


I. Introduction▲
La mise en place d'un serveur mandataire HTTP (proxy HTTP) présente de nombreux avantages, aussi bien en termes de sécurité que de « contrôle parental », surtout dans le cadre d'établissements qui offrent à des mineurs la possibilité d'accès à l'Internet (écoles, collèges, lycées, associations diverses…).
Nous utiliserons bien entendu des solutions libres, à savoir Squid pour le proxy HTTP et SquidGuard pour l'élément de filtrage.
Si une mise en place minimum de Squid ne présente guère de difficultés, l'insertion du « helper » SquidGuard reste tout de même plus délicate et mérite que l'on y passe un peu de temps.
Transparent ou pas ? Nous verrons les avantages et inconvénients de chacune des méthodes.
Identifier les utilisateurs ou se contenter de contrôler les accès de façon anonyme ? Nous envisagerons les deux possibilités.
Nous allons travailler avec une distribution Debian dite « testing » (la Lenny, à l'heure où je rédige ce chapitre).
Pourquoi Debian ?
- Elle est stable,
- elle s'installe assez simplement, si l'on a déjà une petite expérience de Linux ;
- elle est très simple à mettre à jour, même en cas de mise à jour de version ;
- il y a tout ce qu'il faut comme paquetages pour ce que l'on veut faire, et mĂŞme bien davantage encore.
Bien que la Debian soit utilisée ici, rien n'interdit de le transposer à une autre distribution, sous réserve d'utiliser des paquetages de bases de données Berkeley compatibles avec le fonctionnement de SquidGuard. Suivant la distribution, des problèmes peuvent apparaitre.
II. Fonctionnement▲
II-A. Des passerelles entre rĂ©seaux▲
Bien que ces sujets soient abordés plus en détail ailleurs sur ce site, un petit rappel ne fera sans doute pas de mal. La question de base est :
- comment permettre aux hôtes d'un réseau d'accéder aux hôtes d'un autre réseau ?
II-A-1. Le bout de fil▲
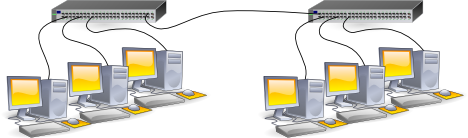
Au départ, nous disposons de deux réseaux physiques, construits avec des HUBS. Il suffit de placer un câble entre les deux HUBS. Cette solution simplissime interconnecte au niveau le plus bas (couche physique), avec quelques contraintes et inconvénients :
- les trames émises par les nœuds de chaque réseau initial sont propagées sur l'autre réseau (en fait, il n'y a plus qu'un seul réseau physique) et le risque est grand de voir s'écrouler rapidement les performances du réseau ;
- du fait que nous sommes sur le même réseau physique, le réseau IP doit être également le même (même plan d'adressage IP).
Cette solution revient en fait à ajouter de nouveaux hôtes sur un réseau déjà existant.
II-A-2. Le pont Ethernet▲
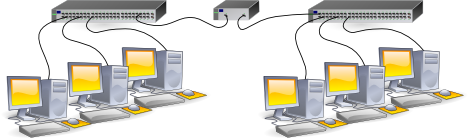
La même chose, mais avec un dispositif un peu plus intelligent qu'un simple bout de fil, puisque le pont évitera la propagation des trames qui ne concernent pas un hôte de l'autre réseau. L'interconnexion se fait ici au niveau 2. Au niveau IP, les contraintes restent les mêmes, nous sommes partout dans le même réseau IP.
Cette solution est aujourd'hui complètement généralisée, puisque les switches ne sont rien d'autre que des ponts multivoies et donc, tirer un bout de câble entre deux switches revient à la solution du pont.
II-A-3. Le routeur IP▲
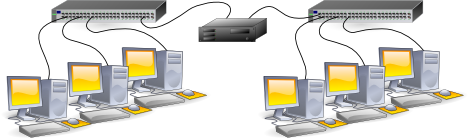
Ici, nous interconnections au niveau 3 (IP). Les deux réseaux disposent chacun de leur propre plan d'adressage IP. Les possibilités de contrôle d'accès d'un réseau à l'autre sont bien plus fines (filtrage de paquets genre Netfilter/IPtables).
II-A-4. Le serveur mandataire▲
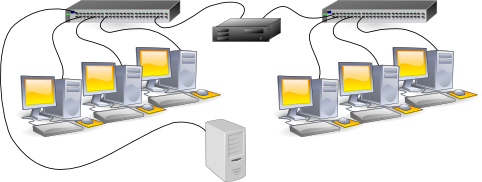
Nous travaillons ici au niveau 4 (du modèle DOD) c'est-à -dire au niveau du protocole d'application (HTTP pour ce qui nous concerne ici). Il existe deux types de serveurs mandataires :
- le proxy « normal », qui nécessite que l'application cliente sache que le proxy existe et sache aussi travailler avec. En effet, dans ce cas, le client envoie ses requêtes au serveur mandataire, à charge pour lui d'aller chercher plus loin l'information réclamée par le client et de la lui transmettre, une fois l'information obtenue. Les clients HTTP (navigateurs) modernes savent tous le faire. C'est en revanche très rarement le cas pour d'autres protocoles comme POP, FTP, etc. ;
- le proxy « transparent », qui agit dans la totale ignorance du client. Dans cette situation, le client croit s'adresser directement à la cible finale, mais la requête est interceptée et traitée par le mandataire. Cette solution, nécessaire le plus souvent pour des protocoles comme POP ou FTP où les clients ne savent pas utiliser de proxy, n'est pas obligatoire pour HTTP. Nous aurons l'occasion de rediscuter de ce choix.
Dans l'illustration, les hôtes du réseau de gauche accèderont aux informations fournies par les serveurs HTTP du réseau de droite via le serveur mandataire qui est dans leur réseau. Nous reviendrons plus loin sur cette architecture qui peut sembler peu évidente au premier regard.
II-B. Objectif▲
Installer un système de proxy cache pour HTTP. Ce proxy-cache propose deux fonctions principales :
- l'optimisation de la bande passante sur le lien Internet, lorsque de nombreux clients sont connectés et qu'ils visitent plus ou moins les mêmes sites, à la condition, bien sûr, que ces sites ne soient pas trop dynamiques, ASP, JSP, PHP… ni chiffrés (HTTPS). Comme vous le constatez, la fonction cache présente de moins en moins d'intérêt. Il en reste un cependant, surtout pour les illustrations qui ne sont pas encore toutes en flash ;
- le contrôle et le filtrage de l'accès à la toile, en se servant des URI et, éventuellement, des noms d'utilisateurs, si l'on fait de l'authentification de ces derniers, autant de choses qu'il est difficile, voire impossible de faire avec du filtrage de paquets. En effet, en travaillant au niveau du protocole HTTP, il devient possible de mettre en place des filtres d'URI, des analyses de contenu dans les documents, alors qu'au niveau IP, nous ne pourrions filtrer que sur des adresses et des ports.
Tout responsable d'un réseau local à l'usage de mineurs et connecté à l'Internet se doit de mettre en place un tel système de filtrage de manière à éviter, autant que possible, l'accès à des sites que la morale réprouve, d'autant qu'il s'agit d'une obligation légale.
II-C. PrĂ©sentation gĂ©nĂ©rale▲
II-C-1. Les modes de fonctionnement▲
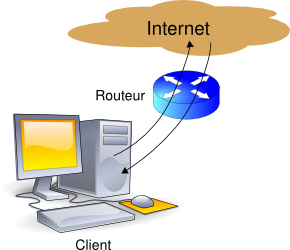 |
Dans un fonctionnement normal, un navigateur HTTP interroge directement le serveur cible et il reçoit directement les réponses de ce dernier. Il n'y a pas de filtrage possible, autrement que sur les adresses IP des serveurs cibles. |
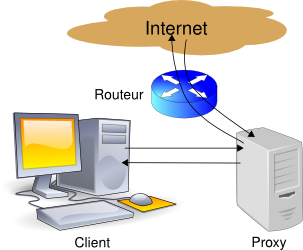 |
Dans le cas d'un proxy « normal », le client demande au proxy d'interroger le serveur cible. Ce dernier répond au proxy qui communique alors la réponse au client. Dans ce mode, le client est configuré pour utiliser un proxy et il modifie les requêtes HTTP en fonction. |
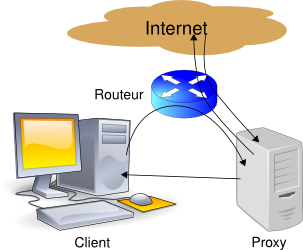 |
Dans le cas du proxy transparent, le client ignore l'existence du proxy. Il croit envoyer ses requêtes directement au serveur cible, mais ses requêtes sont détournées vers le proxy par le routeur. Le serveur cible répond au proxy qui retransmet la réponse au client, mais ce dernier croit l'avoir reçue directement du serveur cible. |
Nous discuterons plus tard de l'intérêt comparé des deux façons d'utiliser notre proxy.
II-C-2. Le logiciel▲
Squid, principal composant de ce système, assure les fonctions de :
- cache, pour optimiser la bande passante ;
- identification des utilisateurs, nous en verrons une simpliste et une nettement plus complexe ;
- filtrage d'accès « basique », mais déjà intéressant.
SquidGuard propose un filtrage très puissant d'accès au web, en fonction :
- de groupes d'utilisateurs, définis de diverses manières. Ici, nous nous baserons sur des IP ou des groupes d'IP, mais il est possible d'utiliser l'identification des utilisateurs mise en place sur Squid ;
- de listes de domaines et d'URI qui serviront à définir soit des cibles autorisées, soit des cibles interdites (listes blanches, listes noires) ;
- de plages horaires pendant lesquelles l'accès sera autorisé ou interdit.
Et bien d'autres choses encore, que nous ne verrons pas ici.
II-D. Principe de fonctionnement▲
Squid tourne en tâche de fond (daemon). Il écoute sur un port spécifique (3128 par défaut, mais il est possible d'utiliser 8080, plus habituel pour un proxy HTTP). L'éventuel module d'identification vient se greffer dessus, ce qui fait apparaitre un certain nombre de processus fils (5 par défaut).
SquidGuard vient également se greffer dessus et apparait lui aussi sous la forme de processus fils (également 5 par défaut).
Au total, une fois Squid configuré, il n'y aura qu'à démarrer Squid et les processus d'identification et de filtrage avancé démarreront avec.
Pour aller très vite, SquidGuard utilise le format de bases de données Berkeley pour travailler. Pour définir ces bases, l'administrateur a recours à des fichiers au format texte qui seront précompilés en base de données ou compilés à la volée, suivant la façon de travailler.
Nous verrons que les « destination groups » constituent des bases précompilées, alors que les « blacklists » sont compilées à la volée et résident uniquement en mémoire. Ce principe est à éviter autant que possible, dans la mesure où il consomme énormément de ressources au démarrage de chaque instance de SquidGuard.
II-E. Administration du tout▲
Les dernières versions (disponibles dans Lenny) de Squid (3 3.0.STABLE4-1) et SquidGuard (1.2.0) ont subi beaucoup de changements et les modules webmin ne sont, à l'heure où ces lignes sont écrites, plus adaptés. Nous serons donc obligés de mettre les mains directement dans le cambouis des fichiers de configuration.
Il faut faire très attention à ce que l'on fait et vérifier chaque fois que nécessaire que le but recherché est atteint. SquidGuard réserve pas mal de (mauvaises) surprises à ce propos.
