


1. Introduction▲
Il ne sera pas question ici de dûˋcortiquer en profondeur les rouages du HTTP. Nous allons plutûÇt nous intûˋresser û certains aspects du ô¨ô surfô ô£. En effet, s'il constitue la pratique la plus courante sur le Net, (avec la messagerie), il n'en prûˋsente pas moins beaucoup de cûÇtûˋs qui peuvent sembler ô¨ô mystûˋrieuxô ô£.
Les crûˋateurs de sites web rivalisent d'ingûˋniositûˋ pour rûˋaliser des pages sophistiquûˋes, qui mettent en éuvre beaucoup de techniques pûˋriphûˋriques au protocole lui-mûˆme. Nous ne dûˋtaillerons pas toutes ces techniques, nous essayerons simplement de les prûˋsenter et de les dûˋmystifierãÎ
On parle beaucoup du respect de la vie privûˋe sur le Net. Nous verrons d'un peu plus prû´s les petites indiscrûˋtions qui sont pratiquûˋes par-ci par-lû .
Nous verrons ûˋgalement comment les documents sont demandûˋs et reûÏus, quelle est la part de travail du navigateur du client et celle du serveur du fournisseur d'informations.
Nous verrons ûˋgalement quelles techniques sont utilisûˋes pour accûˋlûˋrer la navigation, aussi bien du cûÇtûˋ du client (cache local) que de celui du fournisseur d'accû´s (serveurs proxy).
Le serveur proxy mûˋrite quelque attention. En effet, c'est un peu le couteau suisse de l'interconnexion entre un rûˋseau local et le Net, beaucoup de rûˋseaux locaux d'entreprise n'offrent l'accû´s au Net qu'û travers un proxy, pour diverses raisons dont nous verrons les plus importantes.
1-1. ûvitons dûˋjû une confusion▲
- HTTP (Hyper Text Transfert Protocol) est un protocole destinûˋ û transfûˋrer du texte (ou des fichiers quelconques, s'ils sont dûˋfinis par un format MIME) depuis un serveur vers un client. Initialement, il s'agissait bien de texte, sans illustrations, avec juste quelques possibilitûˋs d'enrichissement. Ceux qui utilisent un systû´me GNU/Linux pourront essayer un navigateur en mode texte comme Lynxô ;
- HTML (Hyper Text Markup Language) est un langage de description de document. Outre les possibilitûˋs d'enrichissement du texte comme les attributs gras, italique, soulignûˋ, les diffûˋrents niveaux de titre, il offre la bien connue possibilitûˋ de dûˋfinir des ô¨ô hyperliensô ô£ entre documents ou parties de documents.
Mûˆme s'il est clair que HTTP et HTML voient leurs destins intimement liûˋs, il s'agit bien de deux choses diffûˋrentesãÎ
HTTP est rûˋsolument orientûˋ ô¨ô fourniture de documentationô ô£. Entendons par lû que le but recherchûˋ est clairement (du moins initialement) de permettre û un client de trouver le document qui l'intûˋresse parmi la multitude d'informations stockûˋes sur des serveurs dont le rûÇle est de publier ces documents û l'intention de qui les cherche. HTTP gûˋnû´re un flux de donnûˋes pratiquement exclusivement dans le sens du serveur vers le client.
Aujourd'hui, la situation est un peu moins claire. Les usagers de l'Internet prennent une part de plus en plus active dans la crûˋation de contenu. Historiquement, la mise û jour du contenu d'un serveur HTTP se fait par un autre protocoleô : FTP (File Transfert Protocol). Cette mûˋthode prûˋsente deux inconvûˋnientsô :
- ce n'est pas d'une trû´s grande souplesse d'usageô ;
- lorsqu'un site est maintenu par plusieurs auteurs, la gestion des mises û jour peut devenir dûˋlicate.
Microsoft a ouvert le feu avec FrontPage, outil de crûˋation de documents HTML trû´s intuitif, permettant de mettre en ligne ses documents sur un serveur HTTP ô¨ô maisonô ô£, pourvu des fameuses ô¨ô extensions FrontPageô ô£. Il s'agit d'Internet Information Services, assez connu pour ses trous de sûˋcuritûˋ, du moins û ses dûˋbuts. L'extrûˆme simplicitûˋ d'emploi du couple FrontPage/IIS est malheureusement handicapûˋe par ces deux points fondamentauxô :
- cette solution, propriûˋtaire, oblige û n'utiliser que les technologies Microsoft, si l'on dûˋsire profiter de tous les avantages offertsô ;
- les difficultûˋs û maitriser la sûˋcuritûˋ de cette solution, surtout sur un serveur public.
Des alternatives libres apparaissent, qui tendent û intûˋgrer û HTTP des fonctions de transfert de fichiers du client vers le serveur, ainsi que des mûˋcanismes de gestion efficace des mises û jour. Ces solutions manquent toutefois encore de maturitûˋ et prûˋsentent elles aussi parfois de graves inconvûˋnients pour la sûˋcuritûˋ des serveurs û accû´s public. Aussi, nous passons d'une ûˋpoque oû¿ le contenu d'une page HTML ûˋtait ûˋcrit ô¨ô en durô ô£ de faûÏon statique, avec un outil spûˋcialisûˋ ou non, û une ûˋpoque oû¿ le HTML est gûˋnûˋrûˋ û la volûˋe par le serveur, de faûÏon dynamique, û partir d'informations stockûˋes dans des bases de donnûˋes ou dans des fichiers texte, comme c'est le cas pour ce site. Dans un tel cas, les donnûˋes sont mises û jour par des formulaires HTML et envoyûˋs au serveur par la mûˋthode ô¨ô POSTô ô£ que nous verrons plus loin.
Du point de vue du client, peu importe que les pages soient statiques oû¿ dynamiques, ce qu'il reûÏoit est toujours du HTML.
1-2. Regardons en arriû´re▲
Historiquement, il a existûˋ avant l'explosion du couple HTTP/HTML un autre outil permettant de servir simplement et efficacement des documents, il s'agissait du systû´me ô¨ô Gopherô ô£ô :ô Du nom de l'ûˋcureuil amûˋricain, aussi appelûˋ ô¨ô spermophileô ô£, vivant dans un dûˋdale de galeries. Le logiciel permettait de se promener dans le labyrinthe de l'Internet. Gofer signifie aussi en argot amûˋricain ô¨ô Go forô ô£, qui veut dire ô¨ô va chercherô ô£, et dûˋsignant un garûÏon de courses. (ôˋô Rheingold).Que les amoureux de l'histoire du Net se reportent au ô¨ô jargon franûÏaisô ô£, (d'oû¿ la dûˋfinition ci-dessus a ûˋtûˋ tirûˋe, voir aussi le Wikipûˋdia). Disons simplement que ce protocole n'a pas survûˋcu parce qu'il ûˋtait ô¨ô propriûˋtaireô ô£. En effet il appartenait û l'universitûˋ du Minnesota, qui menaûÏait de rûˋclamer des royalties pour son emploi. La rûˋplique fut immûˋdiateãÎ Gopher est mort(1).
1-3. Regardons en avant▲
Aujourd'hui, HTTP est certainement le protocole le plus utilisûˋ sur le Net et probablement le plus simple. C'est aussi certainement celui û qui l'on demande le plus. N'oublions pas qu'il est initialement conûÏu pour transporter du texte, avec des hyperliens. Or, que ne lui faisons-nous pas transporterãÎ Avec l'avû´nement du haut dûˋbit, les pages s'alourdissent et embarquent chaque jour des fioritures de plus en plus ûˋlaborûˋes, nûˋcessitant des ô¨ô plug-insô ô£ gûˋnûˋralement propriûˋtaires (Flash, Shockwave, Real, etc.).
2. Notions de base▲
2-1. Quels mûˋcanismes sont mis en éuvre dans le surfô ?▲
HTTP est donc un protocole somme toute assez simple par lui-mûˆme. Ce qui complique la comprûˋhension de l'ensemble des processus mis en éuvre, c'est toute ô¨ô l'intelligenceô ô£ qui est ajoutûˋe, tant du cûÇtûˋ serveur que du cûÇtûˋ client.
Au dûˋpart, un client envoie une requûˆte û un serveur HTTP et celui-ci y rûˋpond. Toute la difficultûˋ vient de deux aspects qui sont indûˋpendants du protocole HTTP lui-mûˆmeô :
- le traitement de l'information pratiquûˋ par le serveur avant d'envoyer le rûˋsultat de la requûˆteô ;
- le traitement de l'information pratiquûˋ par le client avant d'afficher le rûˋsultat de la requûˆte.
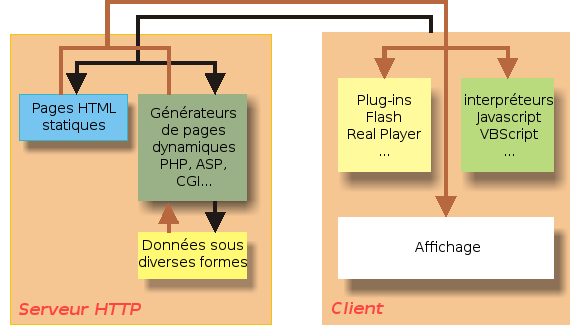
2-1-1. CûÇtûˋ serveur▲
Lorsqu'une requûˆte arrive sur le serveur, elle peut concernerô :
- une simple page HTML ô¨ô statiqueô ô£ (le suffixe de la page ûˋtant alors gûˋnûˋralement .htm ou .html). Tout son contenu est dûˋjû dûˋfini en HTML et le serveur n'a qu'û l'envoyer tel quel, au client. Dans cette configuration, un site web est fortement ressemblant au contenu d'un livre, il est ûˋcrit une fois pour toutes. Toute modification doit faire l'objet d'une rûˋûˋditionô ;
- une page HTML dont certains ûˋlûˋments sont ô¨ô dynamiquesô ô£, c'est-û -dire qu'ils sont construits û partir de sources d'informations diverses au moment de l'envoi au client. Ces mûˋthodes ont pour but de produire deux fournitures d'informations typiquement impossibles û rûˋaliser simplement avec des pages purement statiquesô :
- des informations qui sont le rûˋsultat d'un calcul û partir d'ûˋlûˋments que le client a transmis au serveur dans sa requûˆte,
- des informations issues d'une base de donnûˋes mise û jour par un moyen quelconque. Ces informations peuvent ûˋvoluer û tout instant et leur affichage via HTTP nûˋcessite leur intûˋgration en temps rûˋel dans le document,
- on peut bien entendu imaginer un document dont le contenu intû´gre les deux exercices prûˋcûˋdents.
Plusieurs possibilitûˋs existent pour rûˋaliser de telles opûˋrationsô :
- les exûˋcutablesô CGI (Common Gateway Interface).
Ces exûˋcutables construisent intûˋgralement un flux HTML au moment de leur appel. Cette technique, la plus ancienne, n'est pas forcûˋment la meilleure. Les exûˋcutables peuvent ûˆtre ûˋcrits dans un langage compilûˋ comme C ou dans un langage interprûˋtûˋ comme Perl, Python, Java, voire PHP (bien qu'il n'ait pas ûˋtûˋ initialement conûÏu pour cet usage). L'exûˋcutable est dûˋroulûˋ sur le serveur lui-mûˆme (ou sur un autre, mais ce n'est qu'un dûˋtail)ô ; - des langages plus ô¨ô spûˋcialisûˋsô ô£ comme PHP, JSP ou ASP.ô
Active Server Pages est une technologie Microsoft, alors que Personal Home Page est une technologie libre. Les deux sont sensiblement identiques au niveau des concepts, mais pas de la syntaxe.
