



I. Le codage des caractĆØres▲
Peut-ĆŖtre trouvez-vous Ć©vident qu'une machine informatique soit capable de gĆ©rer efficacement vos donnĆ©es, quelles qu'elles soient, y compris le texteĀ ?
Avez-vous pensĆ© un seul instant que, aussi puissant soit-il, votre merveilleux ordinateur n'a qu'un doigt pour compterĀ ?
Et pourtant, Ƨa marche. Nous allons voir comment.
Par la mĆŖme occasion, nous verrons aussi pourquoi, quelquefois, il y a des petites Ā«Ā curiositĆ©sĀ Ā» dans l'affichage du texte, principalement sur les lettres accentuĆ©es et certains symboles.
I-A. Le codage des donnĆ©es▲
S'il est assez naturel de transformer un nombre Ā«Ā humainĀ Ā» (en base 10) dans n'importe quelle autre base de calcul, y compris la base 2 (et rĆ©ciproquement), c'est un peu plus compliquĆ© de coder en binaire les symboles d'Ć©criture.
PourquoiĀ ?
Parce qu'il n'y a pas rĆ©ellement d'algorithmes mathĆ©matiques pour le faire et qu'il faudra donc travailler sur des conventions. Vous savez ce que valent les conventions, elles sont adoptĆ©es jusqu'Ć ce qu'elles ne le soient plus. De plus, les limites d'une convention sont bien connuesĀ :
- une convention est attachĆ©e Ć un contexte. Lorsque le contexte change, la convention doit ĆŖtre modifiĆ©e. Un exemple simple dans le domaine qui nous intĆ©resse iciĀ : l'adoption par la CommunautĆ© europĆ©enne du symbole de sa monnaie unique, l'euro. Changement de contexte, ce symbole doit ĆŖtre ajoutĆ© Ć la liste des symboles d'Ć©criture utilisĆ©e dans tous les pays de l'UEĀ ;
- une convention doit satisfaire toutes les parties concernĆ©es. Lesdites parties cherchant chacune Ć faire prĆ©valoir leur point de vue, les conventions sont gĆ©nĆ©ralement adoptĆ©es trop tard.
Nous allons ici essayer de passer en revue les principales conventions adoptĆ©es pour le codage des symboles d'Ć©criture, en ayant Ć l'esprit que nous sommes dans un contexte mondial, avec plusieurs langues, plusieurs alphabets et, pour compliquer encore le problĆØme, plusieurs systĆØmes d'information.
II. L'Ɖcriture▲
II-A. Pourquoi Ć©crireĀ ?▲

La question peut paraĆ®tre stupide, tant l'Ć©crit demeure un moyen primordial dans nos civilisations pour la communication. En tĆ©moignent ces quelques pages. Le problĆØme principal vient, nous le savons, de la multitude de langues utilisĆ©es de par le monde, multitude qui utilise elle-mĆŖme une multitude de symboles dans sa forme Ć©crite. Si l'alphabet latin reste probablement le plus utilisĆ©, notons dĆ©jĆ la grande quantitĆ© de symboles altĆ©rĆ©s par des accentuations et autres contractions comme le fameux Ā«Ā e dans l'o (Å“)Ā». L'alphabet latin reste, mĆŖme avec toutes les altĆ©rations qu'on lui connaĆ®t, largement insuffisant pour permettre l'Ć©criture de toutes les langues telles que le grec, l'hĆ©breu, l'arabe, le russe et sans parler encore des langues asiatiquesā€¦
II-B. Comment Ć©crireĀ ?▲
Nous parlons d'informatiqueĀ ; ici, pas de crayons. Les outils qui permettent d'afficher du texte sont principalement de deux sortesĀ :
II-B-1. Les imprimantes▲
Nous pouvons les classer en deux grandes catĆ©goriesĀ :
- les imprimantes dont le ou les jeux de caractĆØres sont formĆ©s mĆ©caniquement. MĆŖme si elles n'ont plus cours aujourd'hui, elles ont Ć©tĆ© parmi les premiĆØres. Depuis les ancĆŖtres utilisant un jeu de marteaux comme les machines Ć Ć©crire mĆ©caniques, jusqu'aux Ā«Ā margueritesĀ Ā» (une galette en matĆ©riau souple, constituĆ©e de pĆ©tales, chacun portant un caractĆØre) en passant par les imprimantes Ć boule dont IBM Ć©tait le champion.
Dans tous ces cas, les symboles sont gravĆ©s sur un support mĆ©canique et l'impression se fait par impact sur un ruban encreur intercalĆ© entre l'outil de frappe et le papierĀ ; - les imprimantes dont les jeux de caractĆØres sont formĆ©s Ć partir d'une matrice de points. Depuis les antiques imprimantes Ć aiguilles jusqu'au laser en passant par le jet d'encre, le principe consiste Ć dessiner les caractĆØres par impression de points. L'imprimante dispose alors de tables qui contiennent une reprĆ©sentation Ā«Ā bitmapĀ Ā» de l'ensemble des caractĆØres, ces tables pouvant ĆŖtre embarquĆ©es dans la mĆ©moire de l'imprimante ou tĆ©lĆ©chargĆ©es Ć la demande.
Dans tous les cas, l'imprimante reƧoit un code numĆ©rique Ć©crit sur un octet (parfois plusieurs) et dĆ©duit de ce code le caractĆØre qu'elle doit imprimer.
II-B-2. Les Ć©crans▲
Qu'ils soient Ć tube cathodique, Ć cristaux liquides ou mĆŖme Ć plasma, le principe est similaire aux imprimantes Ć matrices de points.
II-B-3. La mĆ©thode globale d'impression▲
S'il s'agit d'un procĆ©dĆ© d'impression mĆ©canique type marguerite ou boule, un code va permettre de placer l'organe mĆ©canique Ć la bonne place pour imprimer le caractĆØre souhaitĆ©. Un changement de forme de caractĆØres implique un changement de l'organe mĆ©canique.
S'il s'agit d'un systĆØme Ć matrice de points, chaque caractĆØre est dessinĆ© dans une table et le systĆØme n'a qu'Ć aller chercher le bon dessin. Bien entendu, ce systĆØme est plus souple et propose gĆ©nĆ©ralement plusieurs typographies.
Nous n'entrerons pas trop dans les dĆ©tails du pilotage d'une imprimante, mais en gĆ©nĆ©ral, un langage particulier (PCL, PostScript) permet Ā«Ā d'expliquerĀ Ā» Ć l'imprimante ce qu'elle a Ć faire (police de caractĆØres Ć utiliser, taille, format du papier Ć utiliserā€¦), en plus de lui envoyer les donnĆ©es Ć imprimer.
Pour les Ć©crans, c'est l'interface graphique avec son Ā«Ā driverĀ Ā», mais aussi le systĆØme d'exploitation lui-mĆŖme qui se charge de ce travail. Ce qu'il est important de comprendre, c'est qu'en ce qui concerne le contenu du message Ć imprimer, il doit exister un code qui dĆ©finisse parfaitement l'ensemble des caractĆØres de l'alphabet d'une (ou de plusieurs) langue(s) donnĆ©e(s). Ce code, dans le cas de systĆØmes communicants, comme c'est le cas sur l'Internet, doit ĆŖtre adoptĆ© par toutes les parties qui dĆ©cident de communiquer entre ellesĀ ; faute de quoi, il apparaĆ®tra des aberrations dans les textes affichĆ©s.
L'objectif de ce chapitre est d'essayer de clarifier autant que possible l'ensemble des procĆ©dures mises en Å“uvre pour parvenir Ć communiquer par l'Ć©crit de faƧon satisfaisante.
III. Le code ASCII▲
III-A. Au dĆ©but Ć©tait le texte▲
Nous n'avons pas le choix, nous devons adopter une convention qui associera un nombre Ć un symbole d'Ć©criture, puisque nous disposons de machines qui ne savent manipuler que des nombres. Nous crĆ©erons ainsi une table d'Ć©quivalence entre des valeurs numĆ©riques et des symboles d'Ć©criture. Toutes les parties qui communiqueront entre elles en adoptant la mĆŖme convention arriveront donc, en principe, Ć se comprendre.