Dans le cas de SquidGuard principalement, une gestion fine des bases de données pour les groupes de destination et les blacklists ne pourra se faire qu'à partir de la ligne de commande. Nous ne ferons qu'effleurer le problème, si vous en arrivez là , c'est que vous êtes déjà assez pointus sur le sujet pour pouvoir vous débrouiller tout seul avec la documentation (pauvre et laconique, il faut bien le dire).
II-F. Utiliser un proxy sur https▲
Cette question, qui semble venir comme un cheveu sur la soupe, est tout de même l'une des premières questions à se poser, lorsque l'on désire mettre en place un serveur proxy comme Squid :
- sur https, les échanges sont chiffrés et ne peuvent être mis en cache. Utiliser Squid pour ses fonctions de cache n'offre ici aucun intérêt ;
- https authentifie au moins le serveur interrogé, de manière à ce que le client soit « sûr » qu'il s'adresse au serveur réellement choisi. Qu'advient-il de cette certitude, si la connexion passe par un intermédiaire ?
Lorsque nous utilisons un serveur proxy de façon « volontaire » (par le paramétrage de notre navigateur), nous savons que ce paramétrage modifie le comportement dudit navigateur, qui va alors envoyer toutes ses requêtes sur le proxy (voir le chapitre sur HTTP). Dans une telle situation, si le client peut authentifier le serveur proxy, sa connexion https peut à la rigueur encore être considérée comme fiable. Dans ce cadre, Squid peut assumer cette fonction. Mais dans le cas du passage par un proxy « involontaire » (proxy transparent), le client ne sait pas qu'il passe par un tel dispositif, son navigateur n'est pas paramétré pour s'adresser à un serveur proxy, le trafic est dérouté de façon « transparente ». Dans une telle situation, la démarche deviendrait malhonnête, à supposer qu'il soit possible de le faire de façon fonctionnelle.
III. Squid▲
III-A. Configuration matĂ©rielle utilisĂ©e▲
Un PII 300 MHz, 256 Mo de RAM et 20 G0 de disque dur devraient largement suffire pour un réseau d'une centaine de postes. La machine de test s'appelle « venus ». Elle est indépendante du routeur NAT. Elle est animée par Lenny (testing) et nous testerons le tout avec Squid 3.0.STABLE4-1. Enfin, nous vérifierons que ce que nous avons fait est compatible avec Squid 2.6, également fourni dans la Lenny.
Rien n'empĂŞche cependant d'installer Squid/SquidGuard sur la mĂŞme machine que le routeur NAT, ce qui simplifiera mĂŞme les choses, surtout si l'on souhaite rendre le proxy transparent.
III-B. Installation▲
Nous supposons que vous êtes sorti victorieux d'une installation de la « Lenny », que votre configuration réseau fonctionne.
Depuis Squid 2.4, beaucoup de choses ont changé dans le fichier de configuration. Quant à SquidGuard, il change de version de base de données Berkeley. Ce sont toutes ces raisons qui m'ont conduit à réécrire ce chapitre.
# apt-get install squid3
Lecture des listes de paquets... Fait
Construction de l'arbre des dépendances... Fait
Les paquets supplémentaires suivants seront installés :
squid3-common
Paquets suggérés :
squid3-client squid3-cgi resolvconf smbclient
Les NOUVEAUX paquets suivants seront installés :
squid3 squid3-common
0 mis à jour, 2 nouvellement installés, 0 à enlever et 0 non mis à our.
Il est nécessaire de prendre 985ko dans les archives.
Après dépaquetage, 6312ko d'espace disque supplémentaire seront utilisés.
Souhaitez-vous continuer [O/n]Â ?
Réception de : 1 http://mir1.ovh.net testing/main squid3-common 3.0.STABLE-4 [246kB]
Réception de : 2 http://mir1.ovh.net testing/main squid3 3.0.STABLE-4 [739kB]
985ko réceptionnés en 2s (342ko/s)
Sélection du paquet squid3-common précédemment désélectionné.
(Lecture de la base de données... 26690 fichiers et répertoires déjà installés.)
DĂ©paquetage de squid3-common (Ă partir de .../squid3-common_3.0.STABLE4_all.deb) ...
Sélection du paquet squid3 précédemment désélectionné.
DĂ©paquetage de squid3 (Ă partir de .../squid3_3.0.STABLE4_i386.deb) ...
Paramétrage de squid3-common (3.0.STABLE-4) ...
Paramétrage de squid3 (3.0.STABLE-4) ...
Creating Squid HTTP proxy 3.0 spool directory structure
2007/05/28 18:05:46| Creating Swap Directories
2007/05/28 18:05:46| /var/spool/squid3 exists
2007/05/28 18:05:46| Making directories in /var/spool/squid3/00
2007/05/28 18:05:46| Making directories in /var/spool/squid3/01
2007/05/28 18:05:46| Making directories in /var/spool/squid3/02
2007/05/28 18:05:46| Making directories in /var/spool/squid3/03
2007/05/28 18:05:46| Making directories in /var/spool/squid3/04
2007/05/28 18:05:46| Making directories in /var/spool/squid3/05
2007/05/28 18:05:47| Making directories in /var/spool/squid3/06
2007/05/28 18:05:47| Making directories in /var/spool/squid3/07
2007/05/28 18:05:47| Making directories in /var/spool/squid3/08
2007/05/28 18:05:47| Making directories in /var/spool/squid3/09
2007/05/28 18:05:47| Making directories in /var/spool/squid3/0A
2007/05/28 18:05:48| Making directories in /var/spool/squid3/0B
2007/05/28 18:05:48| Making directories in /var/spool/squid3/0C
2007/05/28 18:05:48| Making directories in /var/spool/squid3/0D
2007/05/28 18:05:48| Making directories in /var/spool/squid3/0E
2007/05/28 18:05:48| Making directories in /var/spool/squid3/0F
Restarting Squid HTTP Proxy 3.0: squid3.
eros:/etc#Comme vous le voyez, on l'installe et il démarre tout seul.
# ps aux | grep [s]quid
root 571 0.0 1.8 3824 1124 ? S 16:26 0:00 /usr/sbin/squid3 -D -sYC
proxy 574 0.8 8.2 8468 5068 ? S 16:26 0:03 (squid) -D -sYCEffectivement, il tourne. N'y aurait-il rien de plus à faire ? Vérifions tout de suite. Squid utilise par défaut le port 3128. Configurons donc un navigateur du LAN pour l'utiliser et essayons un URI au hasard…

C'était trop beau… Il faudra déjà mettre les mains dans le cambouis. Notez qu'il vaut mieux une configuration qui interdise trop qu'une configuration qui, par défaut, autorise trop, comme font certains…
III-C. Configuration minimale▲
Les ACL (Access Control Lists) permettent de définir des conditions sur les IP, les ports, le contenu de certains textes, et j'en passe. Si vous voulez tout savoir sur les diverses ACL de Squid, ne comptez pas sur moi, comptez plutôt sur la documentation officielle.
Le fichier de configuration est /etc/squid3/squid.conf. C'est devenu une habitude de commenter copieusement le fichier de configuration, au point qu'il devient plus un « manual » qu'un fichier de configuration. J'ai personnellement du mal à m'habituer à cette tendance. Aussi, je vous propose cette petite manipulation préliminaire :
# cd /etc/squid3
# mv squid.conf squid.conf.origin
# cat squid.conf.origin | egrep -v -e '^[:blank:]*#|^$' > squid.conf(J'adore la clarté des expressions régulières.)
Ce qui permet d'obtenir un « vrai » fichier de configuration :
acl manager proto cache_object
acl localhost src 127.0.0.1/255.255.255.255
acl to_localhost dst 127.0.0.0/8
acl SSL_ports port 443
acl Safe_ports port 80 # http
acl Safe_ports port 21 # ftp
acl Safe_ports port 443 # https
acl Safe_ports port 70 # gopher
acl Safe_ports port 210 # wais
acl Safe_ports port 1025-65535 # unregistered ports
acl Safe_ports port 280 # http-mgmt
acl Safe_ports port 488 # gss-http
acl Safe_ports port 591 # filemaker
acl Safe_ports port 777 # multiling http
acl CONNECT method CONNECT
http_access allow manager localhost
http_access deny manager
http_access deny !Safe_ports
http_access deny CONNECT !SSL_ports
http_access allow localhost
http_access deny all
icp_access allow all
http_port 3128
hierarchy_stoplist cgi-bin ?
access_log /var/log/squid3/access.log squid
acl QUERY urlpath_regex cgi-bin \?
cache deny QUERY
refresh_pattern ^ftp: 1440 20% 10080
refresh_pattern ^gopher: 1440 0% 1440
refresh_pattern . 0 20% 4320
icp_port 3130
coredump_dir /var/spool/squid3Ceci n'empêche bien sûr pas de lire le fichier squid.conf.origin pour se documenter sur la configuration.
Dans un premier temps, disons pour aller très vite au but que :
- les « ACL » (Access Control List) permettent de définir, par exemple, une plage d'adresses IP, celles qui constituent notre réseau local ;
- les « http_access » (restrictions) qui définissent l'autorisation ou l'interdit, pour une ACL donnée.
Les restrictions indiquent quoi faire lorsque ces conditions sont vérifiées. On autorise ou on interdit en fonction d'une ACL ou d'un groupe d'ACL, le sens de « restriction » est donc à prendre avec un peu de recul, une restriction pouvant être une autorisation. La première restriction vérifiée est la bonne, d'où l'importance de l'ordre dans lequel elles sont placées.
Sans faire une analyse détaillée, nous voyons que dans la configuration par défaut, seul « localhost » peut utiliser le proxy (Allow localhost). Si cette condition n'est pas respectée, la règle suivante étant deny all, personne ne passe. Il nous faut donc faire intervenir la notion de réseau local.
III-C-1. CrĂ©er une ACL reprĂ©sentant le LAN▲
Bien entendu, l'idée de faire plutôt Allow all est une mauvaise idée. Si votre proxy a un pied dans l'Internet (s'il est installé sur la passerelle), vous risquez un proxy ouvert, avec tous les usages pervertis que l'on peut en faire…
Modifions le fichier squid.conf de cette manière :
acl manager proto cache_object
acl localhost src 127.0.0.1/255.255.255.255
acl to_localhost dst 127.0.0.0/8
acl SSL_ports port 443
acl Safe_ports port 80 # http
acl Safe_ports port 21 # ftp
acl Safe_ports port 443 # https
acl Safe_ports port 70 # gopher
acl Safe_ports port 210 # wais
acl Safe_ports port 1025-65535 # unregistered ports
acl Safe_ports port 280 # http-mgmt
acl Safe_ports port 488 # gss-http
acl Safe_ports port 591 # filemaker
acl Safe_ports port 777 # multiling http
acl CONNECT method CONNECT
acl LocalNet src 192.168.0.0/24
http_access allow manager localhost
http_access deny manager
http_access deny !Safe_ports
http_access deny CONNECT !SSL_ports
http_access allow localhost
http_access allow LocalNet
http_access deny all
icp_access allow all
http_port 3128
hierarchy_stoplist cgi-bin ?
access_log /var/log/squid3/access.log squid
acl QUERY urlpath_regex cgi-bin \?
cache deny QUERY
refresh_pattern ^ftp: 1440 20% 10080
refresh_pattern ^gopher: 1440 0% 1440
refresh_pattern . 0 20% 4320
icp_port 3130
coredump_dir /var/spool/squid3Nous avons créé une ACL nommée LocalNet représentant notre réseau local (acl LocalNet src 192.168.0.0/24), et lui avons donné l'autorisation de passer le proxy (http_access allow LocalNet). Nous relançons Squid :
# /etc/init.d/squid3 reload
Reloading Squid HTTP Proxy 3.0 configuration files.
done.Et cette fois-ci :
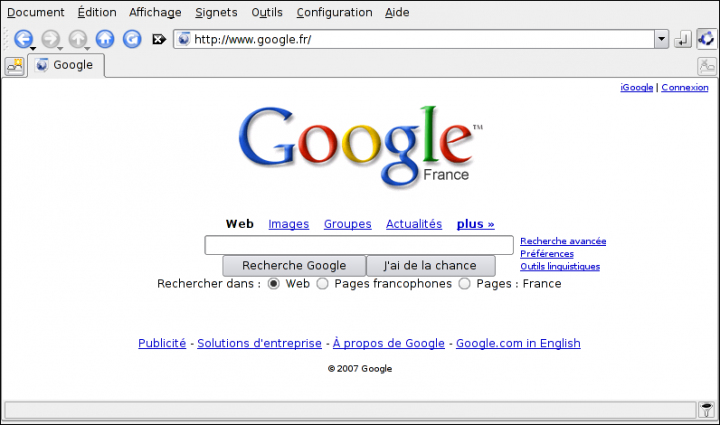
Nous disposons d'un proxy cache en état de marche pour notre réseau local.