Ces technologies sont dites ô¨ô Server Sideô ô£, c'est-û -dire que les traitements sur l'information sont effectuûˋs sur le serveur.
L'avantage du ô¨ô server sideô ô£ est que le code HTML reûÏu par le client est du HTML pur, ce qui veut dire qu'a priori, tout navigateur peut l'afficher correctement, sans trop de prûˋcautions particuliû´res de la part de l'auteur du site, si ce n'est au niveau de leur compatibilitûˋ avec les standards.
L'inconvûˋnient est que le serveur voit sa charge augmenter dans des proportions qui peuvent ûˆtre considûˋrables et qu'en cas de connexion lente, la navigation devient vite pûˋnible, lorsqu'il y a beaucoup de traitements d'informations introduites par le client, comme des calculs exûˋcutûˋs û partir de donnûˋes issues d'un formulaire.
2-1-2. CûÇtûˋ client▲
De ce cûÇtûˋ-lû aussi, des traitements d'informations peuvent ûˆtre utilesô :
- contrûÇler par exemple la validitûˋ des informations saisies dans un formulaire, avant de les envoyer au serveur. Ceci ûˋvite des allers-retours inutiles en cas de saisie erronûˋeô ;
- effectuer un traitement local de certaines informations pour afficher un rûˋsultat. Un exemple serait d'inclure une calculette dans une page web, cette calculette travaillant uniquement chez le client, sans jamais rien envoyer au serveur (nous verrons cet exemple plus loin)ô ;
- rûˋaliser toutes sortes d'opûˋrations susceptibles de rendre les pages visitûˋes plus vivantes, en introduisant des animations, des menus dûˋroulants et toutes sortes de ô¨ô gadgetsô ô£ propres û ûˋgayer (de faûÏon plus ou moins heureuse) une page web.
Lû encore, les donnûˋes peuvent ûˆtre traitûˋes, de diverses maniû´res.
- Les JavaScript.
Ces petits applicatifs, transmis dans le document HTML, sont exûˋcutûˋs cûÇtûˋ client par le navigateur. Malheureusement, chaque navigateur a une notion plus ou moins personnelle de l'interprûˋtation de JavaScript et c'est un vûˋritable casse-tûˆte pour le concepteur que d'ûˋcrire des scripts qui fonctionnent sur la totalitûˋ des navigateurs existants, mûˆme si un effort de standardisation a ûˋtûˋ entrepris sur les derniû´res versions (Internet Explorer 6 et plus, MozillaãÎ Mais il en existe beaucoup d'autres). - Les VBScripts.
C'est la mûˆme philosophie que pour le JavaScript, û part que c'est du Visual Basic, propriûˋtûˋ de Microsoft, qui ne fonctionne donc que sur Internet Explorer. Si la solution peut paraitre intûˋressante sur un Intranet, oû¿ l'on maitrise l'installation des postes clients, elle est bien entendu û proscrire sur l'Internet. - Les composants ActiveX qui sont des exûˋcutables compilûˋs, qui ne peuvent s'exûˋcuter eux aussi que dans Internet Explorer, c'est ûˋgalement une technologie propriûˋtaire de Microsoft. Trû´s intûˋressante sur le principe, elle n'est en pratique utilisable de faûÏon acceptable que sur un intranet.
- Les applets Java qui sont comparables aux composants ActiveX, mais qui ont des chances de s'exûˋcuter correctement sur tout navigateur, si une machine virtuelle Java est installûˋe. Ces deux technologies prûˋsentent malheureusement de gros risques de sûˋcuritûˋ.
- Les ô¨ô plug-inô ô£
Ce sont des composants enfichables qui ûˋtendent les possibilitûˋs intrinsû´ques des navigateurs, comme l'affichage de documents ô¨ô flashô ô£ par exemple.
Les avantages sont de deux sortesô :
- tout traitement de donnûˋes rûˋalisûˋ localement est rapide et sans surcharge pour le serveurô ;
- les effets d'animation, comme les menus dûˋroulants ou les bandeaux dûˋfilants ne peuvent ûˆtre que rûˋalisûˋs localement.
Les inconvûˋnients viennent des incompatibilitûˋs entre navigateurs et des trous de sûˋcuritûˋ introduits par des exûˋcutables tûˋlûˋchargûˋs sur le client, issus d'origines qui peuvent ûˆtre malveillantes.
Il n'est pas forcûˋment aisûˋ pour un surfeur de faire prûˋcisûˋment la part des choses dans tous ces mûˋcanismes qui peuvent se combiner avec plus ou moins de complexitûˋ (et de bonheur) au fil des sites visitûˋs.
Pour vous aider û mieux vous y retrouver, des exemples simples sont donnûˋs plus loin.
2-2. Quelques notions supplûˋmentaires▲
2-2-1. Le codage MIME▲
(Multipurpose Internet Mail Extension. Format de messages de l'Internet permettant de dûˋcouper un message en plusieurs parties et d'y inclure des donnûˋes non ASCII, û savoir du son, des imagesãÎ).
Dûˋfinition empruntûˋe au ô¨ô Jargon franûÏaisô ô£.
HTTP, un peu comme SMTP, ne sait pas nativement transporter autre chose que du texte. Il est bien connu de tous que le web propose aussi autre chose, comme des images (jpg, gif, pngãÎ), des animations et des documents aux formats plus ou moins particuliers (pdf, mpg, doc, xls, odt, odsãÎ). Client et serveur doivent se mettre d'accord sur un moyen de coder ces informations (serveur) et de les dûˋcoder (client) pour les afficher quand c'est possible, ou en proposer le tûˋlûˋchargement. Dans tous les cas, ces donnûˋes non textuelles doivent ûˆtre codûˋes et dûˋcodûˋes de faûÏon cohûˋrente.
2-2-2. Les cookies▲
Les cookies ne sont pas une mauvaise invention, c'est leur utilisation qui est parfois dûˋtournûˋe û des fins contestables.
Contrairement û ce que l'on peut penser, il n'existe pas de mûˋmoire dans la navigation web.ô Plus exactement, la notion de ô¨ô sessionô ô£ n'existe pas (mais ûÏa vient). Pour bien comprendre, prenons un exemple simpleô : vous entrez sur un site privûˋ qui nûˋcessite une authentification (nom d'utilisateur et mot de passe), a priori, sans l'aide des cookies, vous seriez probablement amenûˋ û vous identifier û chaque nouvelle page. Aujourd'hui d'autres techniques que le cookie sont dûˋveloppûˋes pour rûˋpondre û cette question. Il n'en demeure pas moins que le cookie montre encore son utilitûˋ dans bien des cas.
Le principe est simpleô : une fois authentifiûˋ, le serveur va dûˋposer chez vous un ô¨ô cookieô ô£ contenant des informations qu'il peut ensuite aller relire û chaque ouverture d'une nouvelle page, pendant toute la durûˋe de vie de ce cookie.
Normalement, il n'y a que le serveur qui a dûˋposûˋ un cookie qui peut aller le relire (ûˋventuellement un autre serveur du mûˆme domaine). Malheureusement, certains ont trouvûˋ des moyens pour extorquer aux clients des cookies dont ils ne sont pas û l'origine, ce qui constitue un risque de sûˋcuritûˋ, suivant les informations stockûˋes dans ce cookie.
2-2-3. Le passage par un proxy▲
Nous allons profiter de l'occasion pour tordre le cou û une confusion trop souvent rûˋpandue entre deux mûˋthodes qui permettent toutes deux l'accû´s au Net pour un rûˋseau local.
- Le routeur NAT d'un cûÇtûˋ.
Le routeur NAT agit au niveau IP. Il fonctionne pour tous les protocoles applicatifs comme HTTP, FTP, mais aussi POP, IMAP, SMTP, etc. (voir les chapitres dûˋdiûˋsô : Partage de connexion et NetFilter et IPtables), puisqu'il agit au niveau IP. - Le proxy de l'autre.
Le serveur proxy travaille, lui, au niveau du protocole applicatif lui-mûˆme. Un serveur proxy n'assure aucun routage au niveau IP. En franûÏais, on appelle ûÏa un serveur mandataire.
Pour l'exemple nous mettrons en éuvre un serveur proxy libre sous Linuxô : le trû´s cûˋlû´bre SQUID dans le chapitre qui lui est dûˋdiûˋô : Squid et SquidGuard.
3. Le protocole HTTP▲
3-1. Les versions du protocole▲
Les versions les plus utilisûˋes actuellement sont les versions 1.0 et 1.1, l'ûˋvolution suivante ûˋtant le XHTML qui apporte avant tout un peu plus de rigueur dans la syntaxe et un peu plus de cohûˋrence avec le XML, mais le principe reste exactement le mûˆme.
La version 1.1 de HTML introduit quelques commandes supplûˋmentaires, comme nous le verrons plus bas. La version 1.0 reste toutefois utilisable dans la plupart des cas actuellement.
3-1-1. Remarque prûˋliminaireô ▲
Une page est en principe dûˋfinie par un URI (Unified Ressource Identifier). On dit aussi URL (Unified Ressource Locator). Par exempleô : http://www.debian.org/doc/manuals/reference/ch-preface.fr.html. Nous savons que dans cet URI, il y a trois morceauxô :
- http:
qui indique quel protocole nous allons employerô ; - //www.debian.org
qui est censûˋ reprûˋsenter le serveur web contenant l'information que l'on rechercheô ; - /doc/manuals/reference/ch-preface.fr.html
qui reprûˋsente le chemin complet de la page visitûˋe dans l'arborescence du serveur concernûˋ.
Pourtant, si nous indiquons comme URI http://www.debian.org , il manque toute la partie correspondant au nom de la page. Cependant, nous arrivons bien û visualiser quelque choseãÎ Tout simplement, parce que le serveur est paramûˋtrûˋ pour ajouterô /index.html s'il n'y a pas le nom de la page. Ainsi, http://www.debian.org est ûˋquivalent û http://www.debian.org/index.html.
3-2. La dûˋmonstration▲
Nous allons voir tout ceci û travers quelques manipulations trû´s simples.
Pour rûˋaliser cette dûˋmonstration, un serveur web Apache est installûˋ sur mon rûˋseau privûˋ. L'hûÇte s'appelle poûˋtiquementô : linux.maison.mrs
Il contient une unique page HTML nommûˋe index.html. C'est la page qui est servie par dûˋfaut (les manipulations datent de 2002, sur un apache 1.3 et une distribution d'ûˋpoque (Mandrake), mais ici, le temps ne fait rien û l'affaire).