Figurez-vous que l'informatique n'a pas toujours Ć©tĆ© aussi compliquĆ©e. Voici un exemple de terminal informatique fort courant Ć une certaine Ć©poque . Cette magnifique bestiole, appelĆ©e Ā«Ā tĆ©lĆ©typeĀ Ā» du nom de l'entreprise qui la fabriquait (les plus jeunes ne peuvent pas connaĆ®tre, la machine date de 1967), servait Ć dialoguer avec un ordinateur, par le truchement d'une liaison sĆ©rie RS232, que nous connaissons toujours, mĆŖme si ses jours sont dĆ©sormais comptĆ©s. En ces temps reculĆ©s de l'informatique, le tube cathodique n'Ć©tait pas un pĆ©riphĆ©rique courant. On utilisait volontiers Ć la place une imprimante, le plus souvent Ć boule ou Ć marguerite. Cette machine disposait par ailleurs d'un lecteur/perforateur de ruban en papier (trou/pas trou -> 1/0). Mais aussi intĆ©ressantes soient-elles, ces considĆ©rations archĆ©ologiques nous Ć©cartent de notre sujet initialā€¦
La liaison RS232 prĆ©voit de transmettre en sĆ©rie (bit par bit) un mot de 8 bits en utilisant le bit de poids le plus fort (bit 7) comme bit de paritĆ©, pour effectuer un contrĆ´le de validitĆ© de la donnĆ©e. Le principe est simpleĀ : dans un octet, le bit de paritĆ© est ajustĆ© de maniĆØre Ć ce que le nombre de 1 soit toujours pair (ou impair, Ƨa dĆ©pend de la convention adoptĆ©e).
Dans ce cas de figure, il n'y a que 7 bits (b0 Ć b6) qui sont significatifs d'une donnĆ©e, le dernier bit servant juste Ć ajuster la paritĆ©.
III-A-1. 7 bits pour un caractĆØre▲
L'Ā«Ā American Standard Code for Information InterchangeĀ Ā» (ASCII) s'est donc ingĆ©niĆ© Ć coder chaque caractĆØre d'une machine Ć Ć©crire sous la forme d'une combinaison de 7 bits. En dĆ©cimal, nous obtenons des valeurs comprises entre 0 et 127.
Comme la base binaire (0 ou 1), si elle est trĆØs commode pour un calculateur Ć©lectronique, elle l'est beaucoup moins pour le cerveau humain, nous allons utiliser une autre base qui, si elle n'est guĆØre plus Ā«Ā parlanteĀ Ā», offre tout de mĆŖme l'avantage d'aboutir Ć une Ć©criture beaucoup plus compacte. Cette base devra ĆŖtre une puissance de 2, la plus courante Ć©tant la base hexadĆ©cimale, parce que chaque Ā«Ā digitĀ Ā» hexadĆ©cimal va reprĆ©senter une combinaison de 4 bitsĀ :
|
0000 |
0001 |
0010 |
0011 |
0100 |
0101 |
0110 |
0111 |
1000 |
1001 |
1010 |
1011 |
1100 |
1101 |
1110 |
1111 |
|
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
A |
B |
C |
D |
E |
F |
Mais il est aussi possible d'utiliser de l'octal, sur trois bits.
Pourquoi pas la base 10 Ć laquelle nous sommes habituĆ©s depuis notre plus tendre enfanceĀ ? Parce que, malheureusement, 10 n'est pas une puissance de 2 et qu'un Ā«Ā digitĀ Ā» dĆ©cimal ne reprĆ©sente donc pas toutes les combinaisons que l'on peut faire avec un groupe de n bits. 4 c'est trop (hexadĆ©cimal) et 3 ce n'est pas assez (octal). Plus mathĆ©matiquement, on ne peut pas trouver de valeur entiĆØre de n telle que 10=2n. Essayez donc de rĆ©soudre n=Log(10)/Log(2).
Certains ont mis en Å“uvre un codage appelĆ© BCD (Binary Coded Decimal). Le principe est simpleĀ : chaque Ā«Ā digitĀ Ā» dĆ©cimal (de 0 Ć 9) est codĆ© sur un quartet. Certaines combinaisons de bits sont donc impossibles.
- 9 va donner 1001Ā :
- 10 donnera 0001 0000 et non pas 1010.
Mais revenons Ć notre code ASCIIĀ ; 7 bits sont-ils suffisantsĀ ? Oui et nonā€¦
D'abord, dans une machine Ć Ć©crire, il n'y a pas que des caractĆØres imprimables. Il y a aussi des Ā«Ā caractĆØres de contrĆ´leĀ Ā», comme le saut de ligne, le retour chariot, le saut de page, la tabulation, le retour arriĆØreā€¦ Tous ces caractĆØres doivent aussi ĆŖtre codĆ©s pour que l'ordinateur puisse efficacement piloter une imprimante.
De plus, pour transmettre convenablement un texte, il faudra quelques sĆ©maphores pour indiquer par exemple quand commence le texte, quand il finitā€¦
Enfin, suivant les langues, mĆŖme lorsqu'elles exploitent l'alphabet latin, certaines lettres sont altĆ©rĆ©es diffĆ©remment. L'anglais n'utilise pas d'accents, mais la plupart des autres langues les exploitent plus ou moins parcimonieusement.
Finalement, si 7 bits suffisent gĆ©nĆ©ralement pour une langue donnĆ©e, Ć©ventuellement en faisant l'impasse sur certains symboles peu usitĆ©s comme [ou], nous ne pourrons pas coder l'ensemble des caractĆØres nĆ©cessaires pour la totalitĆ© des langues utilisant l'alphabet latin.
La norme ISO-646 dĆ©finit un code ASCII sur 7 bits. Ce code, parfaitement adaptĆ© Ć l'anglais US, l'est moins pour les autres langues. Nous assistons donc Ć la crĆ©ation d'une multitude de Ā«Ā dialectes ASCIIĀ Ā», oĆ¹ certains caractĆØres sont remplacĆ©s par d'autres suivant les besoins locaux. Les lecteurs les plus Ā«Ā anciensĀ Ā» se rappelleront peut-ĆŖtre des configurations hasardeuses de certaines imprimantes pour arriver Ć ce qu'elles impriment un franƧais lisibleā€¦
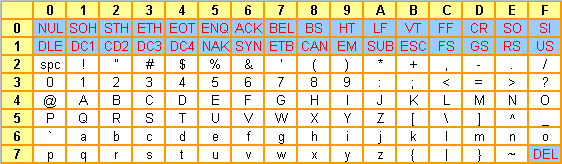
Les Ā«Ā caractĆØresĀ Ā» sur fond bleu sont les caractĆØres non imprimables. Pour bien lire le tableau, il faut construire le code hexadĆ©cimal en prenant d'abord le digit de la ligne, puis le digit de la colonne. Par exemple, la lettre Ā«Ā nĀ Ā» a pour code hexadĆ©cimal 6E.
Comme vous le constatez, il n'y a aucune lettre accentuĆ©e dans ce codage. Ce dernier a donc Ć©tĆ© joyeusement Ā«Ā localisĆ©Ā Ā» pour satisfaire aux exigences des divers pays utilisant l'alphabet latin. Cette situation aboutit rapidement Ć une impasse, les fichiers ainsi construits n'Ć©tant plus exportables dans d'autres pays. De plus, vous constaterez aisĆ©ment que l'ajout de caractĆØres supplĆ©mentaires (le Ā«Ā Ć©Ā Ā», le Ā«Ā ƧĀ Ā», le Ā«Ā Ć Ā Ā» etc.) implique obligatoirement la suppression d'autres caractĆØres (le Ā«Ā [Ā Ā», le Ā«Ā ]Ā Ā», le Ā«Ā #Ā Ā» etc.). Ceux qui ont quelques notions de programmation comprendront Ć quel point c'est facile d'Ć©crire du code avec un jeu de caractĆØres amputĆ© de ces symboles. Dans la pratique, les programmeurs Ć©taient condamnĆ©s Ć utiliser un clavier US.
III-A-2. Pour un bit de plus▲
Avec les avancĆ©es de la technique, le huitiĆØme bit qui servait pour le contrĆ´le de paritĆ©, contrĆ´le rendu de plus en plus inutile, va ĆŖtre utilisĆ© pour coder plus de caractĆØres. Deux fois plus, finalement.