IV. Plus sur Squid▲
IV-A. Affiner la configuration▲
Il y a deux points importants, qu'il peut ĂŞtre utile d'Ă©tudier, et qui correspondent aux deux fonctions principales d'un proxy.
IV-A-1. Identifier les utilisateurs▲
Attention. Vous aurez des ennuis pour identifier vos utilisateurs, si vous comptez rendre votre proxy transparent. Les deux fonctionnalités sont incompatibles.
Dans la configuration mise en œuvre jusqu'ici, nous ne faisions pas de contrôle sur les utilisateurs, seulement sur les IP des machines clientes. Vous pouvez souhaiter identifier vos utilisateurs lorsqu'ils vont surfer sur le Net. Dans ce cas, il vous faudra mettre en place un système d'identification (et renoncer au mode transparent).
Il y a plusieurs méthodes disponibles pour authentifier les utilisateurs du proxy. Elles font toutes appel à un programme extérieur, différent suivant le moyen choisi. Debian propose les modules suivants :
squid_ldap_auth, msnt_auth, ncsa_auth, pam_auth, sasl_auth, smb_auth, yp_auth, getpwname_auth, ntlm_auth, digest_ldap_auth, digest_pw_auth…Je ne les ai pas tous essayĂ©s, dans une autre vie peut-ĂŞtre ? Nous verrons un peu :
- ncsa_auth qui permet d'identifier les utilisateurs à partir d'un fichier local de type « htpasswd » ;
- ntlm_auth qui permet d'identifier les utilisateurs Ă partir d'un annuaire Active Directory dans un domaine Microsoft.
Nous allons dans un premier temps essayer ncsa_auth, ce ne sera peut-être pas le plus utile, surtout si le réseau local est un domaine Microsoft Windows, mais c'est le plus simple à mettre en œuvre.
IV-A-1-a. Construire un fichier d'utilisateurs▲
Nous allons créer un fichier /,etc./squid/users
# touch /etc/squid3/usersNous le remplissons ensuite avec la commande htpasswd, normalement fournie dans le paquet apache-common.
# htpasswd -b /etc/squid3/users <nom de l'utilisateur> <mot de passe>À répéter autant de fois que nécessaire avec des vrais noms d'utilisateurs et des vrais mots de passe…
Le fichier se remplit comme suit :
# cat /etc/squid3/users
user1:ZNlvws1XtZpQE
user2:F2UUyQD41v.zw
user3:zpJXchoMHUpv2Notez que les mots de passe sont chiffrés.
Vérifions que ceci fonctionne, en lançant « à la main » le module d'authentification /usr/lib/ncsa_auth. Nous entrerons alors dans une boucle où il faudra entrer sur une ligne un nom d'utilisateur et son mot de passe, séparés par une espace :
# /usr/lib/squid3/ncsa_auth /etc/squid3/users
user1 password1
OK
user2 password2
OK
user3 password3
OK
machin chose
ERR No such userLe système répond par OK ou par ERR suivant que l'authentification réussit ou non.
Sortez de la boucle avec un ctrl-d.
Si l'authentification fonctionne comme ceci, c'est déjà bon signe.
IV-A-1-b. Configurer Squid pour rĂ©clamer l'identification de vos utilisateurs▲
Nous devons commencer par fournir quelques directives de type auth_param :
auth_param basic program /usr/lib/squid3/ncsa_auth /etc/squid3/users
auth_param basic children 5
auth_param basic realm Squid proxy-caching web server
auth_param basic credentialsttl 2 hoursprogram, indiquez le chemin du module ncsa_auth, suivi du chemin du fichier des utilisateurs, séparés par une espace.
children, 5 est une valeur usuelle. Si vous avez de nombreux utilisateurs, il sera peut-être nécessaire d'augmenter ce nombre.
realm, n'est rien d'autre qu'un texte qui apparaîtra dans la fenêtre de demande d'identification.
credentialsttl, durée de vie de l'identification. À condition bien sûr que le navigateur ne soit pas fermé avant.
Il nous faut maintenant créer une ACL supplémentaire, pour obliger l'identification,
acl Users proxy_auth REQUIREDPuis n'autoriser l'accès que si le client est dans notre réseau et que l'identification est réussie :
http_access allow LocalNet UsersCeci nous conduit à un fichier de configuration de la forme :
auth_param basic program /usr/lib/squid3/ncsa_auth /etc/squid3/users
auth_param basic children 5
auth_param basic realm Squid proxy-caching web server
auth_param basic credentialsttl 2 hours
acl manager proto cache_object
acl localhost src 127.0.0.1/255.255.255.255
acl to_localhost dst 127.0.0.0/8
acl SSL_ports port 443
acl Safe_ports port 80 # http
acl Safe_ports port 21 # ftp
acl Safe_ports port 443 # https
acl Safe_ports port 70 # gopher
acl Safe_ports port 210 # wais
acl Safe_ports port 1025-65535 # unregistered ports
acl Safe_ports port 280 # http-mgmt
acl Safe_ports port 488 # gss-http
acl Safe_ports port 591 # filemaker
acl Safe_ports port 777 # multiling http
acl CONNECT method CONNECT
acl LocalNet src 192.168.0.0/24
acl Users proxy_auth REQUIRED
http_access allow manager localhost
http_access deny manager
http_access deny !Safe_ports
http_access deny CONNECT !SSL_ports
http_access allow localhost
http_access allow LocalNet Users
http_access deny all
icp_access allow all
http_port 3128
hierarchy_stoplist cgi-bin ?
access_log /var/log/squid3/access.log squid
acl QUERY urlpath_regex cgi-bin \?
cache deny QUERY
refresh_pattern ^ftp: 1440 20% 10080
refresh_pattern ^gopher: 1440 0% 1440
refresh_pattern . 0 20% 4320
icp_port 3130
coredump_dir /var/spool/squid3Application des changements, nous vérifions que maintenant le module d'authentification est bien chargé :
# ps aux | grep [s]quid
root 1536 0.0 1.1 3824 1124 ? S 14:22 0:00 /usr/sbin/squid3 -D -sYC
proxy 1538 0.0 7.0 9616 6712 ? S 14:22 0:04 (squid) -D -sYC
proxy 2178 0.0 0.4 1712 388 ? S 16:30 0:00 (ncsa_auth) /,etc./squid/users
proxy 2179 0.0 0.4 1712 388 ? S 16:30 0:00 (ncsa_auth) /,etc./squid/users
proxy 2180 0.0 0.4 1712 388 ? S 16:30 0:00 (ncsa_auth) /,etc./squid/users
proxy 2181 0.0 0.4 1712 388 ? S 16:30 0:00 (ncsa_auth) /,etc./squid/users
proxy 2182 0.0 0.4 1712 388 ? S 16:30 0:00 (ncsa_auth) /,etc./squid/usersCette fois-ci, il y est. Ça devrait donc fonctionner :
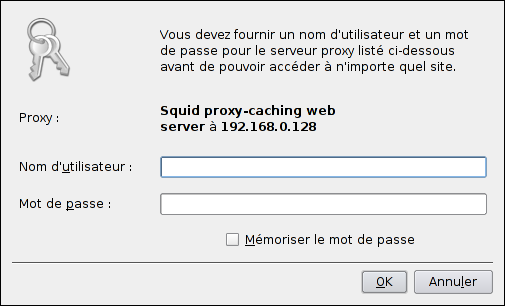
Et voilà . Pour accéder au monde extérieur, Squid nécessite maintenant une identification.
Si nous allons faire un petit tour dans les dernières lignes de /var/log/squid/access.log, nous constatons que le nom d'utilisateur figure pour chaque requête :
1180428383.041 0 192.168.0.15 TCP_MEM_HIT/200 632 GET http://pages-
perso.esil.univ-mrs.fr/index.html
user1 NONE/- text/htmlLa procédure qui permet d'identifier les utilisateurs à partir d'Active Directory est nettement plus complexe. Elle est détaillée à la page suivante.
IV-B. Optimiser le cache▲
Un proxy sert à optimiser la bande passante utilisée sur le Net, en permettant de garder en cache les pages les plus souvent visitées. Si c'est une de vos principales préoccupations, il sera probablement nécessaire d'agir sur les diverses options du cache. Passez alors du temps à lire la documentation. Vous pourrez agir sur la taille du cache, sa répartition sur les divers disques durs…
Pour réaliser correctement une telle opération, il vous faudra installer d'abord des outils d'audit de performance dudit cache. Détailler ces opérations ici nous mènerait trop loin. (Il y a une doc assez complète avec Squid.)
IV-C. Rendre le proxy transparent▲
Attention…
- Cette méthode est incompatible avec l'authentification des utilisateurs. Même si Squid est configuré comme nous l'avons vu pour l'authentification ncsa, celle-ci ne fonctionnera plus.
- Cette méthode ne supporte que HTTP. FTP est impossible en mode transparent,
- un seul port peut être redirigé de façon transparente, le 80, de préférence, puisque c'est le port habituel pour HTTP.
Utiliser un proxy nécessite normalement de configurer son « butineur » de manière à ce qu'il interroge toujours le proxy, quelle que soit la cible.
Vos utilisateurs ont donc généralement la main sur ce paramétrage, et pourront probablement passer outre le proxy, s'ils le décident, contournant par le fait toutes vos stratégies. Il existe cependant deux moyens d'éviter ceci :
- utilisez votre firewall pour bloquer pour vos postes clients l'accès direct à l'Internet par les ports HTTP et https (80, 443, 563…). De cette manière, vos utilisateurs n'auront d'autre possibilité que de passer par le proxy (sauf pour des serveurs exotiques, qui utiliseraient un autre port), c'est la seule manière possible si vous souhaitez identifier vos utilisateurs ;
- rendre le proxy transparent, ce qui veut dire que configurés ou non, les requêtes HTTP passeront quand même par le proxy. Pour arriver à ce résultat, il faut réaliser deux opérations :
- rediriger en PREROUTING le port 80 (vous devrez vous contenter d'un seul port transparent) vers le port proxy sur son port (3128 par défaut pour Squid), ça se fait sans problème sur votre routeur NAT avec IPtables,
- configurer correctement Squid pour qu'il interprète convenablement les requêtes HTTP qu'il reçoit.