3-2-1. 1ô¯ On fait comme tout le mondeãÎ▲
CommenûÏons par faire ce que tout le monde faitô : utiliser son navigateur favori pour visiter cette page. Voici l'allure de cette trû´s belle page, telle qu'on l'obtient avec Internet Explorerô :
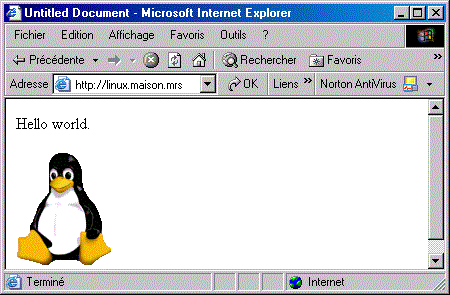
û titre indicatif, en voici le code HTML, tel qu'on peut l'obtenir en affichant le source depuis le navigateurô :
<html>
<head>
<title>Untitled Document</title>
<meta http-equiv= "Content-Type" content= "text/html; charset=iso-8859-1">
</head>
<body bgcolor= ô£#FFFFFF ô£ text= ô£#000000 ô£>
<p>Hello world.</p>
<p><img src="images/tux.gif" width= "97" height= "115"></p>
</body>
</html>Les puristes constateront que ce code n'est plus du tout conforme aux recommandations du W3C, mais la philosophie reste inchangûˋe.
3-2-2. 2ô¯ On fait avec TelnetãÎ▲
Essayons d'aller plus loin en trouvant un moyen de faire ô¨ô û la mainô ô£ ce que le navigateur fait automatiquement.
Nous sommes sur un protocole applicatif basûˋ sur TCP et, dans ce cas-lû , il est gûˋnûˋralement possible d'utiliser Telnet pour ûˋtudier un peu les commandesãÎ
3-2-2-1. La commande GET▲
Nous ouvrons une session Telnet sur le serveur HTTP de linux.maison.mrs (un serveur web ûˋcoute par convention sur le port 80).
telnet linux.maison.mrs 80
Trying 192.168.0.253...
Connected to linux.maison.mrs (192.168.0.253)
Escape character is '^]'.La session est ouverte. Utilisons maintenant la commande GETãÎ
GET / HTTP/1.0Nous la faisons en protocole 1.0, c'est un peu plus simple. Deux ô¨ô returnô ô£ pour validerãÎ Et voici qu'arrive la rûˋponse du serveur. Cette partie constitue l'en-tûˆte, systûˋmatiquement envoyûˋe par le serveurô :
HTTP/1.1 200 OK
Date: Wed, 08 May 2002 14:26:57 GMT
Server: Apache-AdvancedExtranetServer/1.3.23
(Mandrake Linux/4mdk) auth_ldap/1.6.0 mod_ssl/2.8.7 OpenSSL/0.9.6c PHP/4.1.2
Last-Modified: Sun, 14 Apr 2002 09:29:32 GMT
ETag: "57d44-116-3cb94bfc"
Accept-Ranges: bytes
Content-Length: 278
Connection: close
Content-Type: text/htmlLe serveur sait faire du HTTP 1.1. C'est un Apache version 1.3.23. Il annonce ûˋgalement ce qu'il sait faireô :
- authentification par annuaire LDAPô ;
- Secure Socket Layer en OpenSSL version 0.9.6cô ;
- interprûˋtation de code PHP version 4.1.2.
Il indique ûˋgalement La date GMT de derniû´re modification du document demandûˋ, qu'il mettra fin û la connexion TCP û la fin de l'envoi, et que le document fourni est au format MIMEô : text/html.
Et voici le document proprement ditô :
<html>
<head>
<title>Untitled Document</title>
<meta http-equiv= "Content-Type" content= "text/html; charset=iso-8859-1">
</head>
<body bgcolor= ô£#FFFFFF ô£ text= ô£#000000 ô£>
<p>Hello world.</p>
<p><img src="images/tux.gif" width= "97" height= "115"></p>
</body>
</html>Le message Connection closed by foreign host., issu de Telnet, indique que, par dûˋfaut, la connexion est interrompue par le serveur û la fin de l'envoi du document. L'option Connection: Keep-Alive aurait ûˋvitûˋ cette dûˋconnexion. Entendons-nous bien sur ce pointô : Nous parlons de la connexion TCP et en aucune faûÏon d'une ô¨ô sessionô ô£ au niveau de l'application.
Bienô ! Mais l'imageô ? Essayons de l'avoirãÎ
telnet linux.maison.mrs 80
Trying 192.168.0.253...
Connected to linux.maison.mrs (192.168.0.253).
Escape character is '^]'.
GET /images/tux.gif HTTP/1.0
Trying 192.168.0.253...
Connected to linux.maison.mrs (192.168.0.253).
Escape character is '^]'.
HTTP/1.1 200 OK
Date: Wed, 08 May 2002 14:44:17 GMT
Server: Apache-AdvancedExtranetServer/1.3.23
(Mandrake Linux/4mdk) auth_ldap/1.6.0 mod_ssl/2.8.7 OpenSSL/0.9.6c PHP/4.1.2
Last-Modified: Sun, 14 Apr 2002 09:29:32 GMT
ETag: ô¨ cf98a-a20-3cb94bfc ô£
Accept-Ranges: bytes
Content-Length: 2592
Connection: close
Content-Type: image/gif
GIF89aasûÎ????…/IHGôÈHIûÙû?û
?2›i?º…??gpôˋ:<…f?×ôË?ûHL§v?‹ˆû´û´û¥?ˆ”ôˋ?ô¯››¡ô£¹û
Ø ?ûû×rI?
(''}y|]?û8:ôç}?–y}ûX_û•!?‰ô hnû??N4?û´×?XXZûýô£?W????98;ýýû£hgjºx‚¹™?ûÇû?ô¨Y^„ZXbE?
ôˋ¶ûûû¨û ³L„hhû™?…NE?4ûûû•XYªy‚U<?ûé?ûÈôˋ??˜...
...
Connection closed by foreign host.Lû , il ne fallait tout de mûˆme pas s'attendre û des miracles, avec une console en mode texte. On a bien reûÏu l'image, le type MIME (image/gif) est bien signalûˋ, mais il n'est pas possible de la visualiser avec Telnet.
3-2-3. 3ô¯ On espionne avec le sniffeurãÎ▲
3-2-3-1. Comment travaille le navigateurô ?▲
Il a fait exactement la mûˆme chose que nousô :
- il appelle la page d'accueil GET / HTTP/1.0 (ûˋventuellement HTTP/1.1, mais alors, suivant la dûˋfinition de cette version HTTP, il devra au moins envoyer aussi le nom d'hûÇte du serveur interrogûˋ)ô ;
- une fois la page reûÏue, il va chercher dedans tous les URI, ici celui de l'image, et va les appeler avec un GET. Dans le cas de l'image, il devra la recomposer, ce qui lui est possible parce qu'il connaûÛt le format d'encodage gifô ;
- il affiche alors la page, dans son intûˋgralitûˋ.
3-2-3-2. Premiû´re observation de la conversation▲
Nous appelons la page avec Internet Explorer et le sniffeur va enregistrer ce qu'il se passe. Les trames surlignûˋes sont celles qui sont propres û HTTP. Mais n'oublions pas que HTTP s'appuie sur TCP, raison pour laquelle les autres trames existentô :
No. Time Source Destination Proto Info
1 0.000000 192.168.0.10 192.168.0.253 TCP 1282 > 80 [SYN]
2 0.000163 192.168.0.253 192.168.0.10 TCP 80 > 1282 [SYN, ACK]
3 0.000565 192.168.0.10 192.168.0.253 TCP 1282 > 80 [ACK]
4 0.001410 192.168.0.10 192.168.0.253 HTTP GET / HTTP/1.1
5 0.001487 192.168.0.253 192.168.0.10 TCP 80 > 1282 [ACK]
6 0.068550 192.168.0.253 192.168.0.10 HTTP HTTP/1.1 200 OK
7 0.098435 192.168.0.10 192.168.0.253 HTTP GET /images/tux.gif HTTP/1.1
8 0.098593 192.168.0.253 192.168.0.10 TCP 80 > 1282 [ACK]
9 0.099450 192.168.0.253 192.168.0.10 HTTP HTTP/1.1 200 OK
10 0.099724 192.168.0.253 192.168.0.10 HTTP Continuation
11 0.102794 192.168.0.10 192.168.0.253 TCP 1282 > 80 [ACK]
12 0.102915 192.168.0.253 192.168.0.10 HTTP Continuation
13 0.280331 192.168.0.10 192.168.0.253 TCP 1282 > 80 [ACK]- La trame 4 reprûˋsente la premiû´re requûˆte du client.
- La trame 6 renvoie le document demandûˋ, c'est-û -dire la page d'accueil du site.
- La trame 7 indique une requûˆte supplûˋmentaire pour l'image.
- Les trames 9, 10 et 12 reprûˋsentent l'envoi par le serveur de l'image demandûˋe. Les donnûˋes sont trop volumineuses pour entrer dans une seule trame. Ici, il en faut trois.
3-2-3-3. La premiû´re requûˆte HTTP▲
Pour cette premiû´re analyse, je laisse volontairement la totalitûˋ de la trame, afin de bien montrer que HTTP est un protocole ô¨ô applicationô ô£, qui s'appuie sur TCP/IP, lui-mûˆme s'appuyant sur Ethernet dans cet exemple. Avec une connexion PPPoE, on aurait une couche supplûˋmentaire introduite par PPP
Frame 4 (380 on wire, 380 captured)
Arrival Time: Apr 13, 2002 16:07:10.266248000
Time delta from previous packet: 0.000861000 seconds
Time relative to first packet: 0.001408000 seconds
Frame Number: 4
Packet Length: 380 bytes
Capture Length: 380 bytes
Ethernet II
Destination: 00:00:b4:bb:5d:ee (00:00:b4:bb:5d:ee)
Source: 00:20:18:b9:49:37 (00:20:18:b9:49:37)
Type: IP (0x0800)
Internet Protocol, Src Addr: 192.168.0.10, Dst Addr: 192.168.0.253
Version: 4
Header length: 20 bytes
Differentiated Services Field: 0x00 (DSCP 0x00: Default; ECN: 0x00)
0000 00.. = Differentiated Services Codepoint: Default (0x00)
.... ..0. = ECN-Capable Transport (ECT): 0
.... ...0 = ECN-CE: 0
Total Length: 366
Identification: 0xc99c
Flags: 0x04
.1.. = Don't fragment: Set
..0. = More fragments: Not set
Fragment offset: 0
Time to live: 128
Protocol: TCP (0x06)
Header checksum: 0xad95 (correct)
Source: 192.168.0.10 (192.168.0.10)
Destination: 192.168.0.253 (192.168.0.253)
Transmission Control Protocol, Src Port: 2752, Dst Port: 80
Source port: 2752 (2752)
Destination port: 80 (80)
Sequence number: 1135843004
Next sequence number: 1135843330
Acknowledgement number: 2485285689
Header length: 20 bytes
Flags: 0x0018 (PSH, ACK)
0... .... = Congestion Window Reduced (CWR): Not set
.0.. .... = ECN-Echo: Not set
..0. .... = Urgent: Not set
...1 .... = Acknowledgment: Set
.... 1... = Push: Set
.... .0.. = Reset: Not set
.... ..0. = Syn: Not set
.... ...0 = Fin: Not set
Window size: 17520
Checksum: 0x6ec7 (correct)
Hypertext Transfer Protocol
GET / HTTP/1.1\r\n La version du protocole HTTP utilisûˋ.
Suivent les informations supplûˋmentaires qu'envoie le client au serveur...
Accept: image/gif, Les images gif...
image/x-xbitmap, Les images bitmap (bmp par exemple)
image/jpeg, Les images jpeg...
image/pjpeg,
application/vnd.ms-powerpoint, Les trois lignes qui suivent
application/vnd.ms-excel, Reprûˋsentent des informations dont l'intûˋrûˆt
application/msword, peut paraitre contestable...