Ainsi, le codage Ā«Ā ISO-LATIN-1Ā Ā», Ć©galement connu sous le nom de Ā«Ā ISO-8859-1Ā Ā» propose Ć peu prĆØs le codage suivantĀ :
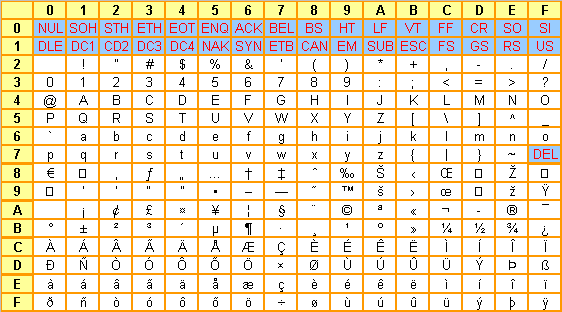
Comme vous pouvez le constater iciĀ :
- les codes ASCII de 0 Ć 7F (127 en dĆ©cimal) demeurent inchangĆ©sĀ ;
- les codes supĆ©rieurs (ceux qui ont le bit 7 Ć 1) reprĆ©sentent quelques symboles supplĆ©mentaires, ainsi qu'une panoplie de lettres accentuĆ©es qui satisfont aux exigences des langues de l'Europe de l'Ouest.
Pourquoi Ā«Ā Ć peu prĆØsĀ Ā»Ā ? Le codage ci-dessus est une interprĆ©tation de la norme ISO-8859-1 par notre ami Microsoft qui a un peu bricolĆ© pour ajouter quelques symboles de plus, dont celui de l'euroā€¦ La consĆ©quence en est qu'une fois de plus, Windows n'est compatible qu'avec lui-mĆŖme. Fort heureusement, nous verrons qu'il demeure possible d'adopter un codage plus officiel avec les applications communicantes, mais avec des limites. Notez que si l'on peut reprocher Ć Microsoft de ne pas suivre les normes, il faut aussi reprocher aux normes d'ĆŖtre imparfaites et assez peu rĆ©actives.
Pour ajouter Ć la complexitĆ©, la norme ISO-8859 dĆ©finit pas moins de 15 versions diffĆ©rentes, pour satisfaire Ć tous les besoins mondiaux. Ć€ titre d'information, la norme ISO-8859-15 devrait pouvoir ĆŖtre utilisĆ©e pour l'Europe de l'Ouest avec plus de Ā«Ā bonheurĀ Ā» que l'ISO-8859-1.
Finalement, ce bit de plus ne fait que dĆ©placer le problĆØme sans toutefois l'Ć©liminer, nous ne disposons toujours pas d'un systĆØme normalisĆ© universel.
III-B. Les as de la confusion▲
Croyez-vous que la situation est suffisamment confuse comme ƧaĀ ? Vous vous trompezĀ ! D'autres choses existent, souvent venant de chez IBM.
III-B-1. EBCDIC▲
Je me contenterai de vous citer la dĆ©finition issue du Ā«Ā jargon franƧaisĀ Ā»Ā :
Extended Binary Coded Decimal Interchange Code.
Jeu de caractĆØres utilisĆ© sur des dinosaures d' IBM . Il existe en 6 versions parfaitement incompatibles entre elles, et il y manque pas mal de points de ponctuation absolument nĆ©cessaires dans beaucoup de langages modernes (les caractĆØres manquants varient de plus d'une version Ć l'autreā€¦) IBM est accusĆ© d'en avoir fait une tactique de contrĆ´le des utilisateurs. (Ā© Jargon File 3.0.0).
Il existe quelques Ā«Ā moulinettesĀ Ā» capables de convertir tant bien que mal des fichiers codĆ©s sous cette forme en fichiers ASCII.
Bien que l'EBCDIC soit aujourd'hui tout Ć fait confidentiel, puisqu'il ne concerne que les vieilles machines IBM, il faut en tenir compte pour les Ć©changes de donnĆ©es inter plateformes, jusqu'Ć extinction totale de la race (nous ne devons plus en ĆŖtre trĆØs loin).
III-B-2. Pages de codes 437 et 850▲
Lorsque IBM a crĆ©Ć© le PC (Personal Computer, faut-il le rappelerĀ ?), des jeux de caractĆØres ont Ć©tĆ© crĆ©Ć©s sur 8 bits, spĆ©cifiquement pour ces machines. Ci-dessous la page de code 437 (CP437). Attention, ce tableau se lit dans l'autre sens, le quartet de poids faible est celui de la ligne et le quartet de poids fort est celui de la colonne.

Tous les petits Ā«Ā grigrisĀ Ā» Ć partir du code B0 Ć©taient destinĆ©s Ć faire de l'art ASCII Ć©tendu. De jolies interfaces pseudo graphiques sur des terminaux en mode texte.
Si cette page de code est compatible avec l'ASCII US 7 bits (ISO-646) il n'en est rien pour le reste, avec aucune ISO-8859. Cette situation a Ć©tĆ© assez pĆ©nalisante, aux dĆ©buts de Windows, oĆ¹ l'on devait souvent jongler avec les fichiers issus d'applications DOS et Windows.
III-C. Reconstruire la tour de Babel▲
Et si l'on construisait une table de codage sur 16 bits et pourquoi pas mĆŖme 32 bitsĀ ? LĆ , on aurait de la place pour entrer dans une seule et unique table tous les symboles que l'espĆØce humaine a pu inventerā€¦
Rassurez-vous, on y a dĆ©jĆ pensĆ©, ceci s'appelle l'Unicode et le projet fait mĆŖme l'objet d'une normalisation, ISO-10646-1.
Pour quoi faire, me direz-vousĀ ? Avons-nous besoin de manipuler dans un mĆŖme document tous les symboles d'Ć©criture que ce monde a inventĆ©sĀ ?
Il y a au moins deux bonnes raisons qui militent en faveur d'UnicodeĀ :
- si tout le monde utilise Unicode, il n'y a plus de problĆØmes, tout le monde peut Ć©crire dans sa langue maternelle en utilisant la mĆŖme conventionĀ ;
- les pauvres gens qui font de la traduction de documents d'une langue dans une autre n'auront plus Ć jongler en permanence avec les divers ISO-8859 pour rĆ©diger leur travail.
Cependant Unicode utilisĆ© brutalement aboutirait Ć un quadruplement du volume pour un document donnĆ©, chaque caractĆØre Ć©tant dĆ©sormais encodĆ© sur 32 bits et non plus 8, le tout avec probablement plein de zĆ©ros et quelques octets constants dans chaque document. Une solution Ć ce petit problĆØme s'appelle UTF-8. Notez que pour nous, EuropĆ©ens, qui utilisons l'alphabet latin, UTF-8 ne sera pas trop pĆ©nalisant en termes de volume de donnĆ©es. Pour d'autres, chinois ou japonais par exemple, le problĆØme sera diffĆ©rent.
Cette normalisation, bien que complexe, est en voie de devenir l'usage courant. Ce n'est pas encore le cas partout, et comme ce codage n'est compatible avec les autres que sur les 127 premiers symboles (ASCII), nous n'avons pas encore fini de voir des choses comme Ā«Ā De la difficultĆ© avĆ©rĆ©e du bon amĆ©nagement des caractĆØres dans l'encodage numĆ©riqueĀ Ā» fleurir dans nos e-mails et sur certaines pages du web.
La raisonĀ ? Le texte a Ć©tĆ© encodĆ© en UTF-8 et, pour une raison quelconque, a Ć©tĆ© interprĆ©tĆ© par le client comme de l'ISO-8859-1. Notez que l'inverse peut aussi se produire et reste aussi inesthĆ©tique.
III-D. Conclusion provisoire▲
Comme vous le voyez, nous sommes encore loin de disposer d'un systĆØme de codage efficace des divers symboles utilisĆ©s dans le monde pour communiquer. La situation paraĆ®t dĆ©jĆ assez dĆ©sespĆ©rante, sinon dĆ©sespĆ©rĆ©e, mais rassurez-vous, nous n'avons pas encore tout vu. Notons tout de mĆŖme queĀ :
- les derniĆØres moutures de MS Windows (Vista, Seven) semblent vouloir se conformer Ć UTF-8Ā ;
- la plupart des distributions GNU/Linux sont configurĆ©es par dĆ©faut pour utiliser UTF-8Ā ;
- les Ā«Ā browsersĀ Ā» modernes savent afficher correctement du code UTF-8 pour peu qu'ils soient informĆ©s correctement qu'ils reƧoivent un tel codage.
Dans ces conditions, le pire est peut-ĆŖtre dĆ©jĆ derriĆØre nousĀ ? Pour autant, nous ne sommes pas encore sortis de ce bourbier.