IV-C-1. La règle de redirection▲
Voici la règle à ajouter sur votre passerelle, en admettant que votre réseau soit dans 192.168.0.0 et que votre proxy possède l'adresse 192.168.0.252. Nous supposons que le proxy est installé sur la machine qui assure également le rôle de passerelle (commande à entrer sur une seule ligne, bien entendu) :
iptables -t nat -A PREROUTING -s 192.168.0.0/255.255.255.0 -p tcp -m tcp --dport 80 -j REDIRECT --to-ports 3128De multiples solutions sont possibles pour placer un proxy transparent ailleurs que sur la passerelle. Elles sont plus ou moins compliquées à gérer au niveau du routage. Si la question vous intéresse, voyez :
Avec un routeur à trois voies, par exemple deux réseaux IP (disons 192.168.0.0 et 192.168.1.0), et un accès Internet, si le LAN est sur 192.168.0.0, il faudra placer le proxy sur 192.168.1.0, disons 192.168.1.2. La règle IPtables s'écrira alors :
iptables -t nat -A PREROUTING -s 192.168.0.0/255.255.255.0 -p tcp -m tcp --dport 80 -j DNAT --to-destination 192.168.1.2:3128Bien entendu, il faudra que le routage se fasse entre les réseaux 192.168.0.0 et 192.168.1.0.
IV-C-2. ParamĂ©trage de Squid▲
Comme nous l'avons vu dans le chapitre sur HTTP, Le client HTTP n'agit pas de la même manière suivant qu'il a affaire à un proxy ou non. Ici, le client ne sait pas qu'il y a un proxy, il agit donc comme s'il interrogeait directement le serveur cible, alors que ce n'est pas le cas. Ça ne fonctionnera bien entendu pas, si Squid n'est pas informé de cette situation.
Mais Squid sait contourner la difficulté, de façon très simple depuis la version 2.6 au moins, en ajoutant simplement le mot « transparent » sur la ligne de définition du port utilisé :
http_port 3128 transparentIV-D. Conclusions▲
Comme nous l'avons vu, la transparence du proxy entraîne de nombreuses restrictions. À moins que vous y teniez absolument, mieux vaut choisir une autre solution, principalement si vous voulez cacher le FTP et/ou faire passer le HTTPS par votre proxy (il n'y aura pas d'effet de cache, juste un transfert des données comme dans un tunnel) ou encore, si vous devez identifier vos utilisateurs.
Dans la suite de cet exposé, Squid ne sera pas transparent.
Pour ce qui est du filtrage d'accès, il est possible de faire déjà des choses avec Squid tout seul, mais le « helper » SquidGuard que nous allons voir dans la suite rend inutiles les tentatives de filtrage avec les seuls moyens de Squid.
V. Active Directory▲
V-A. Identification avancĂ©e▲
Si votre réseau est un peu important, que vous avez à gérer de nombreux utilisateurs, il se peut que vous ayez déjà une base de données contenant des couples user / password quelque part. L'idée serait alors excellente de vouloir configurer Squid pour qu'il identifie les utilisateurs depuis cette base. Les annuaires LDAP sont très souvent utilisés dans ce but, et Squid dispose de ce qu'il faut pour y arriver.
Nous allons voir comment faire dans le cas d'un annuaire LDAP un peu particulier.
V-B. Utiliser Active Directory▲
Active Directory n'est autre, en effet, qu'un annuaire LDAP revu et compliqué (enrichi ?) par Microsoft. Il est utilisé dans les domaines Microsoft, entre autres choses, pour stocker la base de données des utilisateurs, permettant ainsi la gestion de leurs comptes de façon centralisée. Un protocole de type Kerberos est employé pour l'authentification de l'utilisateur lorsqu'il ouvre une session sur un hôte quelconque du domaine.
Les systèmes GNU/Linux disposent de tous les outils pour intégrer un hôte Linux à un domaine Microsoft. En effet, dans cette architecture, les hôtes disposent aussi d'un compte dans le domaine, ce dernier étant à rapprocher du concept de royaume (realm) de Kerberos.
Le prérequis sera donc d'intégrer notre proxy au domaine Microsoft. Une fois cette opération réalisée, il deviendra possible d'authentifier un utilisateur en s'appuyant sur Active Directory.
Nous arriverons à un mode de fonctionnement assez agréable, puisque les utilisateurs déjà authentifiés dans le domaine Microsoft n'auront pas besoin de se réidentifier pour être autorisés à passer le proxy. La procédure a été vérifiée sur des hôtes clients Windows XP, elle doit être également validée sur des hôtes clients Linux intégrés au domaine et dont les sessions des utilisateurs sont authentifiées par Actrive DIrectory, mais je ne l'ai pas expérimenté.
V-C. ProcĂ©dure de configuration du serveur hĂ´te de Squid▲
V-C-1. IntĂ©gration dans le domaine Microsoft▲
Il nous faut installer les utilitaires clients Kerberos 5, samba 3 et winbind :
apt-get install krb5-user krb5-config samba-common samba winbindNe vous préoccupez pas trop de la configuration postinstallation, nous la reprendrons entièrement par la suite.
V-C-1-a. Configuration du client Kerberos▲
N'étant pas spécialiste de kerberos, tant s'en faut, je me contenterai de vous donner une recette. Nous supposons que nous avons un domaine (Active Directory) qui dispose du nom domaine.mrs (et DOMAINE pour la compatibilité pré2000) :
~# cat /etc/krb5.conf
[libdefaults]
default_realm = DOMAINE.MRS
dns_lookup_realm = false
dns_lookup_kdc = false
[realms]
DOMAINE.MRS = {
kdc = 192.168.0.1
kdc = 192.168.0.2
admin_server = 192.168.0.1
default_domain = DOMAINE.MRS
}
[domain_realm]
.domaine.mrs = DOMAINE.MRS
domaine.mrs = DOMAINE.MRS
[logging]
default = FILE:/var/log/krb5.log
kdc = FILE:/var/log/krb5kdc.log
admin-server = FILE:/var/log/krb5adm.log
[appdefaults]
pam = {
debug = false
ticket_lifetime = 36000
renew_lifetime = 36000
forwardable = true
krb4_convert = false
}- les adresses IP indiquées par kdc dans le paragraphe [realms] correspondent à vos contrôleurs de domaine Microsoft (vous en avez bien deux, n'est-ce pas ?) ;
- l'adresse IP indiquée par admin_server correspond au contrôleur « Maître d'opérations » (vous avez, n'est-ce pas, les cinq rôles « FSMO » attribués au même contrôleur ?).
V-C-1-a-i. VĂ©rification▲
La commande « kinit » va permettre de vérifier que l'on peut obtenir un ticket kerberos pour un utilisateur du domaine ActiveDirectory :
# kinit -V machin@DOMAINE.MRS
Password for machin@DOMAINE.MRS:
Authenticated to Kerberos v5La commande « klist » permet de lister les tickets obtenus :
# klist
Ticket cache: FILE:/tmp/krb5cc_0
Default principal: machin@DOMAINE.MRS
Valid starting Expires Service principal
11/15/07 10:36:18 11/15/07 20:36:22 krbtgt/DOMAINE.MRS@DOMAINE.MRS
renew until 11/15/07 20:36:18
Kerberos 4 ticket cache: /tmp/tkt0
klist: You have no tickets cachedmachin@domaine.mrs a bien été authentifié et le ticket kerberos a bien été reçu.
Non ? Alors revoyez votre configuration parce qu'habituellement, ça fonctionne bien.
V-C-1-b. Configuration de samba▲
# cat /etc/samba/smb.conf
[global]
workgroup = DOMAINE
realm = DOMAINE.EME
security = ADS
password server = 192.168.0.1 192.168.0.2
client use spnego = yes
client ntlmv2 auth = yes
syslog = 0
log file = /var/log/samba/log.%m
max log size = 1000
announce version = 4
announce as = NT Workstation
dns proxy = No
idmap uid = 167771-335549
idmap gid = 167771-335549
winbind use default domain = Yes
invalid users = root- le workgroup correspond au nom « plat » du domaine Microsoft ;
- le realm correspond au royaume Kerberos ;
- la security = ADS (Active Directory Server) nécessite que la machine soit intégrée au domaine Microsoft et que le client kerberos soit installé et configuré, ce qui permettra d'utiliser ce protocole pour l'authentification des clients ;
- les password server sont bien entendu les contrĂ´leurs de domaine Microsoft.
Les autres paramètres sont sans doute de moindre importance. Plongez-vous dans la lecture du manuel de smb.conf pour avoir tous les détails sur les divers paramètres.
V-C-1-c. Configuration de winbind▲
Modifiez comme suit le fichier « /etc/nsswitch.conf » :
passwd: compat winbind
group: compat winbind
shadow: compat
hosts: files dns
networks: files
protocols: db files
services: db files
ethers: db files
rpc: db files
netgroup: nisRelancez samba et winbind :
# invoke-rc.d winbind restart
Stopping the Winbind daemon: winbind.
Starting the Winbind daemon: winbind.
# invoke-rc.d samba restart
Stopping Samba daemons: nmbd smbd.
Starting Samba daemons: nmbd smbd.V-C-1-d. IntĂ©gration au domaine▲
net ads join -U <un login d'Administrateur du domaine> -S <adresse d'un contrôleur de domaine>En principe, un message doit vous annoncer que l'opération s'est bien déroulée et vous devriez retrouver votre proxy dans les « computers » dans votre mmc de gestion de « Active Directory Users and Computers ».
V-C-1-d-i. VĂ©rification▲
La commande « wbinfo » doit vous permettre de vérifier que vous avez correctement accès aux listes des utilisateurs et des groupes du domaine ActiveDirectory :
# wbinfo -u
invité
machin
administrateur
...
# wbinfo -g
BUILTIN/administrators
BUILTIN/users
ordinateurs du domaine
utilisa. du domaine
propriétaires créateurs de la stratégie de groupe
administrateurs du schéma
contrĂ´leurs de domaine
invités du domaine
Ă©diteurs de certificats
...Ă€ ce moment, vous avez tout ce qu'il faut pour que Squid puisse par la suite identifier les utilisateurs depuis ActiveDirectory.
N'hésitez pas à relancer winbind et samba si besoin est.
V-C-2. Configuration de Squid▲
Squid va devoir utiliser le module ntlm_auth. Ici, il faut savoir quelque chose de plutôt important : il existe deux modules ntlm_auth, l'un fourni avec samba et l'autre avec Squid.
Bien que portant le même nom, ils ne fonctionnent pas de la même manière. Dans l'état actuel de ma machine de test :
- Samba: Version 3.0.28a ;
- winbindd: Version 3.0.28a ;
- Squid Cache: Version 3.0.STABLE4.
Je n'ai pas trouvé de solution pour fonctionner avec le ntlm_auth fourni avec Squid.
Comme c'est celui qui vient avec samba qui est le mieux documenté, nous allons utiliser celui-ci.
Vérifions déjà de façon simple s'il est capable d'authentifier un utilisateur inscrit dans Active Directory :
# ntlm_auth --username=machin --password=epikoi
NT_STATUS_OK: Success (0x0)Ça marche.
Bien entendu, dans Squid, ce sera un peu plus compliqué que ça. Nous devons ajouter dans squid.conf
auth_param ntlm program /usr/bin/ntlm_auth --helper-protocol=squid-2.5-ntlmsspPour indiquer que nous utilisons une authentification ntlm avec le module /usr/bin/ntlm_auth (fourni par Samba) qui, lui-même, utilisera le protocole squid-2.5-ntlmssp. Pourquoi squid-2.5-ntlmssp ? Il semble que rien n'ait changé depuis squid-2.5.