*/*\r\n
Accept-Language: fr\r\n Nous parlons franûÏais...
Accept-Encoding: gzip, deflate\r\n
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)\r\n
Host: linux.maison.mrs\r\n Celle-ci est indispensable au protocole v1.1
Connection: Keep-Alive\r\n Notez qu'IE demande û garder la connexion
\r\nSi IE se permet d'annoncer au monde entier que les composants principaux de MS Office sont prûˋsents sur ma machine, ce n'est pas dans le but de ô¨ô moucharderô ô£. Si vous dûˋsirez tûˋlûˋcharger des documents .doc, .xls ou .ppt, ces documents devront ûˆtre transfûˋrûˋs par le serveur au format MIME, comme une image gif ou jpg. Internet Explorer informe qu'il accepte ce type de documents. Dans la pratique, tous les navigateurs les acceptent, mais vous proposeront seulement de les enregistrer en tant que fichiers.ô Ici, IE indique qu'il est capable de les afficher lui-mûˆme.
3-2-3-4. La page d'accueil arrive▲
Frame 6 (710 on wire, 710 captured)
...
Hypertext Transfer Protocol
HTTP/1.1 200 OK\r\n
Date: Sun, 14 Apr 2002 09:30:12 GMT\r\n
Server: Apache-AdvancedExtranetServer/1.3.23 (Mandrake Linux/4mdk)
auth_ldap/1.6.0
mod_ssl/2.8.7
OpenSSL/0.9.6c
PHP/4.1.2\r\n
Last-Modified: Sun, 14 Apr 2002 09:29:32 GMT\r\n
ETag: ô¨ 57d44-116-3cb94bfc ô£\r\n
Accept-Ranges: bytes\r\n
Content-Length: 278\r\n
Keep-Alive: timeout=15, max=100\r\n
Connection: Keep-Alive\r\n
** Content-Type: text/html\r\n
** \r\n
Data (278 bytes)
0000 3c 68 74 6d 6c 3e 0d 0a 3c 68 65 61 64 3e 0d 0a <html>..<head>..
0010 3c 74 69 74 6c 65 3e 55 6e 74 69 74 6c 65 64 20 <title>Untitled
0020 44 6f 63 75 6d 65 6e 74 3c 2f 74 69 74 6c 65 3e Document</title>
0030 0d 0a 3c 6d 65 74 61 20 68 74 74 70 2d 65 71 75 ..<meta http-equ
0040 69 76 3d 22 43 6f 6e 74 65 6e 74 2d 54 79 70 65 iv="Content-Type
0050 22 20 63 6f 6e 74 65 6e 74 3d 22 74 65 78 74 2f "content="text/
0060 68 74 6d 6c 3b 20 63 68 61 72 73 65 74 3d 69 73 html; charset=is
0070 6f 2d 38 38 35 39 2d 31 22 3e 0d 0a 3c 2f 68 65 o-8859-1">..</he
0080 61 64 3e 0d 0a 0d 0a 3c 62 6f 64 79 20 62 67 63 ad>....<body bgc
0090 6f 6c 6f 72 3d 22 23 46 46 46 46 46 46 22 20 74 olor="#FFFFFF" t
00a0 65 78 74 3d 22 23 30 30 30 30 30 30 22 3e 0d 0a ext="#000000">..
00b0 3c 70 3e 48 65 6c 6c 6f 20 77 6f 72 6c 64 2e 0d <p>Hello world..
00c0 0a 3c 2f 70 3e 0d 0a 3c 70 3e 3c 69 6d 67 20 73 .</p>..<p><img s
00d0 72 63 3d 22 69 6d 61 67 65 73 2f 74 75 78 2e 67 rc="images/tux.g
00e0 69 66 22 20 77 69 64 74 68 3d 22 39 37 22 20 68 if" width="97" h
00f0 65 69 67 68 74 3d 22 31 31 35 22 3e 0d 0a 3c 2f eight="115">..</
0100 70 3e 0d 0a 3c 2f 62 6f 64 79 3e 0d 0a 3c 2f 68 p>..</body>..</h
0110 74 6d 6c 3e 0d 0a tml>..C'est au navigateur de se dûˋbrouiller pour aller chercher les donnûˋes de cette image, û partir des rûˋfûˋrences fournies. Tous ceux qui pratiquent le HTML le savent bienãÎ
Ceci justifie la prûˋsence de la requûˆte de la trame 7ô :
Frame 7 (298 on wire, 298 captured)
...
Hypertext Transfer Protocol
GET /images/tux.gif HTTP/1.1\r\n Appel d'une rûˋfûˋrence relative
Accept: */*\r\n
Referer: http://linux.maison.mrs\r\n Depuis la page indiquûˋe, ce qui aboutit
û la rûˋfûˋrence absolue:
http://linux.maison.mrs/images/tux.gif
Accept-Language: fr\r\n
Accept-Encoding: gzip, deflate\r\n
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)\r\n
Host: linux.maison.mrs\r\n
Connection: Keep-Alive\r\n
\r\nLe serveur envoie les donnûˋes û partir de la trame 9ô :
Frame 9 (1514 on wire, 1514 captured)
....
Hypertext Transfer Protocol
HTTP/1.1 200 OK\r\n
Date: Sun, 14 Apr 2002 09:30:12 GMT\r\n
Server: Apache-AdvancedExtranetServer/1.3.23 (Mandrake Linux/4mdk)
auth_ldap/1.6.0
mod_ssl/2.8.7
OpenSSL/0.9.6c
PHP/4.1.2\r\n
Last-Modified: Sun, 14 Apr 2002 09:29:32 GMT\r\n
ETag: ô¨ cf98a-a20-3cb94bfc ô£\r\n
Accept-Ranges: bytes\r\n
Content-Length: 2592\r\n
Keep-Alive: timeout=15, max=99\r\n
Connection: Keep-Alive\r\n
Content-Type: image/gif\r\n
\r\n
Data (1082 bytes)
0000 47 49 46 38 39 61 61 00 73 00 e6 00 00 04 04 05 GIF89aa.s.......
0010 a4 85 2f 49 48 47 a3 48 49 ed c8 10 c5 a4 32 9b ../IHG.HI.....2.
0020 69 07 ba 85 0e be 67 70 a9 3a 3c 85 66 1d d7 a5 i.....gp.:<.f...
0030 15 c4 48 4c a7 76 0c 8b 88 8d e8 e8 fc b8 88 94 ..HL.v..........
...3-2-3-5. Conclusions▲
Nous avons vu quelques choses intûˋressantesô :
- le navigateur, en gros, fait ce que nous avons fait avec Telnet, û quelques dûˋtails prû´sô :
- il envoie un certain nombre d'informations que nous n'avons pas envoyûˋes avec notre Telnet. Parmi celles-ci, Host: linux.maison.mrs, c'est-û -dire le nom du serveur, qui est le seul paramû´tre obligatoire pour HTTP 1.1, facultatif en HTTP 1.0,
- il se dûˋbrouille tout seul pour appeler tous les documents nûˋcessaires û l'affichage correct de cette page (ici l'image de Tux), et reconstitue correctement cette image pour l'afficher.
3-3. Le coup du cacheãÎ▲
Puisque nous y sommes, profitons-en pour observer un comportement intûˋressant du navigateurô : la mise en cache des pages consultûˋes.
L'internaute ferme son navigateur. Quelques instants plus tard, il l'ouvre û nouveau et rûˋclame la mûˆme page. Que va-t-il se passerô ?
No. Time Source Destination Proto Info
1 0.000000 192.168.0.10 192.168.0.253 TCP 2632 > 80 [SYN]
2 0.000144 192.168.0.253 192.168.0.10 TCP 80 > 2632 [SYN, ACK]
3 0.000540 192.168.0.10 192.168.0.253 TCP 2632 > 80 [ACK]
4 0.001342 192.168.0.10 192.168.0.253 HTTP GET / HTTP/1.1
5 0.001461 192.168.0.253 192.168.0.10 TCP 80 > 2632 [ACK]
6 0.004186 192.168.0.253 192.168.0.10 HTTP HTTP/1.1 304 Not Modified
7 0.200392 192.168.0.10 192.168.0.253 TCP 2632 > 80 [ACK]La rûˋponse n'est pas la mûˆme que dans le cas prûˋcûˋdent. Voyons ceci de plus prû´sãÎ
3-3-1. La requûˆte▲
Frame 4 (336 on wire, 336 captured)
...
Hypertext Transfer Protocol
GET / HTTP/1.1\r\n
Accept: */*\r\n
Accept-Language: fr\r\n
Accept-Encoding: gzip, deflate\r\n
If-Modified-Since: Sat, 13 Apr 2002 13:40:06 GMT\r\n Cette ligne n'apparaissait pas dans la requûˆte prûˋcûˋdente...
If-None-Match: "57d44-d2-3cb83536"\r\n
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)\r\n
Host: linux.maison.mrs\r\n
Connection: Keep-Alive\r\n
\r\nInternet Exlorer demande au serveur la page, si elle a ûˋtûˋ modifiûˋe depuis la date de son prûˋcûˋdent chargement, tout simplement parce qu'il a conservûˋ en cache cette page que nous avons dûˋjû demandûˋe il n'y a pas si longtemps.
3-3-2. La rûˋponse▲
Frame 6 (327 on wire, 327 captured)
...
Hypertext Transfer Protocol
HTTP/1.1 304 Not Modified\r\n
Date: Sat, 13 Apr 2002 13:53:52 GMT\r\n
Server: Apache-AdvancedExtranetServer/1.3.23 (Mandrake Linux/4mdk)
auth_ldap/1.6.0 mod_ssl/2.8.7 OpenSSL/0.9.6c PHP/4.1.2\r\n
Connection: Keep-Alive\r\n
Keep-Alive: timeout=15, max=100\r\n
ETag: "57d44-d2-3cb83536"\r\n
\r\nLe serveur s'est contentûˋ de rûˋpondre que la page n'a pas ûˋtûˋ modifiûˋeãÎ
Le navigateur va donc rûˋafficher la page qu'il a conservûˋe en cache. Cette mûˋthode de travail prûˋsente deux particularitûˋs :
- le temps d'affichage est considûˋrablement raccourci lorsque l'on navigue dans un site, puisque les pages dûˋjû chargûˋes ne le sont gûˋnûˋralement plus si l'on revient dessusô ;
- l'espace requis pour le cache gonfle considûˋrablement et peut occuper jusqu'û plusieurs dizaines de Mo sur votre disqueãÎ
Mûˋfiez-vous des effets de bord du cache localô ! Il existe de nombreux cas oû¿ le contrûÇle sur la modification n'est pas efficace. Votre navigateur affichera alors une version obsolû´te de la page. Ceci est surtout gûˆnant pour les dûˋveloppeurs de sites.
Un procûˋdûˋ analogue est ûˋgalement employûˋ par les serveurs proxy.
3-4. Toutes les commandes de HTTP 1.0▲
La comprûˋhension de la navigation ne nûˋcessite pas la connaissance de toutes les commandes, loin de lû . Aussi, nous ne les verrons pas en dûˋtail.
- La commande HEAD. Cette commande, qui existe ûˋgalement en v1.0, permet de ne demander au serveur que l'en-tûˆte, sans le document.