NoteĀ : les passionnĆ©s de la chose trouveront ici beaucoup de dĆ©tails sur les divers codages existants.
IV. Autres astuces▲
IV-A. Code toujours, tu m'intĆ©resses▲
Par une remarquable tendance Ć la perversitĆ© de l'esprit humain, certains protocoles Ā«Ā applicatifsĀ Ā» (SMTP par exemple) ont Ć©tĆ© conƧus avec comme axiome de dĆ©part qu'ils ne devraient transporter que du texte, alors qu'il est clair qu'ils n'auraient Ć transporter que des valeurs numĆ©riques binaires, puisqu'un systĆØme numĆ©rique ne sait finalement faire que cela.
D'ailleurs, le premier besoin qui s'est fait sentir, c'est de pouvoir attacher aux e-mails des fichiers qui sont tout, sauf du texte pur.
Pourquoi le parti-pris du texteĀ ?
Ć€ cause des caractĆØres de contrĆ´leĀ ! C'est trĆØs pratique de disposer de caractĆØres spĆ©ciaux qui permettent, comme leur nom l'indique, de contrĆ´ler le flux de donnĆ©es. Avec le codage ASCII, nous avons vu qu'il en existait pas mal, mĆŖme si nous ne sommes pas entrĆ©s dans le dĆ©tail de leur signification.
De plus, nous n'avons pas parlĆ© du codage des valeurs numĆ©riques. Si un nombre entier ne pose pas trop de problĆØmes (1, 2 octets ou plus, Ć©ventuellement, encore que reste Ć savoir dans quel ordre on va les passer), les nombres rĆ©els, codĆ©s sous la forme mantisse exposant est un rĆ©el casse-tĆŖte. Un exemple faux, mais qui fait comprendreĀ : Le nombre 1Ā 245Ā 389Ā 789Ā 726Ā 986Ā 425 ne va pas s'utiliser ainsi, on va d'abord l'Ć©crire, par exemple sous la forme 1245,389789726986425 1015. On s'attachera alors Ć stocker en mĆ©moire ce rĆ©el sous une forme approchĆ©e en utilisant systĆ©matiquement, disons trois octets. Sa partie entiĆØre, 1245 dans l'exemple, sera codĆ©e sur deux octets et la puissance de 10, 15 dans l'exemple, sur un octet.
Cet exemple n'a pas de rĆ©alitĆ©, mais le principe est Ć peu prĆØs juste. Suivant les plateformes et les langages de programmation, nous aurons nos rĆ©els stockĆ©s sur 4, 6 ou 8 octets, avec plus ou moins de prĆ©cision sur la mantisse, ou plus ou moins d'espace sur la puissance de 10, suivant la nature des calculs Ć rĆ©aliser (aviez-vous pensĆ© que la notion d'infini ne peut ĆŖtre gĆ©rĆ©e par un calculateurĀ ?). Finalement, il est souvent plus simple de communiquer des valeurs numĆ©riques Ć un tiers sous leur forme ASCII (telles qu'on peut les afficher ou les imprimer, avec des symboles d'Ć©criture, donc), plutĆ´t que telles qu'elles sont stockĆ©es en mĆ©moire.
La consĆ©quenceĀ ?
Ces protocoles ne peuvent pas simplement transfĆ©rer des donnĆ©es numĆ©riques, puisqu'un octet est Ć priori considĆ©rĆ© comme l'image d'un caractĆØre et non comme une donnĆ©e numĆ©rique en elle-mĆŖme. Ainsi, si vous voulez transfĆ©rer un fichier qui contient une reprĆ©sentation Ā«Ā bitmapĀ Ā» d'une image, comme un fichier JPEG, PNG ou GIF, par exemple, vous ne pouvez pas considĆ©rer que c'est du texte, puisquā€™Ć priori, chaque octet peut prendre n'importe quelle valeur, y compris celle d'un caractĆØre de contrĆ´le. Vous connaissez beaucoup de pages Web sans aucune image dedansĀ ? Vous n'avez jamais envoyĆ© un e-mail avec une image en piĆØce jointeĀ ?
La conclusion est qu'il a fallu trouver une astuce pour transporter des donnƩes purement numƩriques sur un protocole qui n'est pas prƩvu pour Ƨa.
IV-B. Codage Ć tous les Ć©tages▲
Le jeu va consister maintenant Ć coder une donnĆ©e purement numĆ©rique sous une forme alphabĆ©tique, elle-mĆŖme codĆ©e sur des valeurs numĆ©riques, pour qu'elle puisse ĆŖtre transportĆ©e sur un systĆØme qui ne connaĆ®t que des 0 et des 1.
Tordu, n'est-ce pasĀ ?
Oui, mais comment faire autrementĀ ? Les rĆ©volutions, c'est bien, mais on ne peut pas en faire tous les jours, sinon, c'est le chaos permanent. Vous allez voir que les solutions apportĆ©es sont certes parfois tordues, mais astucieuses et surtout efficaces.
Comme il est clair, Ć la lueur de ce que nous avons vu jusqu'ici, que la seule convention qui soit Ć peu prĆØs universellement acceptĆ©e et correctement transportĆ©e par les protocoles applicatifs est la norme ISO-646 (US-ASCII), il faudra trouver des conventions de codage pour convertir un octet en un ensemble de caractĆØres sur 7 bits.
C'est parti pour la grande cuisine.
IV-B-1. Le codage Ā«Ā quoted printableĀ Ā»▲
Ce codage est principalement employĆ© pour transformer un texte Ć©crit avec un codage sur 8 bits en un texte qui ne contiendra que des caractĆØres codables sur 7 bits. Vous allez voir comme c'est simpleĀ :
d'abord, il faut savoir sur quel codage 8 bits on va s'appuyer, en gƩnƩral, pour nous, sur l'ISO-8859-1.
Ensuite, nous allons utiliser un Ā«Ā code d'Ć©chappementĀ Ā» (c'est une technique assez courante, nous la rencontrons souvent en informatique). Ici, le caractĆØre d'Ć©chappement est le signe =. Ce signe signifie que les deux caractĆØres qui vont le suivre reprĆ©senteront le code hexadĆ©cimal d'un caractĆØre et non le caractĆØre lui-mĆŖme. Bien entendu, il faudra aussi coder le caractĆØre d'Ć©chappement.
Un petit exemple vaudra bien mieux qu'un long discoursā€¦
- Le Ć© dont le code 8 bits est E9, sera codĆ© sur trois caractĆØres de 7 bits de la faƧon suivanteĀ : =E9Ā ;
- De la mĆŖme faƧon, le ĆØ sera codĆ© =E8Ā ;
- Le Ƨ donnera =E7Ā ;
- Le Ć donnera =E0Ā ;
- Comme le = revĆŖt une signification particuliĆØreĀ : c'est le code d'Ć©chappement, il sera lui-mĆŖme codĆ© en =3D.
L'expression Ć§Ć et lĆ sera donc transmise sous la forme =E7=E0 et l=E0.
Ainsi, nous transporterons nos donnĆ©es uniquement sous la forme de caractĆØres US-ASCII (7 bits), mĆŖme s'ils nĆ©cessitent 8 bits pour ĆŖtre dĆ©finis. En effet, les caractĆØres =, E, et 0 ont tous des codes ASCII sur 7 bits.
Astucieux nonĀ ?
Bien entendu, il vaut mieux le savoir pour dĆ©coder correctement le message. Cette mĆ©thode est utilisĆ©e principalement pour les e-mails. En voici un exempleĀ :
Return-Path:
...
From: "Christian Caleca"
To:
Subject: quoted
Date: Tue, 5 Nov 2002 10:51:34 +0100
MIME-Version: 1.0
Content-Type: text/plain;
charset= "iso-8859-1"
Content-Transfer-Encoding: quoted-printable
...
X-Mailer: Microsoft Outlook Express 6.00.2800.1106
X-MimeOLE: Produced By Microsoft MimeOLE V6.00.2800.1106
=E7=E0 et l=E0Notez que l'on parle ici de MIME, en indiquant, la nature du contenu (text/plain), le jeu de caractĆØres utilisĆ© (ISO-8859-1) et le mode d'encodageĀ : quoted-printable. Nous y reviendrons plus tard.