Comme ntlm_auth va être invoqué par l'utilisateur sous l'identité duquel squid est lancé (proxy pour Debian), il faudra que le répertoire /var/run/samba/winbindd_privileged soit accessible en lecture par l'utilisateur proxy. Voyons cela :
# ls -l /var/run/samba
total 604
...
drwxr-x--- 2 root winbindd_priv 17 mar 18 11:56 winbindd_privilegedUn moyen propre de résoudre le problème est d'ajouter l'utilisateur proxy au groupe winbindd_priv :
usermod -a -G winbindd_priv proxyNous pouvons aussi ajouter ces lignes dans squid.conf
auth_param ntlm children 5
auth_param ntlm keep_alive onLe nombre de processus peut être augmenté suivant le nombre d'utilisateurs qui passent par notre proxy.
Bien sûr, nous avons toujours l'ACL acl password proxy_auth REQUIRED ainsi que l'autorisation d'accès http_access allow LocalNet password.
Finalement :
auth_param ntlm program /usr/bin/ntlm_auth --helper-protocol=squid-2.5-ntlmssp
auth_param ntlm children 5
auth_param ntlm keep_alive on
acl manager proto cache_object
acl localhost src 127.0.0.1/255.255.255.255
acl to_localhost dst 127.0.0.0/8
acl SSL_ports port 443
acl Safe_ports port 80 # http
acl Safe_ports port 21 # ftp
acl Safe_ports port 443 # https
acl Safe_ports port 70 # gopher
acl Safe_ports port 210 # wais
acl Safe_ports port 1025-65535 # unregistered ports
acl Safe_ports port 280 # http-mgmt
acl Safe_ports port 488 # gss-http
acl Safe_ports port 591 # filemaker
acl Safe_ports port 777 # multiling http
acl CONNECT method CONNECT
acl LocalNet src 192.168.0.0/24
acl password proxy_auth REQUIRED
http_access allow manager localhost
http_access deny manager
http_access deny !Safe_ports
http_access deny CONNECT !SSL_ports
http_access allow localhost
http_access allow LocalNet password
http_access deny all
icp_access allow all
http_port 3128
hierarchy_stoplist cgi-bin ?
access_log /var/log/squid3/access.log squid
acl QUERY urlpath_regex cgi-bin \?
cache deny QUERY
refresh_pattern ^ftp: 1440 20% 10080
refresh_pattern ^gopher: 1440 0% 1440
refresh_pattern . 0 20% 4320
icp_port 3130
coredump_dir /var/spool/squid3Normalement, en relançant Squid tout ceci devrait fonctionner.
V-C-2-a. Le client est un client du domaine▲
Si votre client est intégré au domaine et que l'utilisateur a donc ouvert une session authentifiée par un contrôleur de domaine, le navigateur (aussi bien IE que FireFox) devrait, s'il est configuré pour utiliser le proxy, envoyer automatiquement à Squid les informations nécessaires à l'authentification.
Autrement dit, l'utilisateur ne voit rien de particulier. L'administrateur, lui, verra dans les logs d'accès à Squid (/var/log/squid3/access.log) le nom de l'utilisateur qui a formulé les requêtes.
V-C-2-b. Le client n'est pas un client du domaine▲
Imaginons qu'un utilisateur ait le droit de connecter son portable sur votre réseau, mais que ce portable n'est pas intégré au domaine Windows. Dans ce cas, un accès à Squid amènera une fenêtre de demande d'authentification. L'utilisateur devra alors disposer d'un compte sur le domaine Microsoft et indiquer son nom d'utilisateur « complet » :
DOMAINE\machindans notre exemple.
VI. WPAD▲
VI-A. Qu'est-ce ?▲
Web Proxy AutoDiscovery. Découverte automatique du proxy. Il s'agit d'un protocole imaginé par Microsoft, qui permet d'effectuer automatiquement le paramétrage d'accès à l'Internet de son navigateur. Ce protocole n'est bien sûr pas exempt de failles de sécurité, soyez-en conscients si vous décidez de le mettre en application.
Bien que peu sûre, cette méthode reste tout de même tellement pratique qu'elle est souvent utilisée, et que les navigateurs modernes, aussi bien Internet Explorer que Mozilla Firefox ou Konqueror savent l'exploiter.
Puisque nous devrons configurer les clients HTTP pour passer par notre proxy, une méthode automatique simplifiera grandement nos rapports avec les utilisateurs du réseau.
VI-B. L'objectif Ă atteindre▲
Voyons un peu les diverses possibilités que propose Mozilla Firefox 2.x :
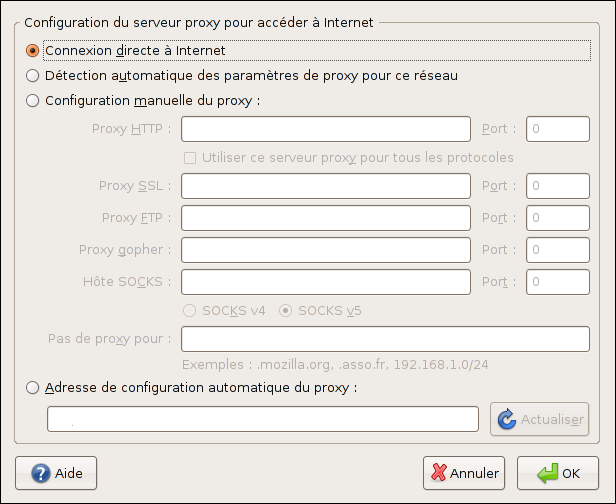
Par défaut, bien sûr, le butineur est configuré pour un accès direct à l'Internet, mais plusieurs autres possibilités sont offertes.
VI-B-1. Connexion manuelle▲
C'est probablement le meilleur moyen et aussi le plus sûr pour qui sait faire, mais allez expliquer la manip à quelques dizaines (centaines ?) d'utilisateurs débutants…
VI-B-2. Adresse de configuration automatique du proxy▲
Commençons par cette méthode. Il faut créer un fichier nommé (par convention) proxy.pac à la racine d'un site de votre intranet. Ce fichier doit contenir un script (JavaScript) qui définit une fonction bien particulière (et une seule), qui pourra par exemple ressembler à ceci :
function FindProxyForURL(url, host)
{
if(isPlainHostName(host) || dnsDomainIs(host, ".domaine.mrs" ))
{
return "DIRECT";
}
else
{
return "PROXY wpad.domaine.mrs:3128";
}
}Ce qui, traduit en français, veut dire :
fonction TrouveLeProxyPourUrl(URL, host)
{
s'il s'agit du nom de la machine locale
ou
de la machine dont le nom est "tests.domaine.mrs"
ou
de toutes les machines du domaine ".maison.mrs"
nous voulons une connexion directe (sans proxy)
sinon, nous utilisons le proxy "wpad.domaine.mrs" sur le port 3128
}Bien entendu, il est possible de faire beaucoup plus compliqué, mais ce type de scénario devrait répondre à la plupart des besoins. Normalement, le serveur HTTP doit disposer du type mime qui correspond à l'extension .pac. C'est le cas du serveur apache fourni dans les distributions Debian :
application/x-ns-proxy-autoconfig pac
C'est mieux, mais ce n'est pas encore assez simple. L'étape ultime serait de se contenter de cliquer sur « Détection automatique des paramètres proxy du réseau ». Pour y arriver, nous devons nous plonger un peu dans le protocole WPAD.
Les différentes documentations que l'on peut trouver sur le sujet évoquent la nécessité de disposer des structures suivantes :
- un serveur HTTP nommé wpad.<votre domaine.tld> (wpad.domaine.mrs dans l'exemple), qui soit en mesure de fournir un fichier proxy.pac ou wpad.dat ;
- l'information pour que le client trouve ce fichier doit quant à elle être donnée par l'une de ces voies :
- une option spécifique envoyée au client DHCP, ce qui nécessite l'emploi d'un serveur dhcp ;
- une résolution DNS, ce qui nécessite de disposer d'un serveur DNS ou, à défaut, de renseigner manuellement le fichier hosts de chaque client.
VI-B-2-a. ExpĂ©rience instructive▲
Souvent, dans la vie, rien ne vaut l'expérience. Voyons donc avec notre « sniffeur » favori, ce qu'il se passe lorsque nous demandons à notre navigateur de rechercher une configuration de proxy de façon automatique.
Nous disposons d'un réseau local, avec un serveur DNS et un domaine en bois : domaine.mrs. Tous nos clients sont configurés pour effectuer leurs résolutions de noms avec ce serveur DNS (192.168.0.250).
Le principe de la manip est simple : le sniffeur va capturer ce qu'il se passe lorsque nous configurons notre navigateur pour qu'il fasse une recherche automatique du proxy.
VI-B-2-a-i. Mozilla Firefox 2.x (Windows comme GNU/Linux)▲
No. Time Source Destination Protocol Info
1 0.000000 192.168.0.10 192.168.0.250 DNS Standard query A wpad.domaine.mrs
2 0.001591 192.168.0.250 192.168.0.10 DNS Standard query response, No such nameFirefox cherche à trouver l'adresse IP d'un hôte qui s'appellerait wpad.domaine.mrs. La solution DNS devrait donc pouvoir fonctionner, si ce serveur existait sur le réseau.
VI-B-2-a-ii. Internet Explorer 6 et 7 (Windows)▲
No. Time Source Destination Protocol Info
1 0.000000 192.168.0.10 192.168.0.250 DNS Standard query A wpad.domaine.mrs
2 0.001591 192.168.0.250 192.168.0.10 DNS Standard query response, No such nameMême chose. Pour une fois, les deux navigateurs auraient-ils le même comportement ? C'est plutôt une bonne nouvelle.
VI-B-2-a-iii. Konqueror (GNU/Linux)▲
No. Time Source Destination Protocol Info
1 0.000000 192.168.0.10 192.168.0.250 DNS Standard query A wpad.localdomain
2 0.001591 192.168.0.250 192.168.0.10 DNS Standard query response, No such nameQuand même, tout n'est pas si simple, ce qui a quelque chose de réconfortant dans le dur monde de l'informatique. Konqueror recherche wpad.localdomain, alors que Firefox, sur la même machine (GNU/Linux Ubuntu 7.04), recherchait bien wpad.maison.mrs. Pourquoi donc ?
Analyse du fichier /etc/resolv.conf :
# cat /etc/resolv.conf
# generated by NetworkManager, do not edit!
search maison.mrs
nameserver 192.168.0.250
Analyse du fichier /,etc./hosts :
# cat /,etc./hosts
127.0.0.1 localhost.localdomain localhost ubuntuSi nous modifions ce fichier comme suit :
# cat /,etc./hosts
127.0.0.1 localhost.domaine.mrs localhost ubuntuKonqueror va adopter un fonctionnement normal :
No. Time Source Destination Protocol Info
1 0.000000 192.168.0.10 192.168.0.250 DNS Standard query A wpad.domaine.mrs
2 0.001591 192.168.0.250 192.168.0.10 DNS Standard query response, No such nameIl n'est pas interdit de se demander pourquoi Konqueror adopte une méthode aussi tordue pour déduire le nom de domaine de la machine hôte, alors que le paramètre search du fichier resolv.conf est justement là pour donner cette information.
Bref, moyennant un minimum de précautions, les trois navigateurs adoptent le même comportement, à savoir chercher via DNS un serveur nommé wpad.maison.mrs. Donnons-leur ce qu'ils demandent, en agissant sur notre DNS (ou sur nos fichiers hosts). Comme il est dit dans les docs que l'on risque d'avoir besoin d'un fichier wpad.dat sur le serveur HTTP, autant le créer tout de suite :
ln -s /var/www/proxy.pac /var/www/wpad.datNous mettons en route notre sniffeur, nous ouvrons par exemple IE7, et le configurons pour qu'il récupère sa configuration proxy de façon automatique, puis nous allons visiter, toujours par exemple, www.grenouille.com :
No. Time Source Destination Protocol Info
1 0.000000 192.168.0.10 192.168.0.250 DNS Standard query A wpad.domaine.mrs
2 0.001852 192.168.0.250 192.168.0.10 DNS Standard query response CNAME tests.domaine.mrs A 192.168.0.128
3 0.003192 192.168.0.10 192.168.0.250 DNS Standard query A tests.domaine.mrs
4 0.004410 192.168.0.250 192.168.0.10 DNS Standard query response A 192.168.0.128
...