- La commande GET. Nous l'avons dûˋjû vue, ce n'est pas la peine d'y revenir, si ce n'est pour rappeler que l'option ô¨ô Host:ô ô£ doit impûˋrativement figurer dans la commande, pour ûˆtre acceptûˋe par le serveur en version 1.1, mais pas en version 1.0.
- La commande POST. C'est la commande qui permet d'envoyer des donnûˋes au serveur, gûˋnûˋralement par l'intermûˋdiaire d'un formulaire.
3-5. Et HTTP 1.1ô ?▲
Il propose quelques commandes supplûˋmentaires, commeô :
- OPTIONS qui permet d'interroger le serveur sur les options disponiblesô ;
- TRACE qui est en quelque sorte une commande de dûˋbogageô ;
- DELETE qui permet de dûˋtruire un fichier sur le serveur (gûˋnûˋralement dûˋsactivûˋe, vous vous en doutezãÎ)ô ;
- PUT qui permet d'ûˋcrire des fichiers sur le serveur, gûˋnûˋralement dûˋsactivûˋe ûˋgalement.
Ces deux derniû´res commandes sont introduites pour permettre une mise û jour des sites distants via HTTP.
4. Les pages ô¨ô activesô ô£▲
Nous allons maintenant jouer un peu avec quelques possibilitûˋs qui font parfois peurãÎ
4-1. Vous divulguez plus d'informations que vous ne croyezãÎ▲
Voici un exemple simple de ce qu'un serveur HTTP reûÏoit de votre part comme informations ô¨ô cachûˋesô ô£ et qu'il est donc capable d'exploiter, comme ici par exemple juste pour vous les afficherô :
| Votre Adresse IP (publique) | 216.73.217.128 |
|---|---|
| Le nom de votre machine telle qu'elle est connue sur le Net | 216.73.217.128 |
| La faûÏon dont vous vous prûˋsentez en tant que client HTTP | Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; ClaudeBot/1.0; +claudebot@anthropic.com) |
| La version de protocole HTTP utilisûˋe | HTTP/1.1 |
| Les types MIME | */* |
| Le document qui vous a conduit jusqu'ici | http://caleca.developpez.com/tutoriels/navigation-web-protocole-http/ |
4-1-1. Miracleô ?▲
Pas le moins du monde. Cette page est dynamique. Les informations qu'elle contient sont construites û la volûˋe par le serveur, avant de vous l'envoyer. La technologie utilisûˋe est ici PHP. Les informations affichûˋes ci-dessus sont obtenues û partir des variables d'environnement que votre navigateur envoie û chaque commande GET.
PHP n'est qu'un moyen de construire une page HTML dynamique qui vous renvoie ces informations, ûÏa aurait aussi pu ûˆtre fait avec un script CGI (dans les limites de ce que permet l'hûˋbergeur).
Si vous regardez le ô¨ô sourceô ô£ de cette page, vous n'y trouverez que du HTML.
4-2. Les formulairesãÎ▲
Les formulaires ont pour but de permettre au client d'envoyer des donnûˋes au serveur. û charge pour lui de les traiter correctement. Leur emploi va du simple ô¨ô log inô ô£ û la composition de documents trû´s sophistiquûˋs, et hûˋlas aussi parfois, û l'envoi d'informations qui ont ûˋtûˋ rûˋcupûˋrûˋes sur votre systû´me û votre insu.
Un formulaire peut envoyer ses donnûˋes de deux maniû´res.
4-2-1. Par la mûˋthode ô¨ô GETô ô£▲
Avec cette mûˋthode, les donnûˋes sont envoyûˋes dans l'URI de la page qui sera appelûˋe lorsque vous cliquerez sur ô¨ô envoyerô ô£.
Dans le formulaire ci-dessousô :
- le champ de saisie de texte s'appelle ô¨ô saisie1ô ô£ô ;
- Le bouton s'appelle ô¨ô B1ô ô£.
4-2-2. Par la mûˋthode ô¨ô POSTô ô£▲
û premiû´re vue, les donnûˋes sont envoyûˋes de faûÏon ô¨ô invisibleô ô£.
Dans le formulaire ci-dessusô :
- le champ de saisie de texte s'appelle ô¨ô saisie2ô ô£ô ;
- le bouton s'appelle ô¨ô B2ô ô£.
4-2-3. Le dûˋlicat cas des ô¨ô cookiesô ô£▲
Un cookie, c'est un petit fichier qu'un serveur HTTP peut ûˋcrire (et lire) sur votre machine par l'intermûˋdiaire de votre navigateur. L'objectif initial n'est en rien malicieux et peut mûˆme vous rendre service. Nous l'avons dûˋjû vu, HTTP ne gû´re pas le concept de session. Une session, c'est une pûˋriode pendant laquelle un certain contexte reste constant, mûˆme si vous y faites des choses diffûˋrentes. Par exemple, vous entrez dans un lieu protûˋgûˋ par une porte fermant û clûˋ. Vous ouvrez cette porte au moyen de la clûˋ. Une fois rentrûˋ dans ce lieu, vous pouvez y faire tout ce qui est autorisûˋ et vous n'aurez plus besoin de la clûˋ, jusqu'û ce que vous soyez sorti.
HTTP ne sait pas faire cela et ne conserve aucune mûˋmoire du passûˋ si ce n'est l'URI de la page d'oû¿ vous venez. C'est un peu faible, surtout si l'on doit gûˋrer des identifications de personnes, par exemple. Dans ces cas-lû , un cookie permettra de contourner le problû´me en permettant au serveur de retrouver û chaque page des informations ûˋcrites dans ce cookie.
4-2-3-1. Un exemple trivial▲
Le formulaire suivant vous permet de saisir une information dans un formulaire et de l'envoyer avec la mûˋthode POST (ûÏa aurait ûˋtûˋ pareil avec la mûˋthode GET, d'ailleurs).
La diffûˋrence par rapport aux exemples prûˋcûˋdents, c'est que la page qui va ûˆtre appelûˋe û l'envoi des donnûˋes de ce formulaire va ûˋcrire un cookie contenant cette donnûˋe sur votre machine (sauf si vous avez interdit û votre navigateur d'accepter les cookies).
4-2-3-2. Explications▲
Comme vous en avez l'habitude, cette trace correspond û un exemple exûˋcutûˋ sur mon installation et non û la manipulation que vous ûˆtes en train de faireãÎ
Ce n'est pas la mûˋthode POST employûˋe dans le formulaire qui va ûˋcrire le cookie dans la mûˋmoire de votre navigateur, mais bien la page que ce formulaire invoque, form_cookie1.php dans notre cas.
4-2-3-2-1. CommenûÏons par un aperûÏu sommaire▲
No. Time Source Destination Proto Info
La page des exemples est appelûˋe...
8 0.443083 192.168.0.10 192.168.0.251 HTTP GET /http/exemple1.php HTTP/1.1
9 0.443425 192.168.0.251 192.168.0.10 TCP 80 > 2349 [ACK]
Elle rentre...
10 0.470220 192.168.0.251 192.168.0.10 HTTP HTTP/1.1 200 OK
11 0.471471 192.168.0.251 192.168.0.10 HTTP Continuation
12 0.471874 192.168.0.10 192.168.0.251 TCP 2349 > 80 [ACK]
13 0.473661 192.168.0.251 192.168.0.10 HTTP Continuation
14 0.474914 192.168.0.251 192.168.0.10 HTTP Continuation
15 0.474943 192.168.0.10 192.168.0.251 TCP 2349 > 80 [ACK]
16 0.476205 192.168.0.251 192.168.0.10 HTTP Continuation
17 0.476246 192.168.0.251 192.168.0.10 HTTP Continuation
18 0.476730 192.168.0.10 192.168.0.251 TCP 2349 > 80 [ACK]
Le formulaire avec la valeur du cookie est envoyûˋ...
19 8.621094 192.168.0.10 192.168.0.251 HTTP POST /http/post_cookie1.php HTTP/1.1
La premiû´re page de rûˋponse est envoyûˋe par le serveur (c'est elle qui ûˋcrit le cookie).
20 8.642651 192.168.0.251 192.168.0.10 HTTP HTTP/1.1 200 OK
21 8.750822 192.168.0.10 192.168.0.251 TCP 2349 > 80 [ACK]
La page de vûˋrification du cookie est demandûˋe par un GET "normal"...
22 11.101585 192.168.0.10 192.168.0.251 HTTP GET /http/post_cookie2.php HTTP/1.1
Elle est envoyûˋe par le serveur.
23 11.122099 192.168.0.251 192.168.0.10 HTTP HTTP/1.1 200 OK
24 11.258788 192.168.0.10 192.168.0.251 TCP 2349 > 80 [ACK]4-2-3-2-2. Plus en dûˋtailãÎ▲
- La trame 8 ne prûˋsente pas d'intûˋrûˆt particulier, elle reprûˋsente l'appel de la page d'exemples ô¨ô exemple1.phpô ô£.
- Les trames 10 û 17 reprûˋsentent quant û elles l'arrivûˋe de cette page. Elle est longue et nûˋcessite plusieurs trames.
- La trame 19 commence û nous intûˋresser. Elle correspond û l'envoi du formulaire relatif aux cookies :
Frame 19 (439 on wire, 439 captured)
...
Hypertext Transfer Protocol
POST /http/post_cookie1.php HTTP/1.1\r\n
Accept: */*\r\n
Referer: http://gw2.maison.mrs/http/exemple1.php\r\n
Accept-Language: fr\r\n
Content-Type: application/x-www-form-urlencoded\r\n
Accept-Encoding: gzip, deflate\r\n
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)\r\n
Host: gw2.maison.mrs\r\n
Content-Length: 25\r\n
Connection: Keep-Alive\r\n
Cache-Control: no-cache\r\n
\r\n
Data (25 bytes)
0000 73 61 69 73 69 65 33 3d 63 6f 6f 6b 69 65 26 42 saisie3=cookie&B
0010 33 3d 45 6e 76 6f 79 65 72 3=Envoyer- La trame 20 est intûˋressante parce qu'elle met en ûˋvidence l'envoi du cookie du serveur au clientô :
Frame 20 (1473 on wire, 1473 captured)
...
Hypertext Transfer Protocol
HTTP/1.1 200 OK\r\n
Date: Sun, 21 Apr 2002 13:11:11 GMT\r\n
Server: Apache-AdvancedExtranetServer/1.3.22
(Mandrake Linux/1.1mdk) PHP/4.0.6 mod_ssl/2.8.5 OpenSSL/0.9.6b\r\n
X-Powered-By: PHP/4.0.6\r\n
Set-Cookie: VotreCookie=cookie; expires=Sun, 21-Apr-02 13:13:11 GMT\r\n
Le cookie a un identificateur : VotreCookie et une valeur : cookie
Keep-Alive: timeout=15, max=99\r\n
Connection: Keep-Alive\r\n
Transfer-Encoding: chunked\r\n
Content-Type: text/html\r\n
\r\n
Data (1051 bytes)
Vient ensuite le document lui-mûˆme...
0000 34 30 66 0d 0a 3c 68 74 6d 6c 3e 0d 0a 0d 0a 3c 40f..<html>....<
0010 68 65 61 64 3e 0d 0a 3c 6d 65 74 61 20 68 74 74 head>..<meta htt
...- La trame 22 montre comment votre navigateur renvoie docilement votre cookie au serveur û chaque requûˆte qu'il effectuera sur ce serveur.