IV-B-1-a. Remarque▲
Aujourd'hui, la plupart des relais de messagerie utilisent ESMTP, qui est capable de transporter du texte sur 8 bits (ISO8859-1 et mĆŖme UTF-8). Cependant, ceci n'est possible que dans le corps du message et pas dans l'en-tĆŖte. Comme le sujet (Subject:) se trouve dans l'en-tĆŖte, il ne faudrait pas Ć©crire de sujets en utilisant autre chose que des codes sur 7 bits. Pour permettre Ć l'internaute d'user des accents dans les sujets, ceux-ci sont alors encodĆ©s en Ā«Ā quoted printableĀ Ā» par les clients de messagerie (MUA), avec des rĆ©sultats plus ou moins heureux.
IV-B-2. Le codage Base64▲
Plus gƩnƩralement, ce codage permettra de passer non seulement du texte codƩ sur 8 bits, mais aussi tout type de donnƩes constituƩes d'octets. Voyons d'abord avec du texte.
LĆ aussi, il faudra commencer par indiquer en quel code est Ć©crit le texte initial. Pour nous, toujours ISO-8859-1.
Trois caractĆØres de 8 bits (24 bits au total) sont dĆ©coupĆ©s sous la forme de quatre paquets de six bits (toujours 24 bits au total). Chaque valeur sur 6 bits, comprise donc entre 0 et 3F en hexadĆ©cimal, sera symbolisĆ©e par un caractĆØre prĆ©sent, et avec le mĆŖme code, dans toutes les versions de code ASCII et EBCDIC. La table d'Ć©quivalence est celle qui suit. Remarquez que les caractĆØres choisis sont tous codĆ©s sur 7 bits en US-ASCII, mais que la valeur qu'ils reprĆ©sentent n'est pas leur code ASCIIĀ :
|
Dec |
Hex |
Car |
Dec |
Hex |
Car |
Dec |
Hex |
Car |
Dec |
Hex |
Car |
|||
|
0 |
0 |
A |
16 |
10 |
Q |
32 |
20 |
g |
48 |
30 |
w |
|||
|
1 |
1 |
B |
17 |
11 |
R |
33 |
21 |
h |
49 |
31 |
x |
|||
|
2 |
2 |
C |
18 |
12 |
S |
34 |
22 |
i |
50 |
32 |
y |
|||
|
3 |
3 |
D |
19 |
13 |
T |
35 |
23 |
j |
51 |
33 |
z |
|||
|
4 |
4 |
E |
20 |
14 |
U |
36 |
24 |
k |
52 |
34 |
0 |
|||
|
5 |
5 |
F |
21 |
15 |
V |
37 |
25 |
l |
53 |
35 |
1 |
|||
|
6 |
6 |
G |
22 |
16 |
W |
38 |
26 |
m |
54 |
36 |
2 |
|||
|
7 |
7 |
H |
23 |
17 |
X |
39 |
27 |
n |
55 |
37 |
3 |
|||
|
8 |
8 |
I |
24 |
18 |
Y |
40 |
28 |
o |
56 |
38 |
4 |
|||
|
9 |
9 |
J |
25 |
19 |
Z |
41 |
29 |
p |
57 |
39 |
5 |
|||
|
10 |
A |
K |
26 |
1A |
a |
42 |
2A |
q |
58 |
3A |
6 |
|||
|
11 |
B |
L |
27 |
1B |
bn |
43 |
2B |
r |
59 |
3B |
7 |
|||
|
12 |
C |
M |
28 |
1C |
c |
44 |
2C |
s |
60 |
3C |
8 |
|||
|
13 |
D |
N |
29 |
1D |
d |
45 |
2D |
t |
61 |
3D |
9 |
|||
|
14 |
E |
O |
30 |
1E |
e |
46 |
2E |
u |
62 |
3E |
+ |
|||
|
15 |
F |
P |
31 |
1F |
f |
47 |
2F |
v |
63 |
3F |
/ |
Comme cette explication doit paraĆ®tre fumeuse Ć plus d'un (moi-mĆŖme, plus je la relis, plus je la trouve fumeuse), lĆ encore, prenons un exemple. Soit Ć coder le texte extrĆŖmement simpleĀ : 012
Ce texte est destinĆ© Ć ĆŖtre Ć©crit avec un codage ISO-8859-1.
|
caractĆØre initial |
0 |
1 |
2 |
|
Code ASCII hexa |
30 |
31 |
32 |
|
Code ASCII binaire |
00110000 |
00110001 |
00110010 |
Bien, nous avons donc la suite de 24 bits suivanteĀ : 001100000011000100110010. Nous allons maintenant la couper en quatre morceaux de 6 bitsĀ :
|
les valeurs sur 6 bits |
001100 |
000011 |
000100 |
110010 |
|
Ɖquivalent hexadƩcimal |
0C |
03 |
04 |
32 |
|
CaractĆØre Ć©quivalent en Base64 |
M |
D |
E |
y |
Et voilĆ . 012 donne, une fois codĆ© en Base 64 MDEy. Constatez comme c'est simple. Constatez surtout que ces caractĆØres seront transcrits en US-ASCII, donc sur 7 bits.
Pour dƩcoder, il suffit de le faire dans l'autre sens.
Refaisons la manip avec un e-mail codĆ© en Base64Ā :
Return-Path:
...
From: "Christian Caleca"
To:
Subject: Base 64 (1)
Date: Tue, 5 Nov 2002 11:07:11 +0100
MIME-Version: 1.0
Content-Type: text/plain;
charset= "iso-8859-1"
Content-Transfer-Encoding: base64
...
X-Mailer: Microsoft Outlook Express 6.00.2800.1106
X-MimeOLE: Produced By Microsoft MimeOLE V6.00.2800.1106
MDEyEt voilĆ le travail.
Ƈa, c'est une dĆ©mo Ā«Ā commercialeĀ Ā», c'est-Ć -dire, qui ne montre que ce qui est facile et qui marche bien. Vos messages contiennent tous un nombre de caractĆØres qui est un exact multiple de troisĀ ?
Dans ce cas (nombre de caractĆØres qui n'est pas un multiple de trois), le systĆØme de codage va Ā«Ā remplir le trouĀ Ā» avec un caractĆØre spĆ©cial, qui ne sera pas interprĆ©tĆ© Ć l'arrivĆ©e. Ce caractĆØre est le signe =
Voyons ce que Ƨa donne si le texte initial ne contient plus que le seul caractĆØre 0.
- Le premier groupe de 6 octets sera toujours le mĆŖmeĀ : 001100 qui donne MĀ ;
- Le second seraĀ : 00 (complĆ©tĆ© avec des 0, doncĀ : 000000) qui donne AĀ ;
- Comme il faut 24 bits quand mĆŖme, on ajoutera deux fois le caractĆØre =.
Au total, on aura MA==.
VĆ©rification par l'e-mailĀ :
Return-Path:
...
From: Ā«Ā Christian CalecaĀ Ā»
To:
Subject: base 64 (3)
Date: Tue, 5 Nov 2002 11:18:06 +0100
MIME-Version: 1.0
Content-Type: text/plain;
charset=Ā Ā»iso-8859-1Ā Ā»
Content-Transfer-Encoding: base64
...
X-Mailer: Microsoft Outlook Express 6.00.2800.1106
X-MimeOLE: Produced By Microsoft MimeOLE V6.00.2800.1106
MA==CQFDĀ !
Nous verrons que ce codage base64, qui permet de transformer tout octet en un Ć©quivalent ASCII, permettra par exemple de coder des piĆØces jointes de types divers dans les e-mails.
IV-B-3. Et les autresā€¦▲
IV-B-3-a. Uuencode▲
Bien entendu, d'autres conventions existent, mais n'appartiennent pas au systĆØme MIME. Par exemple Uuencode, assez proche de Base64, mais antĆ©rieur, utilisĆ© sur plateformes Unix.
IV-B-3-b. BinHex▲
Un codage propriĆ©taire, crĆ©Ć© dans le monde Macintosh pour les mĆŖmes raisonsā€¦
Vous le voyez, les astuces ne manquent pas pour utiliser exclusivement de l'ASCII 7 bits dans le transport de n'importe quelle donnƩe.
IV-C. Conclusion▲
En plus du codage des caractĆØres dans des tables de 7, 8 ou plus, il faut donc ajouter des systĆØmes qui vont s'efforcer de reprĆ©senter tout type de donnĆ©es sous forme de texte 7 bits.