8 0.008375 192.168.0.10 192.168.0.128 HTTP GET /wpad.dat HTTP/1.1
...
10 0.009706 192.168.0.128 192.168.0.10 HTTP HTTP/1.1 200 OK (chemical/x-mopac-input)
...
16 0.021575 192.168.0.10 192.168.0.128 HTTP GET http://www.grenouille.com/ HTTP/1.1
...
19 0.025318 192.168.0.128 192.168.0.10 HTTP HTTP/1.0 407 Proxy Authentication Required (text/html)
...
29 8.091195 192.168.0.10 192.168.0.128 HTTP GET http://www.grenouille.com/ HTTP/1.1IE7 commence par chercher l'adresse IP de wpad.domaine.mrs (1, 2, 3 et 4), puis il cherche à récupérer dessus le fichier wpad.dat, comme annoncé (8). Le serveur lui répond (10) :
Frame 10 (519 bytes on wire, 519 bytes captured)
...
Hypertext Transfer Protocol
HTTP/1.1 200 OK\r\n
Request Version: HTTP/1.1
Response Code: 200
Date: Sat, 02 Jun 2007 13:24:49 GMT\r\n
Server: Apache/2.2.3 (Debian) PHP/5.2.0-10+lenny1\r\n
Last-Modified: Sat, 02 Jun 2007 13:05:52 GMT\r\n
ETag: "a00a61-cb-fdcd2c00"\r\n
Accept-Ranges: bytes\r\n
Content-Length: 203
Content-Type: chemical/x-mopac-input\r\n
\r\n
Media Type
Media Type: chemical/x-mopac-input (203 bytes)
0000 00 05 5d 47 f5 c5 00 30 84 3a 8c cd 08 00 45 00 ..]G...0.:....E.
0010 01 f9 34 78 40 00 40 06 82 ac c0 a8 00 80 c0 a8 ..4x@.@.........
0020 00 0a 00 50 06 6f 50 84 34 63 29 a2 04 4d 50 18 ...P.oP.4c)..MP.
0030 16 d0 7f dc 00 00 48 54 54 50 2f 31 2e 31 20 32 ......HTTP/1.1 2
0040 30 30 20 4f 4b 0d 0a 44 61 74 65 3a 20 53 61 74 00 OK..Date: Sat
0050 2c 20 30 32 20 4a 75 6e 20 32 30 30 37 20 31 33 , 02 Jun 2007 13
0060 3a 32 34 3a 34 39 20 47 4d 54 0d 0a 53 65 72 76 :24:49 GMT..Serv
0070 65 72 3a 20 41 70 61 63 68 65 2f 32 2e 32 2e 33 er: Apache/2.2.3
0080 20 28 44 65 62 69 61 6e 29 20 50 48 50 2f 35 2e (Debian) PHP/5.
0090 32 2e 30 2d 31 30 2b 6c 65 6e 6e 79 31 0d 0a 4c 2.0-10+lenny1..L
00a0 61 73 74 2d 4d 6f 64 69 66 69 65 64 3a 20 53 61 ast-Modified: Sa
00b0 74 2c 20 30 32 20 4a 75 6e 20 32 30 30 37 20 31 t, 02 Jun 2007 1
00c0 33 3a 30 35 3a 35 32 20 47 4d 54 0d 0a 45 54 61 3:05:52 GMT..ETa
00d0 67 3a 20 22 61 30 30 61 36 31 2d 63 62 2d 66 64 g: "a00a61-cb-fd
00e0 63 64 32 63 30 30 22 0d 0a 41 63 63 65 70 74 2d cd2c00"..Accept-
00f0 52 61 6e 67 65 73 3a 20 62 79 74 65 73 0d 0a 43 Ranges: bytes..C
0100 6f 6e 74 65 6e 74 2d 4c 65 6e 67 74 68 3a 20 32 ontent-Length: 2
0110 30 33 0d 0a 43 6f 6e 74 65 6e 74 2d 54 79 70 65 03..Content-Type
0120 3a 20 63 68 65 6d 69 63 61 6c 2f 78 2d 6d 6f 70 : chemical/x-mop
0130 61 63 2d 69 6e 70 75 74 0d 0a 0d 0a 66 75 6e 63 ac-input....func
0140 74 69 6f 6e 20 46 69 6e 64 50 72 6f 78 79 46 6f tion FindProxyFo
0150 72 55 52 4c 28 75 72 6c 2c 20 68 6f 73 74 29 0a rURL(URL, host).
0160 7b 0a 20 20 20 20 69 66 28 69 73 50 6c 61 69 6e {. if(isPlain
0170 48 6f 73 74 4e 61 6d 65 28 68 6f 73 74 29 20 7c HostName(host) |
0180 7c 20 64 6e 73 44 6f 6d 61 69 6e 49 73 28 68 6f | dnsDomainIs(ho
0190 73 74 2c 20 22 2e 6d 61 69 73 6f 6e 2e 6d 72 73 st, ".maison.mrs
01a0 22 20 29 29 0a 20 20 20 20 7b 0a 20 20 20 20 20 " )). {.
01b0 20 20 20 72 65 74 75 72 6e 20 22 44 49 52 45 43 return "DIREC
01c0 54 22 3b 0a 20 20 20 20 7d 20 65 6c 73 65 20 7b T";. } else {
01d0 0a 20 20 20 20 20 20 20 20 72 65 74 75 72 6e 20 . return
01e0 22 50 52 4f 58 59 20 77 70 61 64 2e 6d 61 69 73 "PROXY wpad.mais
01f0 6f 6e 2e 6d 72 73 3a 33 31 32 38 22 3b 0a 20 20 on.mrs:3128";.
0200 20 20 7d 0a 7d 0a 0a }.}..Nous retrouvons bien notre JavaScript dans la réponse. Notez le vilain Media Type: chemical/x-mopac-input qui est dû aux mime.types par défaut du système :
# cat /etc/mime.types | grep -e ' dat '
chemical/x-mopac-input mop mopcrt mpc dat zmtCe défaut ne semble pas affecter la configuration automatique qui fonctionne bien, puisque IE7 va maintenant transmettre notre requête au serveur proxy (16) :
Frame 16 (457 bytes on wire, 457 bytes captured)
...
Hypertext Transfer Protocol
GET http://www.grenouille.com/ HTTP/1.1\r\n
...
Frame 19 (1128 bytes on wire, 1128 bytes captured)
...
Hypertext Transfer Protocol
HTTP/1.0 407 Proxy Authentication Required\r\n
...
Line-based text data: text/html
...
<H1>ERROR</H1>
>H2>Cache Access Denied</H2>
...
While trying to retrieve the URL:
<A HREF="http://www.grenouille.com/">http://www.grenouille.com/</A>
<P>
The following error was encountered:
<UL>
<LI>
<STRONG>
Cache Access Denied.
...
<P>Sorry, you are not currently allowed to request:
<PRE> http://www.grenouille.com/</PRE>
from this cache until you have authenticated yourself.
...
You need to use Netscape version 2.0 or greater, or Microsoft Internet
Explorer 3.0, or an HTTP/1.1 compliant browser for this to work.
...Comme nous avons requis une identification, c'est le moment de s'exécuter. Notez au passage, dans la trame 29, que le « login/password » est très facilement lisible :
Frame 29 (506 bytes on wire, 506 bytes captured)
...
Hypertext Transfer Protocol
GET http://www.grenouille.com/ HTTP/1.1\r\n
Request Method: GET
Request URI: http://www.grenouille.com/
Request Version: HTTP/1.1
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-excel,
application/vnd.ms-powerpoint, application/msword, application/x-shockwave-flash, */*\r\n
Accept-Language: fr\r\n
UA-CPU: x86\r\n
Accept-Encoding: gzip, deflate\r\n
User-Agent: Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)\r\n
Proxy-Authorization: Basic dXNlcjE6cGFzc3dvcmQx\r\n
Credentials: machin:epikoi
Proxy-Connection: Keep-Alive\r\n
Host: www.grenouille.com\r\n
\r\nLa suite du dialogue se fait toujours avec le proxy, ce qui démontre bien que la configuration automatique a réussi.
Il est facile de vérifier que Firefox comme Konqueror fonctionneront également suivant ce principe. Les logs de Squid montrent clairement les requêtes des clients, avec le nom de l'utilisateur concerné, puisque nous avons ici une identification obligatoire.
Cette « configuration automatique » peut rester activée en permanence. En effet, si le serveur wpad n'est pas trouvé, ou s'il ne fournit pas de script, le navigateur enverra les requêtes directement au serveur ciblé par l'URL. À première vue, cette solution semble bien souple et bien agréable pour l'utilisateur.
VI-B-3. Comment forcer nos utilisateurs Ă utiliser une telle configuration ?▲
Nous pouvons agir d'une part sur le routeur pour qu'il redirige tout flux sortant sur le port 80 (sauf bien sûr celui du proxy) vers notre serveur HTTP local, et configurer celui-ci pour que la page d'accueil ainsi que l'erreur 404 affichent une explication sur la façon de configurer son navigateur.
VI-C. SĂ©curitĂ©▲
Que l'euphorie de la réussite ne fasse toutefois pas oublier les questions de sécurité (pour le client surtout)…
Le système revient clairement à charger dans le navigateur un script qui va analyser les URL demandées par le client, et les transmettre, suivant le cas, à un serveur mandataire, et ce, de façon invisible pour l'utilisateur. En d'autres termes, le trafic HTTP (et https) peut être dérouté sur un serveur intermédiaire, sans que l'utilisateur en ait connaissance. Les questions que l'on devrait se poser seront les suivantes :
- si nous sommes sur un réseau « de confiance » et que l'administrateur a clairement annoncé ses intentions, tout va encore à peu près pour le mieux, si l'on admet que le réseau ne peut être compromis ;
- si nous sommes sur un réseau dont nous ne savons rien, nous ne savons pas par où nous passons (ce peut être le cas aussi avec un proxy transparent, mais ce dernier est facilement repérable, par exemple avec un tcptraceroute). Dans ce cas un indélicat pourrait facilement nous espionner ;
- sommes-nous certains que nos navigateurs sont assez sécurisés pour ne pas accepter n'importe quoi comme fonction FindProxyForURL ?
Le cas le plus intéressant serait sans doute sur un réseau Wi-Fi non sécurisé, ouvert à tous.
VII. SquidGuard▲
VII-A. Installation▲
Autant il est simple de mettre en service une configuration minimale de Squid opérationnelle, autant SquidGuard va nécessiter un travail méticuleux et délicat. Vous voilà prévenu…
VII-A-1. Installer SquidGuard depuis les paquetages Debian▲
# aptitude install squidguard
Lecture des listes de paquets... Fait
Construction de l'arbre des dépendances
Lecture des informations d'Ă©tat... Fait
Lecture de l'information d'Ă©tat Ă©tendu
Initialisation de l'Ă©tat des paquets... Fait
Lecture des descriptions de tâches... Fait
Les NOUVEAUX paquets suivants vont être installés :
libcompress-raw-zlib-perl{a} libcompress-zlib-perl{a} libfont-afm-perl{a} libhtml-format-perl{a} libhtml-parser-perl{a}
libhtml-tagset-perl{a} libhtml-tree-perl{a} libio-compress-base-perl{a} libio-compress-zlib-perl{a} libmailtools-perl{a}
libtimedate-perl{a} liburi-perl{a} libwww-perl{a} squidguard
0 paquets mis à jour, 14 nouvellement installés, 0 à enlever et 0 non mis à jour.