Rappelons que la page ô¨ô post_cookie1.phpô ô£ ne prûˋsente aucun formulaire, aucun champ de saisie ni rien qui puisse vous laisser penser que la prochaine requûˆte va transmettre des informations au serveur.
Frame 22 (481 on wire, 481 captured)
...
Hypertext Transfer Protocol
GET /http/post_cookie2.php HTTP/1.1\r\n
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-powerpoint, application/vnd.ms-excel, application/msword, */*\r\n
Referer: http://gw2.maison.mrs/http/post_cookie1.php\r\n
Accept-Language: fr\r\n
Accept-Encoding: gzip, deflate\r\n
User-Agent: Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.0)\r\n
Host: gw2.maison.mrs\r\n
Connection: Keep-Alive\r\n
Cookie: VotreCookie=cookie\r\n
Voilû votre cookie qui est envoyûˋ û votre insu.
\r\n- La trame 23 prûˋsente un intûˋrûˆt tout de mûˆme, parce qu'elle montre que le cookie n'apparait pas directement.
Entendez par lû que le serveur ayant reûÏu ce cookie va en faire ce qu'il veut. Ici, il se contente d'en afficher le contenu dans la page. C'est une page active, construite par PHP. Rappelez-vous que votre navigateur, dans ce cas, reûÏoit du HTML tout ce qu'il y a de plus ô¨ô passifô ô£. Pas de script si l'auteur n'en a pas dûˋcidûˋ autrement.
Tout navigateur capable d'afficher du HTML affichera correctement cette page, mûˆme s'il ne sait absolument pas traiter les scripts.
Frame 23 (1127 on wire, 1127 captured)
...
Hypertext Transfer Protocol
HTTP/1.1 200 OK\r\n
Date: Sun, 21 Apr 2002 13:11:14 GMT\r\n
Server: Apache-AdvancedExtranetServer/1.3.22 (Mandrake Linux/1.1mdk) PHP/4.0.6 mod_ssl/2.8.5 OpenSSL/0.9.6b\r\n
X-Powered-By: PHP/4.0.6\r\n
Keep-Alive: timeout=15, max=98\r\n
Connection: Keep-Alive\r\n
Transfer-Encoding: chunked\r\n
Content-Type: text/html\r\n
\r\n
Data (774 bytes)
0000 32 66 61 0d 0a 3c 68 74 6d 6c 3e 0d 0a 0d 0a 3c 2fa..<html>....<
0010 68 65 61 64 3e 0d 0a 3c 6d 65 74 61 20 68 74 74 head>..<meta htt
0020 70 2d 65 71 75 69 76 3d 22 43 6f 6e 74 65 6e 74 p-equiv="Content
0030 2d 4c 61 6e 67 75 61 67 65 22 20 63 6f 6e 74 65 -Language" conte
0040 6e 74 3d 22 66 72 22 3e 0d 0a 3c 6d 65 74 61 20 nt="fr">..<meta
0050 68 74 74 70 2d 65 71 75 69 76 3d 22 43 6f 6e 74 http-equiv="Cont
0060 65 6e 74 2d 54 79 70 65 22 20 63 6f 6e 74 65 6e ent-Type" conten
0070 74 3d 22 74 65 78 74 2f 68 74 6d 6c 3b 20 63 68 t="text/html; ch
0080 61 72 73 65 74 3d 77 69 6e 64 6f 77 73 2d 31 32 arset=windows-12
0090 35 32 22 3e 0d 0a 3c 6d 65 74 61 20 6e 61 6d 65 52">..<meta name
00a0 3d 22 47 45 4e 45 52 41 54 4f 52 22 20 63 6f 6e ="GENERATOR" con
00b0 74 65 6e 74 3d 22 4d 69 63 72 6f 73 6f 66 74 20 tent="Microsoft
00c0 46 72 6f 6e 74 50 61 67 65 20 34 2e 30 22 3e 0d FrontPage 4.0">.
00d0 0a 3c 6d 65 74 61 20 6e 61 6d 65 3d 22 50 72 6f .<meta name="Pro
00e0 67 49 64 22 20 63 6f 6e 74 65 6e 74 3d 22 46 72 gId" content="Fr
00f0 6f 6e 74 50 61 67 65 2e 45 64 69 74 6f 72 2e 44 ontPage.Editor.D
0100 6f 63 75 6d 65 6e 74 22 3e 0d 0a 3c 74 69 74 6c ocument">..<titl
0110 65 3e 52 e9 73 75 6c 74 61 74 20 64 65 20 6c 61 e>R.sultat de la
0120 20 6d 61 6e 69 70 3c 2f 74 69 74 6c 65 3e 0d 0a manip</title>..
0130 3c 21 2d 2d 6d 73 74 68 65 6d 65 2d 2d 3e 3c 6c <!--mstheme--><l
0140 69 6e 6b 20 72 65 6c 3d 22 73 74 79 6c 65 73 68 ink rel="stylesh
0150 65 65 74 22 20 68 72 65 66 3d 22 66 69 6c 65 3a eet" href="file:
0160 2f 2f 2f 47 3a 2f 44 4f 43 55 4d 45 7e 31 2f 63 ///G:/DOCUME~1/c
0170 68 72 69 73 2f 4c 4f 43 41 4c 53 7e 31 2f 54 65 hris/LOCALS~1/Te
0180 6d 70 2f 46 72 6f 6e 74 50 61 67 65 54 65 6d 70 mp/FrontPageTemp
0190 44 69 72 2f 6d 73 74 68 65 6d 65 2f 74 61 62 73 Dir/mstheme/tabs
01a0 2f 74 61 62 73 31 31 31 31 2e 63 73 73 22 3e 0d /tabs1111.css">.
01b0 0a 3c 6d 65 74 61 20 6e 61 6d 65 3d 22 4d 69 63 .<meta name="Mic
01c0 72 6f 73 6f 66 74 20 54 68 65 6d 65 22 20 63 6f rosoft Theme" co
01d0 6e 74 65 6e 74 3d 22 74 61 62 73 20 31 31 31 31 ntent="tabs 1111
01e0 2c 20 64 65 66 61 75 6c 74 22 3e 0d 0a 3c 6d 65 , default">..<me
01f0 74 61 20 6e 61 6d 65 3d 22 4d 69 63 72 6f 73 6f ta name="Microso
0200 66 74 20 42 6f 72 64 65 72 22 20 63 6f 6e 74 65 ft Border" conte
0210 6e 74 3d 22 6e 6f 6e 65 22 3e 0d 0a 3c 2f 68 65 nt="none">..</he
0220 61 64 3e 0d 0a 0d 0a 3c 62 6f 64 79 3e 0d 0a 0d ad>....<body>...
0230 0a 3c 68 31 3e 52 e9 73 75 6c 74 61 74 20 64 65 .<h1>R.sultat de
0240 20 6c 61 20 6d 61 6e 69 70 3a 3c 2f 68 31 3e 0d la manip:</h1>.
0250 0a 3c 70 3e 0d 0a 56 6f 74 72 65 20 63 6f 6f 6b .<p>..Votre cook
0260 69 65 20 65 78 69 73 74 65 20 74 6f 75 6a 6f 75 ie existe toujou
0270 72 73 20 65 74 20 63 6f 6e 74 69 65 6e 74 20 6c rs et contient l
0280 61 20 76 61 6c 65 75 72 20 3a 20 3c 62 3e 3c 75 a valeur : <b><u
0290 3e 63 6f 6f 6b 69 65 3c 2f 75 3e 3c 2f 62 3e 0d >cookie</u></b>.
02a0 0a 3c 2f 70 3e 0d 0a 0d 0a 3c 68 32 3e 4d 61 69 .</p>....<h2>Mai
02b0 73 20 71 75 65 20 73 27 65 73 74 2d 69 6c 20 70 s que s'est-il p
02c0 61 73 73 e9 20 64 61 6e 73 20 74 6f 75 74 20 e7 ass. dans tout .
02d0 61 20 3f 3c 2f 68 32 3e 0d 0a 3c 70 3e 26 6e 62 a ?</h2>..<p>&nb
02e0 73 70 3b 3c 2f 70 3e 0d 0a 0d 0a 3c 2f 62 6f 64 sp;</p>....</bod
02f0 79 3e 0d 0a 0d 0a 3c 2f 68 74 6d 6c 3e 0d 0a 0d y>....</html>...
0300 0a 30 0d 0a 0d 0a .0....4-3. Conclusions▲
Nous avons vu quelques exemples de ce que l'on peut faire avecô :
- un client qui envoie des donnûˋes volontairement ou non, û un serveurô ;
- un serveur qui exploite ces donnûˋes au moyen de scripts, ici en PHP.
Nous n'avons pas vu ce que pourrait faire un script CGI, mais ce serait du mûˆme ordre. Toutes ces dûˋmonstrations sont donc axûˋes sur du ô¨ô server sideô ô£. Le client envoie les donnûˋes et reûÏoit du HTML statique. C'est le serveur qui traite les donnûˋes reûÏues et agit en fonction.
Dans tout ce que nous avons vu ici, le ô¨ô dynamismeô ô£ des pages venait exclusivement du serveur, et le client se contente d'envoyer des requûˆtes et des donnûˋes pour voir le contenu des pages se modifier. La page suivante va vous donner quelques exemples simples de JavaScript qui s'exûˋcutent cûÇtûˋ client, donc sur votre machine.
5. Scripts clients▲
Dans cette page, tout ce qu'il va se passer va se passer sur votre machine, il n'y aura aucun ûˋchange avec le serveurãÎ
Comme c'est du JavaScript, malgrûˋ mes efforts pour tester sur divers navigateurs, il se peut que sur le vûÇtre, ces dûˋmonstrations soient un ô¨ô flopô ô£ãÎ
5-1. Les alertes▲
Il est possible de dûˋclencher un ô¨ô pop-upô ô£ d'alerte, ou de demande de confirmation, ou mûˆme encore de saisie d'un paramû´tre, par simple action sur une page. Voici un exemple d'alerte dûˋclenchûˋe par un boutonô :
5-2. Ouvrir une fenûˆtre▲
Cet exemple ouvre une simple fenûˆtre au contenu statique. Il est possible d'ouvrir une fenûˆtre quelconque, bien sû£r.
Voici l'exempleô :
5-3. Faire des calculs▲
Ce dernier exemple ouvre une fenûˆtre contenant elle-mûˆme un script assez complet, qui permet de faire des calculs et d'en afficher le rûˋsultat de faûÏon complû´tement locale, dans votre navigateurô :
5-4. Conclusions▲
Bien entendu, il est possible de rûˋaliser beaucoup de choses avec des scripts et cette page pourrait ûˆtre bien plus longue.
J'espû´re que tout ceci vous aura permis de voir plus clairementô :
- comment une page HTML est envoyûˋe d'un serveur vers un clientô ;
- comment le contenu de cette page peut ûˆtre construitô :
- avec un contenu figûˋ (HTML ûˋcrit une fois pour toutes, û la maniû´re d'un livre),
- avec un contenu construit û la volûˋe par le serveur (nous avons vu quelques exemples avec PHP),
- avec un contenu calculûˋ localement par votre navigateur (quelques exemples de JavaScript).