Ceci nous amĆØne naturellement Ć parler de MIMEā€¦
V. Dans le HTML▲
V-A. Les pieds dans la toile▲
Bien que pour HTTP, protocole apte Ć transmettre des flux d'octets sans considĆ©rer que ce sont forcĆ©ment des caractĆØres, bon nombre de problĆØmes sont Ć rĆ©soudre.
Le langage HTML (Hyper Text Markup Language), lui aussi, propose des mĆ©thodes particuliĆØres pour traiter les caractĆØres non US-ASCII. Il rĆØgne d'ailleurs dans ce domaine la plus grande confusion.
Avec la version 3.2 du HTML, il n'y avait normalement pas d'autre possibilitĆ© que de passer par un transcodage du type Ā«Ā signes nommĆ©sĀ Ā». Depuis la version 4.0 de HTML, il est thĆ©oriquement possible de dĆ©finir dans l'en-tĆŖte du document quel jeu de caractĆØres est utilisĆ©.
Comme HTML est probablement le lieu oĆ¹ les normes sont les moins respectĆ©es, il convient tout de mĆŖme de rester prudent. Car, croyez-vous que le fait de pouvoir utiliser UTF-8, ISO-8859-1, ISO-8859-15 ou autres, simplement en annonƧant la chose dans l'en-tĆŖte HTMLĀ ?
Voyons ceciā€¦
Dans la page que nous avons sous les yeux, il est Ć©critĀ :
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
...
</head>En voyant ceci, notre Ā«Ā browserĀ Ā» va comprendre qu'il faut utiliser UTF-8 et, normalement, il n'y a pas de problĆØme, Ć la condition bien entendue que le texte qui a Ć©tĆ© introduit dans ce wiki soit bien encodĆ© en UTF-8.
Mais en cas de dĆ©saccord entre la saisie et l'affichage, la phraseĀ :
Nous avons Ć©tĆ© abusĆ©s par le systĆØmePourrait devenir ceciĀ :
Nous avons Ć©tĆ© abusĆ©s par le systĆØmeNettement moins lisible n'est-ce pasĀ ? Dans cet exemple, le texte a Ć©tĆ© encodĆ© en UTF-8 et dĆ©codĆ© en ISO-8859-1. Il s'agit bien sĆ»r d'une manipulation pour faire apparaĆ®tre ceci. Mais forcez donc votre navigateur Ć afficher cette page en ISO-8859-1ā€¦
Normalement, avec des choses comme le WIKI, le problĆØme ne se rencontre pas, sauf dans certains cas tordusā€¦
Si nous utilisons les Ā«Ā signes nommĆ©sĀ Ā», nous pouvons garantir plus d'interopĆ©rabilitĆ©, au prix d'un code source HTML nettement moins lisible.
V-A-1. Les signes nommĆ©s▲
Le principe est simpleĀ :
- Un caractĆØre d'Ć©chappementĀ : Le &Ā ;
- un nom pour le caractĆØre non US-ASCIIĀ ;
- un dĆ©limiteur de fin de codageĀ : le.
Un simple exemple, juste pour illustrer. Le Ć© devrait se coder dans le source HTMLĀ : &;eacute;
Vous trouverez beaucoup plus de dĆ©tails sur les signes nommĆ©s ainsi que sur beaucoup d'autres points du HTML sur le trĆØs instructif site SELFHTML.
Il existe une table de signes nommĆ©s dĆ©finie dans HTML 3.2. HTML 4.0 dĆ©finit des ajouts Ć cette table, bien que, thĆ©oriquement, une balise d'en-tĆŖte du typeĀ :
<meta http-equiv= "Content-Type" content= "text/html; charset=iso-8859-1">HTML devrait Ć elle seule permettre l'emploi de tous les symboles dĆ©finis par ISO-8859-1 (version 4.0 uniquement).
V-A-2. Une manipulation amusante▲
FrontPage 2000, (un Ć©diteur HTML de Microsoft), ne s'embarrassait pas de considĆ©rations complexes, annonƧait un charset=windows-1252 dans ses en-tĆŖtes et ne code aucun de ces symboles de faƧon particuliĆØre, mĆŖme pas l'euro.
D'autres Ć©diteurs, comme DreamWeaver (de Macromedia) ou Golive (d'Adobe) sont plus orthodoxes et, non seulement annonceront un Ā«Ā charset=ISO-8869-1Ā Ā», mais encore utiliseront les signes nommĆ©s pour les caractĆØres non US.
L'exemple qui suit est Ā«Ā bricolĆ©Ā Ā» directement dans le source HTML. La mĆŖme ligne sera codĆ©e selon diverses faƧonsĀ :
|
CaractĆØres |
codage |
|
|
Ć© ĆØ Ć§ Ć¹ Ć ĆŖ ā‚¬ |
Ć© ĆØ Ć§ Ć¹ Ć ĆŖ ā‚¬ (sans codage) |
FrontPage 2000 |
|
Ć© ĆØ Ć§ Ć¹ Ć ĆŖ ā‚¬ |
é è ç ù à ê € |
DreamWeaver 4 |
|
Ć© ĆØ Ć§ Ć¹ Ć ĆŖ ā‚¬ |
é è ç ù à ê € |
Golive 5 |
Normalement, il y a de grandes chances que vous voyez tout Ƨa correctement. Maintenant, si vous utilisez Internet Explorer, allez dans Ā«Ā AffichageĀ Ā», puis Ā«Ā CodageĀ Ā» et changez le codage par dĆ©faut. LĆ , vous risquez de voir les limites de FrontPage qui n'utilise pas systĆ©matiquement les signes nommĆ©s, mĆŖme si en thĆ©orie, HTML 4.0 devrait le permettre. Ceux qui n'utilisent pas IE doivent avoir quelque part une fonction Ć©quivalente, pour changer l'affichage par dĆ©faut.
Notez la curieuse faƧon de coder le symbole de l'euro par Golive 5Ā : €. c'est tout simplement sa valeur numĆ©rique, en hexadĆ©cimal, dans la normalisation Unicodeā€¦
V-A-3. Que penser de tout ƧaĀ ?▲
Il serait possible de pousser encore plus loin les investigations, et de supprimer dans l'en-tĆŖte de chaque page la dĆ©finition du Ā«Ā charsetĀ Ā», Ƨa ne changerait trĆØs probablement rien au rĆ©sultat final.
Vous le voyez, nous sommes ici dans le flou Ā«Ā artistiqueĀ Ā». Au bout du compte, mĆŖme en HTML 4.0, il semble de bon ton d'utiliser tout de mĆŖme systĆ©matiquement les signes nommĆ©s, mĆŖme si l'on peut s'en passer le plus souvent
V-B. Conclusion▲
Si vous n'avez pas encore attrapƩ le vertige, vous ne l'attraperez plus. Sinon, essayons de consolider un peu nos positions.
V-B-1. Les faits▲
- Les systĆØmes numĆ©riques ne savent traiter que des informations binaires, donc numĆ©riquesĀ ;
- Les protocoles applicatifs, le plus souvent, ont besoin de transporter du texteĀ ;
- Le texte est destinĆ© Ć ĆŖtre lu, donc Ć©crit, et n'est pas constituĆ© d'une collection de valeurs numĆ©riques, mais d'une collection de symboles graphiquesĀ : un alphabetĀ ;
- Il n'y a pas qu'un seul alphabet au monde,
- Les protocoles applicatifs peuvent avoir aussi Ć Ć©changer des donnĆ©es qui ne sont pas du texte (une image, du son, une vidĆ©oā€¦).
V-B-2. Les solutions▲
- Coder sur 7 bits un jeu de caractĆØres minimal (US-ASCII), mais il n'y a pas que l'amĆ©ricain dans le monde, et 128 valeurs ne suffisent pas pour des langues riches en lettres accentuĆ©esĀ ;
- Coder sur 8 bits, mais Ƨa ne suffit pas non plus pour toutes les langues possiblesĀ ;
- Coder en UTF-8.
V-B-3. Le bricolage▲
Le Ā«Ā bricolageĀ Ā» le plus propre consiste Ć utiliser un jeu de caractĆØres minimal et de coder les caractĆØres supplĆ©mentaires par une combinaison identifiable des caractĆØres de base. C'est cette solution qui est le plus souvent mise en Å“uvre, et elle donne finalement les meilleurs rĆ©sultats.
