construit (entre eth0 et eth1 dans l'exemple), le flux des données est directement échangé, si nécessaire, entre eth0 et eth1 au niveau Ethernet, et donc à l'insu complet de la couche IP. Même si eth0 et eth1 disposent d'une adresse IP, ces interfaces ne remonteront plus les données qu'elles reçoivent au niveau IP.
Autrement dit, si vous faites ça à distance en vous connectant sur la machine aussi bien par eth0 que par eth1, sitôt que le pont sera opérationnel, vous en perdrez le contrôle sans rémission.
Heureusement tout de même, il existe des solutions pour répondre à ce désagrément potentiel.
13-2. Et br0Â ?▲
Lorsque nous créons un pont avec brctl addbr, le nom attribué à ce pont (ici br0) apparait comme un nœud réseau auquel il est possible d'attribuer une adresse IP. br0 sera accessible par IP. Tous ceux qui ont eu l'occasion d'avoir entre les mains un switch administrable savent que ces dispositifs disposent d'une adresse IP qui permet leur administration par un moyen plus sympathique que le terminal VT100 sur le port RS232.
13-3. Ce Ă quoi il faut prendre garde▲
Nous accédons à une machine distante, disons par eth0 pour fixer les idées. Nous voulons sur cette machine configurer un pont dans lequel eth0 sera intégré.
Lorsque eth0 sera intégrée au pont br0, nous perdrons instantanément et sans rémission la connexion. Si la machine n'est pas physiquement accessible, nous sommes mal barrés.
Le moyen le plus simple est de disposer d'une interface supplémentaire, qui ne doit pas être intégrée au pont et par laquelle nous pouvons accéder à la machine, mais ceci n'est bien entendu pas toujours possible.
13-4. Solutions ?▲
Dans notre cas où le pont n'est destiné qu'au trafic IPv6 et non IPv4, la première précaution à prendre est de s'assurer que la règle ebtables -t broute -A BROUTING -p ! ipv6 -j DROP est en place avant d'activer le pont.
Attribuer une adresse IPv6 au pont br0 après l'avoir créé mais avant de lui assigner les interfaces Ethernet peut également être d'un grand secours.
14. Remerciements Developpez▲
Vous pouvez retrouver l'article original ici : L'Internet Rapide et Permanent. Christian Caleca a aimablement autorisé l'équipe « Réseaux » de Developpez.com à reprendre son article. Retrouvez tous les articles de Christian Caleca sur cette page.
Nos remerciements Ă ClaudeLELOUP pour sa relecture orthographique.
N'hésitez pas à commenter cet article ! 9 commentaires ![]()