Encore une fois, rien n'interdit de mûˋlanger les deux mûˋthodes et de construire sur le serveur des pages dynamiques en PHP, par exemple, qui contiennent du JavaScript. Cette mûˋthode permet d'ailleurs, puisque le navigateur peut ûˆtre identifiûˋ cûÇtûˋ serveur, d'envoyer un script qui soit compatible avec le navigateur du client. La mûˋthode est assez lourde, mais efficace.
6. Le proxy HTTP▲
6-1. Principe de base▲
Le principe de base consiste û direô :
lorsque je dûˋsire obtenir un document, je ne vais pas le demander û la source. Je vais le demander û mon serveur proxy. Celui-ci ira chercher le document û ma place et me le transmettra û sa rûˋception. Au passage, il le gardera en mûˋmoire ô¨ô un certain tempsô ô£, si bien que si un autre client redemande dans cette pûˋriode le mûˆme document, le proxy n'aura pas besoin de retourner le chercher û la source. Ceci ne fonctionne correctement que pour les documents statiques, bien entendu. Pour les documents de type ASP, JSP ou PHP, la mise en tampon est beaucoup plus problûˋmatique.
Ce type de fonctionnement, oû¿ le client s'adresse systûˋmatiquement au proxy pour obtenir une page quelconque sur le web a fait traduire ô¨ô proxy serverô ô£ par ô¨ô serveur mandataireô ô£.
Notez que dans cette dûˋmarche, le client est au courant de l'existence du proxy, il va donc envoyer une requûˆte adaptûˋe û la situation, qui n'est pas tout û fait la mûˆme que dans le cas oû¿ il s'adresserait directement û la cible. Nous le verrons en dûˋtail un peu plus loin.
6-2. Les avantages▲
6-2-1. Optimisation de la bande passante▲
Imaginons un cas simpleô :
- nous sommes dans un lycûˋe technique, les ûˋtudiants qui sont dans un laboratoire, disposent chacun d'un poste informatique. Tous ces postes sont en rûˋseau local, avec un accû´s û l'Internet partagûˋ par un routeur NATô ;
- tous les ûˋtudiants doivent consulter un document, disons, chez Texas Instrumentô ;
- il y a 14 postes, il y aura 14 requûˆtes identiques vers le serveur de TI et 14 envois de documents identiques vers les clients.
Nous remplaûÏons le routeur NAT par un serveur Proxy. Dans ce casô :
- la premiû´re requûˆte sera transmise par le proxy vers le serveur de TIô ;
- les 13 autres seront servies directement par le cache du proxy.
Un seul transfert de page depuis le serveur Texas Instruments vers le rûˋseau local en remplace 14.
6-2-2. Surveillance et filtrage de l'accû´s au Net▲
Parmi nos 14 ûˋlû´ves, il y en aura bien un qui aura l'idûˋe, en passant, d'aller faire un petit tour sur par exemple http://www.canalcharme.com ou pire. N'y voyez pas de puritanisme de ma part, juste un souci d'efficacitûˋ dans le travail et une obligation lûˋgale de protection des mineursãÎ
- Avec un routeur NAT, le filtrage va ûˆtre difficile, parce que le seul moyen ô¨ô simpleô ô£ serait de filtrer au niveau de l'IP du serveur.
- Avec un proxy comme SQUID, qui travaille au niveau HTTP et qui voit donc passer les URI, il existera une foule de solutions qui permettront un filtrageô :
- par mot-clûˋ sur les URLô ;
- par bannissement de domaines ou d'URI rûˋfûˋrencûˋs dans une base de donnûˋes.
6-2-3. Les inconvûˋnients▲
Parce qu'il y en a tout de mûˆmeãÎ
- La durûˋe de vie du cache et les mauvais paramûˋtrages entraûÛnent que les documents reûÏus peuvent ne plus ûˆtre û jour.
- û multiplier les proxy en chaûÛne, on amplifie ce problû´me et on court aussi le risque de recevoir des documents falsifiûˋs. En effet, s'il est intûˋressant de monter un proxy en tûˆte d'un rûˋseau local, il faut savoir que les FAI peuvent en utiliser aussi, de faûÏon plus ou moins transparente (nous verrons ûÏa plus loin). Un serveur proxy, ûÏa peut ûˆtre piratûˋ et ô¨ô bricolûˋô ô£ãÎ
6-3. Le client doit ûˆtre au courantãÎ▲
Il faut commencer par paramûˋtrer son navigateur Internet pour qu'il fasse appel û un proxy. Nous comprendrons mieux pourquoi en analysant le rûˋseau.
Pour Firefox, c'est assez simpleô :
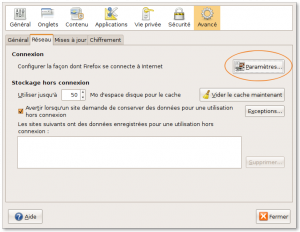
Menu ô¨ô ûditionô ô£ sous GNU/Linux ou ô¨ô Outilsô ô£ sous Windows, commande ô¨ô PrûˋfûˋrencesãÎô ô£, Option ô¨ô Avancûˋô ô£, onglet ô¨ô Rûˋseauô ô£ô : Utilisez le bouton ô¨ô Paramû´tresô ô£ de la connexion.
Ne faites pas confiance aux systû´mes automatisûˋs dans la mesure du possible et indiquez plutûÇt explicitement les paramû´tres du proxyô :
- Son adresse IP (ou son URL)ô ;
- Le port sur lequel il travaille (3128 est le port par dûˋfaut pour SQUID).
Vous pouvez ûˋventuellement spûˋcifier des proxy diffûˋrents suivant les protocoles et dans quelles conditions vous voulez ûˋviter le proxy.
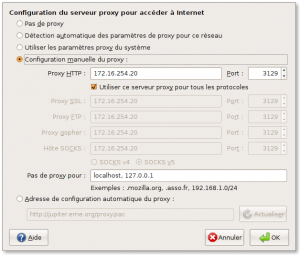
Voilû . Si le proxy est bien configurûˋ, ûÏa devrait fonctionnerãÎ
6-4. Que se passe-t-il, en faitô ?▲
6-4-1. Le plus souventãÎ▲
Un proxy est placûˋ entre un rûˋseau local privûˋ et un accû´s Internet. La configuration est alors la suivanteô :

Le proxy dispose de deux adressesô :
- l'une dans le rûˋseau privûˋ (192.168.0.253 dans l'exemple)ô ;
- l'autre sur le rûˋseau du FAI (80.8.128.5 dans l'exemple).
Le proxy isole complû´tement le rûˋseau privûˋ de l'Internet. Il ne servira que de serveur mandataire pour les requûˆtes HTTP (ûˋventuellement aussi FTP). Avec la floraison de services webmail proposûˋe par les fournisseurs de services, cette configuration peut permettre l'accû´s aux trois services les plus utilisûˋs sur le Netô :
- le surf (HTTP)ô ;
- le tûˋlûˋchargement de fichiers (FTP)ô ;
- le courrier, pris en charge par l'interface webmail du FAI.
Si l'on se contente de ces trois services, il n'est alors pas nûˋcessaire d'installer de routeur NAT, le proxy suffit. Mais comprenons-nous bienô : seuls les protocoles HTTP et FTP passeront, sauf cas de proxy plus particuliers, ce qui n'est pas l'objet de cette prûˋsentation.
6-4-2. Dans la dûˋmonstration qui suitô ▲
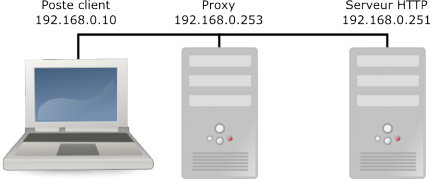
Le montage adoptûˋ n'est pas obligatoirement le plus utile. Il n'y a d'ailleurs pas de connexion Internet mise en éuvre ici. Ce montage est juste fait pour illustrer le travail du proxy, lorsqu'il est utilisûˋ.
Notez bien que 192.168.0.251 (qui est en fait ma passerelle NAT vers le Net, bien que cette fonction ne serve pas ici), est ûˋgalement mon DNS, ûÏa va se voir dans l'exemple.
6-4-2-1. Premier casô : sans le proxy▲
Le client va demander la page d'accueil du site hûˋbergûˋ sur le serveur HTTP. Il va le faire directementô :
No. Source Destination Protocol Info
4 192.168.0.10 192.168.0.251 HTTP GET / HTTP/1.1
6 192.168.0.251 192.168.0.10 HTTP HTTP/1.1 200 OK
7 192.168.0.10 192.168.0.251 HTTP GET /tbm.htm HTTP/1.1
8 192.168.0.251 192.168.0.10 HTTP HTTP/1.1 200 OK
9 192.168.0.251 192.168.0.10 HTTP Continuation
11 192.168.0.251 192.168.0.10 HTTP Continuation
16 192.168.0.10 192.168.0.251 HTTP GET /home.htm HTTP/1.1
18 192.168.0.251 192.168.0.10 HTTP HTTP/1.1 200 OK
19 192.168.0.251 192.168.0.10 HTTP Continuation
23 192.168.0.10 192.168.0.251 HTTP GET /banniere.htm TTP/1.1
24 192.168.0.251 192.168.0.10 HTTP HTTP/1.1 200 OK
25 192.168.0.251 192.168.0.10 HTTP Continuation
etc...J'ai volontairement fait disparaûÛtre les trames SYN, ACK de TCP, qui ne nous apportent rien dans la comprûˋhension de l'ûˋchange. Nous voyons clairement que l'ûˋchange se fait entre le client et le serveur HTTP.
6-4-2-2. Second casô : avec le proxy▲
Nous paramûˋtrons maintenant notre client pour qu'il utilise le proxy 192.168.0.253. Nous vidons le cache du navigateur et refaisons notre requûˆte. Le proxy est ûˋgalement ô¨ô tout neufô ô£ son cache est parfaitement vide.
No. Source Destination Protocol Info
4 192.168.0.10 192.168.0.253 HTTP GET http://gw2.maison.mrs/ HTTP/1.0
La requûˆte a ûˋtûˋ faite au proxy et non pas û la cible qui est 192.168.0.251...
Le proxy, cherche alors l'IP de la cible : (192.168.0.251 est aussi DNS dans l'exemple).
Notez que le client envoie ici dans sa requûˆte l'URI complet de la cible convoitûˋe
6 192.168.0.253 192.168.0.251 DNS Standard query A gw2.maison.mrs
7 192.168.0.251 192.168.0.253 DNS Standard query response A 192.168.0.251
Puis transmet la requûˆte û la cible...
11 192.168.0.253 192.168.0.251 HTTP GET / HTTP/1.0
La cible rûˋpond au proxy :
13 192.168.0.251 192.168.0.253 HTTP HTTP/1.1 200 OK
qui retransmet au client:
15 192.168.0.253 192.168.0.10 HTTP HTTP/1.0 200 OK
et ainsi de suite...