Il est nécessaire de télécharger 0o/1430ko d'archives. Après dépaquetage, 4633ko seront utilisés.
Voulez-vous continuer ? [Y/n/?]Pas de souci particulier pour cette installation.
VII-A-1-a. Un premier point sur la situation▲
Voyons ce que SquidGuard nous a installé :
# dpkg -L squidguard
/.
/var
/var/lib
/var/lib/squidguard
/var/lib/squidguard/db
/var/lib/squidguard/squidGuardRobot
/var/log
/var/log/squid
/usr
/usr/bin
/usr/bin/squidGuard
/usr/bin/sgclean
/usr/bin/hostbyname
/usr/share
/usr/share/lintian
/usr/share/lintian/overrides
/usr/share/lintian/overrides/squidguard
/usr/share/doc
/usr/share/doc/squidguard
/usr/share/doc/squidguard/README
/usr/share/doc/squidguard/README.Debian
/usr/share/doc/squidguard/copyright
/usr/share/doc/squidguard/examples
/usr/share/doc/squidguard/examples/RobotUserAgent.pm
/usr/share/doc/squidguard/examples/squidGuard-simple.cgi.gz
/usr/share/doc/squidguard/examples/squidGuard.cgi.gz
/usr/share/doc/squidguard/examples/squidGuardRobot.gz
/usr/share/doc/squidguard/examples/squidGuardRobot.in.gz
/usr/share/doc/squidguard/doc
/usr/share/doc/squidguard/doc/squidGuard.gif
/usr/share/doc/squidguard/doc/configuration.html
/usr/share/doc/squidguard/doc/faq.html
/usr/share/doc/squidguard/doc/index.html
/usr/share/doc/squidguard/doc/installation.html
/usr/share/doc/squidguard/doc/configuration.txt.gz
/usr/share/doc/squidguard/doc/faq.txt.gz
/usr/share/doc/squidguard/doc/installation.txt.gz
/usr/share/doc/squidguard/changelog.Debian.gz
/usr/share/doc/squidguard/NEWS.Debian.gz
/usr/share/doc/squidguard/changelog.gz
/usr/share/doc/squidguard/ANNOUNCE.gz
/usr/share/man
/usr/share/man/man1
/usr/share/man/man1/hostbyname.1.gz
/usr/share/man/man1/sgclean.1.gz
/usr/share/man/man1/squidGuard.1.gz
/usr/share/man/man1/update-squidguard.1.gz
/usr/sbin
/usr/sbin/update-squidguard
/etc
/etc/squid
/etc/squid/squidGuard.conf
/usr/share/doc/squidguard/README.html
/usr/share/doc/squidguard/FAQ.html
/usr/share/doc/squidguard/CONFIGURATION.html
/usr/share/doc/squidguard/CONFIGURATION.gz
/usr/share/doc/squidguard/FAQ.gzL'installation a créé un répertoire /var/lib/squidguard/db, mais il est vide. Il est destiné à contenir nos listes noires et blanches et deux scripts cgi dont nous verrons l'utilité plus tard.
Elle a également créé un fichier de configuration /etc/squid/squidGuard.conf. Voyons un peu :
# cat /etc/squid/squidGuard.conf
#
# CONFIG FILE FOR SQUIDGUARD
#
dbhome /var/lib/squidguard/db
logdir /var/log/squidIl faut indiquer à squidGuard où trouver la base de données des listes (que nous n'avons pas encore), ainsi que l'endroit où l'on désire récupérer les logs.
#
# TIME RULES:
# abbrev for weekdays:
# s = sun, m = mon, t =tue, w = wed, h = thu, f = fri, a = sat
time workhours {
weekly mtwhf 08:00 - 16:30
date *-*-01 08:00 - 16:30
}SquidGuard sait autoriser ou non l'accès en fonction de plages horaires, si nécessaire. Si des plages horaires sont définies, nous pourrons écrire des règles d'accès spécifiques dans les plages et hors des plages. Par exemple, nous pouvons autoriser un accès plus ou moins restreint tous les soirs entre 18 h et 20 h dans la semaine et entre 10 h et 20 h les samedis et dimanches, et tout bloquer en dehors de ces plages, mais pour certains utilisateurs seulement.
#
# REWRITE RULES:
#
#rew dmz {
# s@://admin/@://admin.foo.bar.no/@i
# s@://foo.bar.no/@://www.foo.bar.no/@i
#}SquidGuard sait, à la volée, modifier les URL demandées par les clients dans certaines conditions. Ce n'est probablement pas une fonction primordiale.
#
# SOURCE ADDRESSES:
#
#src admin {
# ip 1.2.3.4 1.2.3.5
# user root foo bar
# within workhours
#}
#src foo-clients {
# ip 172.16.2.32-172.16.2.100 172.16.2.100 172.16.2.200
#}
#src bar-clients {
# ip 172.16.4.0/26
#}Les sources sont là pour définir des groupes de clients. Les sources définies par des adresses IP sont les plus simples à mettre en place. Lorsque l'identification des clients est requise, il devient également possible de définir des noms d'utilisateurs dans les sources.
#
# DESTINATION CLASSES:
#dest good {
}
dest local {
}
#dest adult {
# domainlist adult/domains
# urllist adult/urls
# expressionlist adult/expressions
# redirect http://admin.foo.bar.no/cgi-bin/squidGuard.cgi?clientaddr=%a+clientname=%n+clientident=%i+srcclass=%s+targetclass=%t+url=%u
#}Les destinations, comme leur nom l'indique, définissent des ensembles de domaines, d'URL ou d'expressions régulières à appliquer aux URL.
acl {
# admin {
# pass any
# }
# foo-clients within workhours {
# pass good !in-addr !adult any
# } else {
# pass any
# }
# bar-clients {
# pass local none
# }
default {
pass local none
# rewrite dmz
# redirect http://admin.foo.bar.no/cgi-bin/squidGuard.cgi?clientaddr=%a+clientname=%n+clientident=%i+srcclass=%s+targetclass=%t+url=%u
}Enfin, les ACL permettent de définir quelle source peut aller (ou ne pas aller) vers quelle(s) destination(s). Un « ! » veut dire « NOT » (non). Dans cet exemple :
- les sources foo-clients, pendant les heures de travail, pourront accéder aux destinations good, ne pourront pas accéder aux destinations in-addr ni aux destinations adult. Le any final ne semble pas nécessaire, mais il précise que toutes les autres destinations sont possibles ;
- les sources bar-clients ne pourront accéder qu'à la destination local. Ici, le none final est important, car il bloquera toutes les autres destinations ;
- la source default s'applique à tous les clients qui ne font pas l'objet d'une ACL particulière.
À première vue, c'est assez compliqué. Nous verrons que ça l'est vraiment.
Le redirect permet, lorsqu'une destination n'est pas autorisée, de servir au client une page explicative. Les scripts cgi fournis avec SquidGuard nous serviront ici.
VII-B. Une première configuration▲
Nous n'avons pas encore les moyens de travailler efficacement, nous n'avons pas encore de base de données de destinations, mais nous pouvons déjà écrire un fichier de configuration pour SquidGuard, pour nous mettre un peu dans le bain.
Notez que, Squid3 ou Squid, peu importe, Squidguard est compilé pour trouver sa configuration dans /etc/squid/squidGuard.conf, même si nous verrons qu'au moment de s'en servir avec Squid, il est possible de lui indiquer un autre fichier.
Pour éviter de perdre beaucoup de temps par la suite, à comprendre pourquoi des choses ne fonctionnent pas comme elles le devraient d'après les docs, autant construire notre configuration là où c'est prévu.
VII-B-1. Un squidGuard.conf minimum▲
Seule la machine de l'admin pourra aller n'importe où, tous les autres hôtes du réseau resteront bloqués :
dbhome /var/lib/squidguard/db
logdir /var/log/squid
src admin {
ip 192.168.0.10
}
acl {
admin {
pass any
}
default {
pass none
redirect http://127.0.0.1/cgi-bin/squidGuard.cgi?clientaddr=%a+clientname=%n+clientident=%i+srcclass=%s+targetclass=%t+url=%u
}
}Notez l'emplacement des logs de SquidGuard. Vous pouvez bien entendu les placer ailleurs. Pensez à vérifier que l'utilisateur proxy a accès en écriture là où vous voulez placer ces logs.
Il faut maintenant placer le script cgi sur notre apache :
# gunzip /usr/share/doc/squidguard/examples/squidGuard.cgi.gz
# mv /usr/share/doc/squidguard/examples/squidGuard.cgi /usr/lib/cgi-bin/
# chmod +x /usr/lib/cgi-bin/squidGuard.cgiEnfin, il faut configurer squid3 pour qu'il invoque SquidGuard en ajoutant ces lignes à la fin de /etc/squid3/squid.conf :
url_rewrite_program /usr/bin/squidGuard -c /etc/squid/squidGuard.conf
url_rewrite_children 5Et demander à Squid de recharger sa configuration :
# /etc/init.d/squid3 reloadNous pouvons vérifier que la modification a bien été prise en compte :
# ps aux | grep squid
root 2154 0.0 0.3 6052 1564 ? Ss 13:42 0:00 /usr/sbin/squid3 -D -sYC
proxy 2156 0.0 1.3 10036 7120 ? S 13:42 0:00 (squid) -D -sYC
proxy 6669 0.0 0.1 2648 704 ? S 16:33 0:00 (squidGuard) -c /etc/squid/squidGuard.conf
proxy 6670 0.0 0.1 2644 708 ? S 16:33 0:00 (squidGuard) -c /etc/squid/squidGuard.conf
proxy 6671 0.0 0.1 2644 708 ? S 16:33 0:00 (squidGuard) -c /etc/squid/squidGuard.conf
proxy 6672 0.0 0.1 2648 712 ? S 16:33 0:00 (squidGuard) -c /etc/squid/squidGuard.conf
proxy 6673 0.0 0.1 2644 704 ? S 16:33 0:00 (squidGuard) -c /etc/squid/squidGuard.conf
...Un petit test avec une machine dont l'adresse IP n'est pas 192.168.0.10Â :

Ce n'est pas très joli, il manque des informations que nous pourrions avoir, mais le résultat est là , nous sommes bien bloqué. En revanche, nous passerons sur la machine dont l'adresse IP est 192.168.0.10.
VII-C. Configuration des destinations▲
Fort heureusement, un ensemble de destinations est activement maintenu par le Centre de Ressources Informatiques de l'Université de Toulouse, que nous trouvons ici : ftp://ftp.univ-tlse1.fr/blacklist/ [ftp://ftp.univ-tlse1.fr/blacklist/] , vous trouverez les destinations qui vous intéressent plus particulièrement, mais nous allons choisir l'archive qui les contient toutes : ftp://ftp.univ-tlse1.fr/blacklist/blacklists.tar.gz et les installer là où c'est prévu, dans /var/lib/squidguard/db.
cd /var/lib/squidguard/db/
wget ftp://ftp.univ-tlse1.fr/blacklist/blacklists.tar.gz
tar xzf blacklists.tar.gz
cd blacklistsNous avons toutes les destinations souhaitables :
ls -l | awk '{ print $8, $9, $10 }'
ads -> publicite
adult
aggressive -> agressif
agressif
astrology
audio-video
blog
cleaning
dangerous_material
dating
drogue
drugs -> drogue
filehosting
financial
forums
gambling
games
global_usage
hacking
liste_bu
mail -> forums
marketingware
mixed_adult
mobile-phone
phishing
porn -> adult
proxy -> redirector
publicite
radio
README
reaffected
redirector
sect
sexual_education
shopping
strict_redirector
strong_redirector
tricheur
violence -> agressif
warez
webmailNotez la présence de certains alias.