- Codage Ā«Ā quoted-printableĀ Ā» (e-mails, imprimantesā€¦)Ā ;
- Codage Ā«Ā Base64Ā Ā» (e-mails, fichiers pouvant contenir autre chose que du texte purā€¦)Ā ;
VI. MIME▲
VI-A. MIMEĀ : c'est quoiĀ ?▲
Multipurpose Internet Mail Extension. Comme son nom l'indique, c'est une suite d'extensions pour permettre, principalement aux e-mails, de transporter autre chose que du texte, Ć savoir, du son, des images, de la vidĆ©oā€¦ Autant de choses pour lesquelles la messagerie n'est Ć priori pas faite.
Ces extensions servent Ć©galement sur le web, lorsque l'on utilise HTTP pour transporter autre chose que du texte (ce qui est souvent le cas). Voyez le chapitre Ā«Ā HTTPĀ Ā» Ć ce propos.
MIME rassemble deux choses distinctesĀ :
- une description normalisĆ©e d'un type de document (non-texte pur)Ā ;
- le mode de codage employƩ pour le transporter.
L'IANA maintient une liste des MIME Media Types.
VI-A-1. MIME et SMTP▲
C'est ici que MIME prend toute son importance. En effet, en plus de pouvoir dƩfinir des types de documents, il peut aussi dƩfinir des types d'encodages, comme Base64 ou Quoted-Printable.
VI-A-1-a. Exemple▲
Un exemple significatif. Il reprendra ce que nous avons eu l'occasion de voir par ailleurs.
Le message contient le texteĀ :
juste un texte lĆ©gĆØrement accentuĆ©...
suivi d'une image gif.CodĆ© Quoted-Printable, suivi d'une image GIF en piĆØce jointe. Voici le message tel qu'il est reƧuĀ :
Return-Path: <christian.caleca@epikoi.net>
...
From: "Christian Caleca" <christian.caleca@epikoi.net>
To: <christian.caleca@epikoi.net>
Subject: demo MIME
Date: Sat, 9 Nov 2002 11:29:09 +0100
MIME-Version: 1.0
Content-Type: multipart/mixed;On est averti qu'il y aura plusieurs morceaux de types diffĆ©rentsā€¦
boundary="----=_NextPart_000_0044_01C287E3.38B13A20"Avec un sƩparateur bien dƩfini, que l'on ne peut confondre avec un plan de fraises des bois.
X-Priority: 3
X-MSMail-Priority: Normal
X-Mailer: Microsoft Outlook Express 6.00.2800.1106
X-MimeOLE: Produced By Microsoft MimeOLE V6.00.2800.1106
This is a multi-part message in MIME format.
------=_NextPart_000_0044_01C287E3.38B13A20
Content-Type: text/plain;
charset="iso-8859-1"
Content-Transfer-Encoding: quoted-printableLa partie texte, codĆ©e Ā«Ā quoted-printableĀ Ā»ā€¦
juste un texte l=E9g=E8rement accentu=E9...
suivi d'une image gif.VoilĆ qui est fait. L'image, maintenantĀ :
------=_NextPart_000_0044_01C287E3.38B13A20
Content-Type: application/octet-stream;
name="moineau1.gif"
Content-Transfer-Encoding: base64
Content-Disposition: attachment;
filename="moineau1.gif"Difficile d'ĆŖtre plus prĆ©cisĀ :
- typeĀ :flux d'octetsĀ ;
- nomĀ : moineau1.gifĀ ;
- codageĀ : Base64ā€¦
Suit maintenant le fichier binaire converti en base64Ā :
R0lGODlhcgH8APf/AP//////zP//mf//Zv//M///AP/M///MzP/Mmf/MZv/MM//MAP+Z//+ZzP+Z
...
...
...
GZACDvqwAvWAOgEBADs=
------=_NextPart_000_0044_01C287E3.38B13A20--Comme prĆ©vu, ce message contient bien deux partiesĀ :
- du texte pur, codĆ© en Quoted-PrintableĀ ;
- une image GIF, codƩe en Base64.
L'image, dans Outlook Express, va apparaƮtre sous le texte, sƩparƩe par un filet horizontal.
VI-A-1-b. Autre exemple▲
Plus moderne, avec Thunderbird, un message codĆ© en UTF-8, avec en plus un Ć© dans le sujetĀ :
Return-Path: <christian.caleca@epikoi.net>
...
Message-ID: <4A5071E0.7080308@epikoi.net>
Date: Sun, 05 Jul 2009 11:26:56 +0200
From: Christian Caleca <christian.caleca@epikoi.net>
User-Agent: Thunderbird 2.0.0.22 (X11/20090608)
MIME-Version: 1.0
To: Christian Caleca <christian.caleca@epikoi.net>
Subject: Objet =?UTF-8?B?YWNjZW50dcOp?=Observez la sale tĆŖte que prend le Ā«Ā Subject:Ā Ā», juste parce qu'il y a un accent dedans.
Le texte de l'objet Ć©tant tout simplementĀ : Ā«Ā Objet accentuĆ©Ā Ā»
Content-Type: multipart/mixed;
boundary="------------000609020506050905050804"
This is a multi-part message in MIME format.
--------------000609020506050905050804
Content-Type: text/plain; charset=UTF-8; format=flowed
Content-Transfer-Encoding: 8bitEt texte utilisant des symboles Ā«Ā spĆ©ciauxĀ Ā» confiĆ©s Ć UTF-8Ā :
- le copyrightĀ : Ā©Ā ;
- le Ā«Ā trade markĀ Ā»Ā : ā„¢.
Le tout suivi d'une image GIF.
--------------000609020506050905050804
Content-Type: image/png;
name="logogrenouille.png"
Content-Transfer-Encoding: base64
Content-Disposition: inline;
filename="logogrenouille.png"
iVBORw0KGgoAAAANSUhEUgAAABkAAAAZCAYAAADE6YVjAAAABHNCSVQICAgIfAhkiAAAAAlw
...
DH5ZAZkYjPyIry4bVPWnSb2mgoyCKiTCKSnh3tA6xJgPQTdgA0OQ/Q5lmEEdplpVO6Y0Gn9A
UwXwkkTpkzA+Vq56JMY/wI7p7P8P7DhAtpxfH8cAAAAASUVORK5CYII=
--------------000609020506050905050804--Il y a ici plusieurs choses intĆ©ressantes Ć noterĀ :
- l'abominable pirouette utilisĆ©e Ć cause de l'unique lettre accentuĆ©e dans l'objetĀ ;
- le texte du message est annoncĆ© comme Ć©tant codĆ© en UTF-8, et il n'y a effectivement aucun artifice employĆ© sur les caractĆØres spĆ©ciaux, pas de Ā«Ā quoted-printableĀ Ā» ni de Ā«Ā bases64Ā Ā» iciĀ ;
- dans la partie Ā«Ā imageĀ Ā», la directive MIME Content-Disposition: inline; indique que l'image doit ĆŖtre affichĆ©e dans le corps du message (inline) et non comme une piĆØce jointe.
VI-A-1-c. Note pour les e-mails▲
Selon toute logique, le codage Base64 devrait pouvoir ĆŖtre universellement exploitĆ© dans la messagerie, puisqu'il permet Ć coup sĆ»r de transporter correctement le message codĆ© (sur 7 bits) et dĆ©finit complĆØtement la table de codage ASCII quel que soit l'alphabet utilisĆ© par l'auteur. Cependant ESMTP prĆ©voit de transporter tout type d'encodage sur 8 bits. AssociĆ©e Ć MIME, cette fonctionnalitĆ© permet, pour du texte, de ne plus avoir Ć utiliser de conversion 8 bits -> 7 bits. Encore faut-il que le destinataire dispose d'un MUA capable de gĆ©rer de tels messages.
Finalement, nous pouvons observer tout un tas d'attitudes plus ou moins originales et plus ou moins logiques, dans la faƧon qu'ont les divers MUA de gĆ©rer les caractĆØres non US-ASCII et les piĆØces jointes.
La mode Ć©tant aux e-mails en HTML, nous pouvons trouver assez souventĀ :
Content-Type: text/html;
charset="iso-8859-1"
Content-Transfer-Encoding: quoted-printableContent-Type: text/html;
charset="windows-1252"
Content-Transfer-Encoding: quoted-printable(inutile de prƩciser l'origine du MUA responsable).
Content-Type: text/plain;
charset="iso-8859-1"
Content-Transfer-Encoding: quoted-printableISO-8859-1 est encodĆ© en quoted-printableĀ :
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: quoted-printableIci, c'est UTF-8 qui est utilisĆ©, mais encodĆ© Ć©galement en quoted-printableā€¦
Content-Transfer-Encoding: binary
Content-Type: text/plain;
charset="iso-8859-1"Ici, c'est plus simple, de l'ISO-8859-1 sans encodage particulier.