16 192.168.0.10 192.168.0.253 HTTP GET http://gw2.maison.mrs/tbm.htm HTTP/1.0
18 192.168.0.253 192.168.0.251 HTTP GET /tbm.htm HTTP/1.0
20 192.168.0.251 192.168.0.253 HTTP HTTP/1.1 200 OK
22 192.168.0.253 192.168.0.10 HTTP HTTP/1.0 200 OK
23 192.168.0.251 192.168.0.253 HTTP Continuation
25 192.168.0.253 192.168.0.10 HTTP Continuation
26 192.168.0.251 192.168.0.253 HTTP Continuation
28 192.168.0.251 192.168.0.253 HTTP Continuation
31 192.168.0.253 192.168.0.10 HTTP Continuation
35 192.168.0.10 192.168.0.253 HTTP GET http://gw2.maison.mrs/banniere.htm HTTP/1.0
37 192.168.0.253 192.168.0.251 HTTP GET /banniere.htm HTTP/1.0
41 192.168.0.10 192.168.0.253 HTTP GET http://gw2.maison.mrs/home.htm HTTP/1.0
46 192.168.0.253 192.168.0.251 HTTP GET /home.htm HTTP/1.0
48 192.168.0.251 192.168.0.253 HTTP HTTP/1.1 200 OK
49 192.168.0.251 192.168.0.253 HTTP Continuation
51 192.168.0.253 192.168.0.10 HTTP HTTP/1.0 200 OK
52 192.168.0.253 192.168.0.10 HTTP Continuation
54 192.168.0.251 192.168.0.253 HTTP HTTP/1.1 200 OK
56 192.168.0.253 192.168.0.10 HTTP HTTP/1.0 200 OK
57 192.168.0.251 192.168.0.253 HTTP Continuation
etc...Bien. Pour l'instant, c'est plutûÇt nettement plus compliquûˋ et plus lourd qu'une requûˆte directe. Notez au passage que le proxy (Squid dans ce cas), cause HTTP 1.0 et non HTTP 1.1.
Nous pouvons suivre les ûˋvû´nements û travers les logs du serveur SQUIDô :
192.168.0.10 TCP_MISS/200 1421 GET http://gw2.maison.mrs/ - DIRECT/192.168.0.251 text/html
192.168.0.10 TCP_MISS/200 4365 GET http://gw2.maison.mrs/tbm.htm - DIRECT/192.168.0.251 text/html
192.168.0.10 TCP_MISS/200 1513 GET http://gw2.maison.mrs/banniere.htm - DIRECT/192.168.0.251 text/html
192.168.0.10 TCP_MISS/200 4228 GET http://gw2.maison.mrs/home.htm - DIRECT/192.168.0.251 text/html
etc...Le TCP_MISS indique que le proxy n'a pas la rûˋponse en cache et qu'il va donc la chercher û la source (DIRECT).
Mais maintenant, le cache du proxy n'est pas vide, il contient dûˋsormais ces documents. Nous allons le vûˋrifier immûˋdiatement enô :
- vidant le cache local du navigateurô ;
- effectuant û nouveau la mûˆme requûˆte.
No. Source Destination Protocol Info
4 192.168.0.10 192.168.0.253 HTTP GET http://gw2.maison.mrs/ HTTP/1.0
6 192.168.0.253 192.168.0.10 HTTP HTTP/1.0 200 OK
7 192.168.0.10 192.168.0.253 HTTP GET http://gw2.maison.mrs/tbm.htm HTTP/1.0
8 192.168.0.253 192.168.0.10 HTTP HTTP/1.0 200 OK
9 192.168.0.253 192.168.0.10 HTTP Continuation
11 192.168.0.253 192.168.0.10 HTTP Continuation
16 192.168.0.10 192.168.0.253 HTTP GET http://gw2.maison.mrs/banniere.htm HTTP/1.0
18 192.168.0.253 192.168.0.10 HTTP HTTP/1.0 200 OK
19 192.168.0.253 192.168.0.10 HTTP Continuation
24 192.168.0.10 192.168.0.253 HTTP GET http://gw2.maison.mrs/home.htm HTTP/1.0
26 192.168.0.253 192.168.0.10 HTTP HTTP/1.0 200 OK
27 192.168.0.253 192.168.0.10 HTTP Continuation
etc...Et lû , nous constatons que le dialogue s'effectue uniquement entre le client et le proxy. Autrement dit, le proxy sert au client la totalitûˋ des requûˆtes, il n'y a plus aucun ûˋchange entre le proxy et le serveur HTTP.
Vûˋrifions les logsô :
192.168.0.10 TCP_MEM_HIT/200 1430 GET http://gw2.maison.mrs/ - NONE/- text/html
192.168.0.10 TCP_MEM_HIT/200 4374 GET http://gw2.maison.mrs/tbm.htm - NONE/- text/html
192.168.0.10 TCP_MEM_HIT/200 1522 GET http://gw2.maison.mrs/banniere.htm - **NONE/- text/html
192.168.0.10 TCP_MEM_HIT/200 4237 GET http://gw2.maison.mrs/home.htm - NONE/- text/html
etc...TCP_MEM_HIT veut dire que non seulement la rûˋponse est en cache (HIT) mais qu'elle est en mûˋmoire (MEM). Il n'y a donc pas d'interrogation en amont (NONE).
Notez qu'il aurait pu se passer autre chose. Ici, la requûˆte initiale et la seconde requûˆte du client ûˋtaient sûˋparûˋes par un intervalle de temps trû´s court. Si cet intervalle avait augmentûˋ, le document ne se serait peut-ûˆtre plus trouvûˋ dans le cache mûˋmoire, mais dans le cache disque, et il aurait pu se faire que le proxy aille s'assurer auprû´s du serveur source que son contenu local ûˋtait encore valide. La stratûˋgie est assez logiqueô :
- un document qui vient d'ûˆtre tûˋlûˋchargûˋ par le proxy a toutes les chances d'ûˆtre toujours valide. Il est donc possible de le resservir directement, sans prûˋcautions particuliû´resô ;
- un document qui a ûˋtûˋ tûˋlûˋchargûˋ il y a dûˋjû quelque temps, risque d'avoir ûˋtûˋ modifiûˋ. Il convient donc de s'assurer d'abord auprû´s du serveur source que le document n'a pas ûˋtûˋ modifiûˋ depuisô ;
- un document qui a ûˋtûˋ tûˋlûˋchargûˋ il y a trop longtemps est dûˋtruit du cache du proxy. au prochain appel, il faudra le tûˋlûˋcharger û nouveau.
Les notions de ô¨ô vient d'ûˆtreô ô£, ô¨ô il y a dûˋjû quelque tempsô ô£ et ô¨ô il y a trop longtempsô ô£ sont bien entendu subjectives et c'est û l'administrateur du proxy de les ûˋvaluer efficacement.
Il y a tout de mûˆme quelques exceptions û ces rû´glesô :
- les documents ô¨ô actifsô ô£, nous l'avons dûˋjû dit, tels que les pages PHP, ASP, JSPãÎ ou qui viennent de scripts CGIô ;
- les documents ô¨ô passifsô ô£, mais qui contiennent un champ ô¨ô expireô ô£ dans leur en-tûˆte. Ce champ, assez peu utilisûˋ, permet au concepteur d'une page de forcer l'attitude d'un proxy û son ûˋgard.
6-5. FinalementãÎ▲
Lorsque la connexion entre le rûˋseau local et le Net se fait par un lien facturûˋ û la durûˋe ou au volume transmis, le gain financier peut ûˆtre apprûˋciable.
Lorsque la connexion au Net se fait par un lien û faible dûˋbit, le gain en temps peut ûˋgalement ûˆtre trû´s apprûˋciable.
Nous ne le verrons pas ici dans le dûˋtail, mais les possibilitûˋs de contrûÇle d'accû´s au Net sont plus grandes et plus simples û mettre en éuvre avec un proxy qu'avec un routeur. De mûˆme, la sûˋcuritûˋ du rûˋseau local est plus facilement assurûˋe, si le serveur proxy n'est vraiment qu'un proxy. La solution du proxy n'est cependant pas la panacûˋe et il convient de bien analyser toutes les solutions possibles û un problû´me donnûˋ avant d'en choisir une.
6-6. Le proxy ô¨ô transparentô ô£▲
Dans ce que nous avons vu, la prûˋsence du proxy est connue des utilisateurs du rûˋseau, ils doivent configurer leur navigateur pour pouvoir l'utiliser.
Il est possible de forcer les utilisateurs û passer par le proxy en bloquant le port 80 sur la passerelle par dûˋfaut. L'expûˋrience montre qu'il n'est pas toujours simple de l'expliquer aux utilisateurs, surtout lorsqu'ils sont visiteurs occasionnels.
Techniquement, nous l'avons vu dans les analyses des trames, le client HTTP s'adresse explicitement au proxy et place dans sa requûˆte GET l'URI complet de la cible visûˋe. C'est pour forcer ce type de comportement qu'il faut paramûˋtrer correctement le client HTTP.
L'autre mûˋthode, c'est de laisser le client HTTP dans l'ignorance de l'existence du proxy. Il va alors exûˋcuter un GET ô¨ô normalô ô£ sur l'adresse IP de la cible visûˋe. Pour forcer le passage par le proxy, la passerelle devra alors rediriger cette requûˆte sur le serveur proxy et ce dernier devra savoir retrouver l'adresse de la cible, ailleurs que dans la commande GET, surtout si le client parle HTTP 1.0. La configuration du proxy doit donc tenir compte de ce mode de fonctionnement.
Squid sait fonctionner en mode ô¨ô transparentô ô£, il suffit de le lui demander poliment.
6-6-1. Avantages▲
Plus de configuration du client HTTP, donc plus rien de technique û expliquer aux utilisateurs.
L'utilisateur occasionnel (visiteur par exemple) n'aura pas û ô¨ô bricolerô ô£ son client HTTP en entrant et en sortant de votre rûˋseau. Mûˆme si pour lui, cette opûˋration est triviale, elle reste tout de mûˆme contraignante.
6-6-2. Inconvûˋnients▲
La tentation est grande alors d'oublier de prûˋvenir les utilisateurs qu'ils passent par un proxy et que donc, outre les ûˋventuels dûˋcalages entre les pages servies et les pages û jour, toute leur activitûˋ se trouve enregistrûˋe dans les logs.
Un proxy transparent ne peut fonctionner que sur un seul port et uniquement pour HTTPô :
- les clients qui visent des serveurs sur le port 81 par exemple, passeront directement (ou ne pourront pas passer du tout si votre firewall le leur interdit)ô ;
- pas de proxy transparent pour FTPô ;
- pas de proxy HTTPS (encore que l'on peut s'interroger sur son utilitûˋ dans ce cas).
6-7. Conclusion▲
Le serveur proxy peut ûˆtre une trû´s bonne solution pour partager un accû´s Internet au niveau application, ce qui permet d'effectuer un filtrage au niveau du protocole lui-mûˆme. Indispensable lorsque l'on doit donner l'accû´s û des mineurs, dans le cadre scolaire par exemple.
Une mise en pratique est analysûˋe dans le chapitre ô¨ô Squid et SquidGuardô ô£ dans ce but.
7. Remerciements Developpez▲
Vous pouvez retrouver l'article original iciô : L'Internet Rapide et Permanent. Christian Caleca a aimablement autorisûˋ l'ûˋquipe ô¨ô Rûˋseauxô ô£ de Developpez.com û reprendre son article. Retrouvez tous les articles de Christian Caleca sur cette page.
Nos remerciements û Torgar et sevyc64 pour leur participation technique ainsi qu'û ClaudeLeloup pour sa relecture orthographique.
N'hûˋsitez pas û commenter cet articleô ! 1 commentaire ![]()