Je n'ai pas d'exemple sous la main, mais il est bien sĆ»r tout Ć fait possible de faireĀ :
Content-Type: text/plain; charset=UTF-8
Content-Transfer-Encoding: base64Vous le voyez, arriver Ć lire correctement un message d'apparence tout Ć fait anodine peut nĆ©cessiter de passer par d'Ć©normes usines Ć gaz.
VI-A-2. MIME et HTTP▲
Nous en avons dĆ©jĆ un exemple dans le chapitre HTTP, pour transporter une image GIF dans une page HTML. Mais dans ce cas, il n'y a pas de codage (type Base64 ou quoted-printable), les octets sont brutalement transportĆ©s par le protocole. MIME sert juste Ć dĆ©finir le type de document.
Voici juste un exemple, oĆ¹ HTTP va transporter un document MS Word. La manipulation est faite avec Internet Explorer 6 et Mozilla 1.1 sur une plateforme Windows disposant de MS Word. Un sniffeur regarde ce qu'il se passe au niveau HTTP.
Comme vous pouvez le constater, cet exemple est dĆ©jĆ ancien, mais bien que les outils soient dĆ©sormais obsolĆØtes, la dĆ©monstration reste valable.
VI-A-2-a. Avec Internet Explorer 6▲
Frame 4 (387 on wire, 387 captured)
...
Internet Protocol, Src Addr: 192.168.0.10, Dst Addr: 192.168.0.253
...
Hypertext Transfer Protocol
GET /odj.doc HTTP/1.1\r\n
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg,
application/vnd.ms-powerpoint, application/vnd.ms-excel,
application/msword, */*\r\nNous le savons, IE6 accepte explicitement les fichiers au format MS Office si ce dernier est installƩ.
Accept-Language: fr\r\n
Accept-Encoding: gzip, deflate\r\n
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)\r\n
Host: linux.maison.mrs\r\n
Connection: Keep-Alive\r\n
\r\nFrame 6 (1514 on wire, 1514 captured)
...
Internet Protocol, Src Addr: 192.168.0.253, Dst Addr: 192.168.0.10
...
Hypertext Transfer Protocol
HTTP/1.1 200 OK\r\n
Date: Sat, 09 Nov 2002 09:32:41 GMT\r\n
Server: Apache-AdvancedExtranetServer/1.3.26 (Mandrake Linux/6.1mdk)
auth_ldap/1.6.0 mod_ssl/2.8.10 OpenSSL/0.9.6g PHP/4.2.3\r\n
Last-Modified: Thu, 06 Jul 2000 15:07:29 GMT\r\n
ETag: "57d5a-7800-3964a0b1"\r\n
Accept-Ranges: bytes\r\n
Content-Length: 30720\r\n
Keep-Alive: timeout=15, max=100\r\n
Connection: Keep-Alive\r\n
Content-Type: application/msword\r\n
\r\nApache connaĆ®t le type MIME MS Word et signale le type de contenu, puis, commence Ć envoyer les donnĆ©es.
Data (1067 bytes)
0000 d0 cf 11 e0 a1 b1 1a e1 00 00 00 00 00 00 00 00 ................
0010 00 00 00 00 00 00 00 00 3e 00 03 00 fe ff 09 00 ........>.......
...Les octets surlignĆ©s montrent Ć l'Ć©vidence que HTTP transporte sur 8 bits
Une fois la rĆ©ception terminĆ©e, Internet Explorer va afficher directement le document, en utilisant MS Word comme Ā«Ā plug-inĀ Ā».
VI-A-2-b. Avec Mozilla 1.1▲
Frame 6 (534 on wire, 534 captured)
...
Internet Protocol, Src Addr: 192.168.0.10, Dst Addr: 192.168.0.253
...
Hypertext Transfer Protocol
GET /odj.doc HTTP/1.1\r\n
Host: linux.maison.mrs\r\n
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.0; en-US; rv:1.1)
Gecko/20020826\r\n
Accept: text/xml,application/xml,application/xhtml+xml,text/html;q=0.9,
text/plain;q=0.8,video/x-mng,image/png,image/jpeg,image/gif;q=0.2,
text/css,*/*;q=0.1\r\nMozilla ne connaĆ®t pas quant Ć lui les formats Microsoft. Il accepte cependant tout type de document (*/*).
Accept-Language: fr-fr, en-us;q=0.66, en;q=0.33\r\n
Accept-Encoding: gzip, deflate, compress;q=0.9\r\n
Accept-Charset: ISO-8859-1, utf-8;q=0.66, *;q=0.66\r\nPlus respectueux de HTTP, il indique les jeux de caractĆØres qu'il prĆ©fĆØre ISO-8859-1 (latin-1) d'abord, UTF-8 (unicode) ensuite, * (n'importe quoi) enfin.
Keep-Alive: 300\r\n
Connection: keep-alive\r\n
\r\nFrame 8 (1514 on wire, 1514 captured)
...
Internet Protocol, Src Addr: 192.168.0.253, Dst Addr: 192.168.0.10
...
Hypertext Transfer Protocol
HTTP/1.1 200 OK\r\n
Date: Sat, 09 Nov 2002 09:35:06 GMT\r\n
Server: Apache-AdvancedExtranetServer/1.3.26 (Mandrake Linux/6.1mdk)
auth_ldap/1.6.0 mod_ssl/2.8.10 OpenSSL/0.9.6g PHP/4.2.3\r\n
Last-Modified: Thu, 06 Jul 2000 15:07:29 GMT\r\n
ETag: "57d5a-7800-3964a0b1"\r\n
Accept-Ranges: bytes\r\n
Content-Length: 30720\r\n
Keep-Alive: timeout=15, max=100\r\n
Connection: Keep-Alive\r\n
Content-Type: application/msword\r\n
\r\n
Data (1067 bytes)
0000 d0 cf 11 e0 a1 b1 1a e1 00 00 00 00 00 00 00 0 ................
0010 00 00 00 00 00 00 00 00 3e 00 03 00 fe ff 09 00 ........>.......Rien de changĆ© de ce cĆ´tĆ©-lĆ . Mozilla, une fois le fichier reƧu proposera de l'enregistrer ou de l'afficher en dĆ©marrant MS Word, comme une application sĆ©parĆ©e.
VI-A-3. Anecdotes diverses▲
Il est souvent d'usage d'attribuer un suffixe correspondant Ć un type de fichier donnĆ©. Les images au format JPEG sont par exemple suffixĆ©es par .jpg ou encore .jpeg ou .jpe. Il peut ĆŖtre intĆ©ressant de dĆ©duire le type MIME du suffixe d'un fichier. Ainsi, sur une distribution GNU/Linux (ici Ubuntu 9.04, mais aussi Debian et sans doute ses autres dĆ©rivĆ©es), il existe un fichier /etc/mime.types'' crĆ©Ć© dans ce but. En voici le contenuĀ :
VI-B. Conclusions▲
Ce chapitre vous aura, je l'espĆØre, aidĆ© Ć mieux comprendreĀ :
- comment le Net arrive tout de mĆŖme plutĆ´t bien Ć se sortir Ć©lĆ©gamment du piĆØge permanent que prĆ©sente le transport de donnĆ©es au niveau mondialĀ ;
- certains messages que vos navigateurs web peuvent vous envoyer lorsque vous visitez des sites Ć©trangersĀ ;
- pourquoi certains mails que vous pouvez recevoir peuvent ĆŖtre illisibles, et, peut-ĆŖtre, comment y remĆ©dierĀ ;
- les prĆ©cautions qu'il faut prendre pour avoir de bonnes chances d'envoyer des e-mails lisibles par le plus grand nombreā€¦
VII. Remerciements Developpez▲
Vous pouvez retrouver l'article original iciĀ : L'Internet Rapide et Permanent. Christian Caleca a aimablement autorisĆ© l'Ć©quipe Ā«Ā RĆ©seauxĀ Ā» de Developpez.com Ć reprendre son article. Retrouvez tous les articles de Christian Caleca sur cette page.
Nos remerciements Ć zoom61 et sevyc64 pour leur relecture orthographique.
N'hĆ©sitez pas Ć commenter cet articleĀ ! 4 commentaires ![]()