Le fichier « global_usage » n'est pas une liste de destinations, mais un fichier explicatif sur le contenu de cette archive.
Avant d'oublier ce détail majeur, tout le contenu de /var/lib/squidguard/db/blacklists doit être accessible en lecture et en écriture par l'utilisateur sous l'identité duquel squid tourne. Pour nous, c'est l'utilisateur « proxy » :
cd /var/lib/squidguard/db/
chown -R proxy:proxy blacklistsNous devons maintenant créer un fichier de configuration pour SquidGuard, qui tienne compte de quelques-unes de ces destinations. Par exemple : porn, drugs, phishing, marketingware
VII-C-1. CrĂ©ation des destinations▲
Allons voir ce qu'il y a dans ces divers sous-répertoires. Le répertoire porn est sans doute le plus intéressant :
- domains contient une liste de domaines à interdire ;
- expressions est vide ;
- nurls contient des URLÂ ;
- urls contient Ă©galement des URLÂ ;
- usage indique la nature de cette destination (liste noire, pornographie)Â ;
- very_restrictive_expression contient quelques expressions régulières bien senties (attention aux ressources consommées par ces expressions).
Dans squidGuard.conf, nous allons tenir compte de ces divers sous-répertoires :
dest pornographie {
urllist porn/urls
urllist porn/nurls
domainlist porn/domains
expressionlist porn/very_restrictive_expression
}Notez que le nom de la destination n'est pas forcément le même que celui utilisé dans les listes. Résistez cependant à la tentation :
- de placer des lettres accentuées dans les noms des destinations, SquidGuard ne saura les interpréter ;
- de placer des espaces dans ces noms, SquidGuard ne les interprètera pas non plus.
Vous avez compris le principe ? Voici un fichier de configuration qui devrait faire l'affaire, dans un premier temps :
dbhome /var/lib/squidguard/db/blacklists
logdir /var/log/squid
src admin {
ip 192.168.0.10
}
src users {
ip 192.168.0.0/24
}
dest pornographie {
urllist porn/urls
urllist porn/nurls
domainlist porn/domains
expressionlist porn/very_restrictive_expression
}
dest drogues {
urllist drugs/urls
domainlist drugs/domains
}
dest phishing {
urllist phishing/urls
domainlist phishing/domains
}
dest marchands_de_guerre {
urllist marketingware/urls
domainlist marketingware/domains
}
acl {
admin {
pass any
}
users {
pass !pornographie !drogues !phishing !marchands_de_guerre any
redirect http://127.0.0.1/cgi-bin/squidGuard.cgi?clientaddr=%a&clientname=%n&clientident=%i&srcclass=%s&targetclass=%t&url=%u
}
default {
pass none
redirect http://127.0.0.1/cgi-bin/squidGuard.cgi?clientaddr=%a&clientname=%n&clientident=%i&srcclass=%s&targetclass=%t&url=%u
}
}Notez l'ACL pour les « users », ce sont bien les noms des destinations qu'il faut utiliser et non pas les noms des répertoires dans la base de données.
Bon gros avertissement…
Faites très attention à ce que vous écrivez dans ce fichier de configuration, les fautes de frappe sont très vite arrivées, les copier/coller peuvent entraîner des oublis, certains répertoires de listes contiennent des domaines, des URL, des expressions, d'autres non. Il faut être très minutieux dans cette écriture, les causes d'erreurs sont très nombreuses ! (Vous voilà prévenus.)
Il existe cependant, comme nous allons le voir, un moyen de vérifier qu'il n'y a pas d'erreurs. En effet, ce n'est pas parce que le fichier de configuration est rédigé que le travail est terminé. SquidGuard, pour pouvoir travailler rapidement, n'utilise pas les fichiers texte, mais des bases de données au format Berkeley. Il est vivement conseillé de construire ces bases avant le démarrage de Squid (et donc de SquidGuard), faute de quoi, ces bases seront construites à la volée, pour chaque instance de SquidGuard. Nous en avons ici cinq, mais pour un gros site, 20 à 25 peut être plus adapté. Dans de telles conditions, le démarrage peut largement dépasser le quart d'heure !
La commande squidGuard -C all va permettre de construire ces bases de données sur disque, et SquidGuard les utilisera alors au démarrage, ce qui fera gagner énormément de temps.
su proxy
squidGuard -C allEt nous en profitons pour aller voir le fichier de logs de SquidGuard :
tail -f /var/log/squid/squidGuard.log
2007-06-07 18:14:54 [6815] init urllist /var/lib/squidguard/db/blacklists/porn/urls
2007-06-07 18:14:55 [6815] create new dbfile /var/lib/squidguard/db/blacklists/porn/urls.db
2007-06-07 18:14:55 [6815] init urllist /var/lib/squidguard/db/blacklists/porn/nurls
2007-06-07 18:14:56 [6815] create new dbfile /var/lib/squidguard/db/blacklists/porn/nurls.db
2007-06-07 18:14:56 [6815] init domainlist /var/lib/squidguard/db/blacklists/porn/domains
2007-06-07 18:15:43 [6815] create new dbfile /var/lib/squidguard/db/blacklists/porn/domains.db
2007-06-07 18:15:45 [6815] init expressionlist /var/lib/squidguard/db/blacklists/porn/very_restrictive_expression
2007-06-07 18:15:45 [6815] init urllist /var/lib/squidguard/db/blacklists/drugs/urls
2007-06-07 18:15:45 [6815] create new dbfile /var/lib/squidguard/db/blacklists/drugs/urls.db
2007-06-07 18:15:45 [6815] init domainlist /var/lib/squidguard/db/blacklists/drugs/domains
2007-06-07 18:15:45 [6815] create new dbfile /var/lib/squidguard/db/blacklists/drugs/domains.db
2007-06-07 18:15:45 [6815] init urllist /var/lib/squidguard/db/blacklists/phishing/urls
2007-06-07 18:15:45 [6815] urllist empty, removed from memory
2007-06-07 18:15:45 [6815] init domainlist /var/lib/squidguard/db/blacklists/phishing/domains
2007-06-07 18:15:45 [6815] create new dbfile /var/lib/squidguard/db/blacklists/phishing/domains.db
2007-06-07 18:15:45 [6815] init urllist /var/lib/squidguard/db/blacklists/marketingware/urls
2007-06-07 18:15:45 [6815] urllist empty, removed from memory
2007-06-07 18:15:45 [6815] init domainlist /var/lib/squidguard/db/blacklists/marketingware/domains
2007-06-07 18:15:45 [6815] create new dbfile /var/lib/squidguard/db/blacklists/marketingware/domains.db
2007-06-07 18:15:45 [6815] squidGuard 1.2.0 started (1181232894.801)
2007-06-07 18:15:45 [6815] db update done
2007-06-07 18:15:45 [6815] squidGuard stopped (1181232945.727)Vous devriez pouvoir repérer toute erreur dans ces logs.
VII-C-1-a. Un second point sur la situation▲
- Il est donc nécessaire de porter une grande attention à la rédaction du fichier de configuration.
- Il est également nécessaire de construire les bases de données Berkeley après avoir écrit le fichier de configuration, car seules les destinations définies dans ce fichier seront compilées (vous trouverez des fichiers domains.db et urls.db dans les destinations utilisées). Autrement dit, si vous devez ajouter une configuration par la suite, il faudra penser à la compiler.
- SquidGuard -C all part du principe que le fichier de configuration de SquidGuard se trouve (pour Debian) dans /,etc./squid/. Si vous voulez à tout prix placer sa configuration ailleurs, il vous faudra utiliser l'option -c : squidGuard -c /etc/squid3/squidGueard.conf -C all par exemple.
- Le fichier de logs de SquidGuard est d'un grand secours pour cette opération, car il avertira de tout problème de configuration.
La commande SquidGuard sait Ă©galement faire quelques autres choses (man Squidguard)
Mais nous sommes encore très loin du compte…
Puisqu'on n'est pas là pour réaliser une passoire, signalons tout de même ceci :
SquidQuard redirige les URI interdits vers un URI local, généralement destiné à expliquer pourquoi le site convoité a été bloqué. Généralement, il s'agit d'un script CGI.
Si cet URI de redirection n'est pas indiqué, ne sachant pas où rediriger les requêtes interdites, SquidGuard les laissera tout de même passer, réalisant ainsi une pernicieuse passoire !!!
Il est donc impératif d'installer un tel script ou, à défaut, une page d'avertissement quelconque vers laquelle rediriger les URI interdits.
Le paquetage Debian de SquidGuard n'installe rien à ce propos, mais vous trouverez dans /usr/share/doc/squidguard/examples deux scripts dont vous pourrez vous inspirer ou essayer d'utiliser en l'état (après les avoir installés dans /usr/lib/cgi-bin et rendus exécutables).
Mais ce n'est pas tout, il vous faudra aussi revenir sur l'ACL Default, pour spécifier la redirection :
http://127.0.0.1/cgi-bin/squidGuard.cgi?clientaddr=%a&srcclass=%s&targetclass=%t&url=%uCette ligne part du principe que vous avez sur la machine locale un serveur HTTP en état de marche et qu'il dispose d'un script squidGuard.cgi. Les paramètres transmis dans cet exemple permettent de communiquer au script toutes les informations nécessaires pour identifier les circonstances du blocage.
Bien entendu, ce script, ou un autre (page php comprise) peuvent être situés sur une machine autre, il suffit de rédiger l'URI de redirection en fonction.
VIII. Plus sur SquidGuard▲
VIII-A. De la fiabilitĂ© des « blacklists »▲
Il n'est absolument pas question de critiquer le travail fourni par l'Université de Toulouse, mais les listes que nous utilisons ici comportent quelques défauts :
- elles référencent des sites ou des sous-sites qui ne devraient pas forcément l'être. Les robots qui cherchent des mots-clés peuvent en trouver sur des pages anodines ;
- elles ne référencent pas des sites qui devraient l'être. L'Internet est un monde mouvant où rien n'est écrit dans le marbre.
Ne vous attendez donc pas à un filtrage parfait. Vous aurez sans doute des appels de vos utilisateurs qui se plaindront de ne pouvoir accéder à des pages parfaitement acceptables, de même qu'il vous faudra surveiller que des pages indésirables ne passent pas à travers votre filtrage.
Les listes publiées par l'Université de Toulouse sont régulièrement mises à jour, à vous de suivre leurs évolutions.
VIII-B. StratĂ©gies de filtrage▲
Il y a deux stratégies de base, dans tout mode de contrôle d'accès.
VIII-B-1. Tout est bloquĂ© sauf…▲
Ici, nous interdisons tous les sites a priori, et utilisons alors des « listes blanches » qui contiendront les seules destinations autorisées. Cette méthode, très totalitaire, peut tout de même être envisagée dans certains cas. Très peu de destinations seront accessibles, mais vous les aurez choisies avec soin.
Il vous faudra construire ces listes blanches et écrire des ACL du genre :
pass liste_1 liste_2 liste_3 noneoĂą liste_1, liste_2 et liste_3 sont vos listes blanches. Elles se construisent exactement comme une liste noire.
VIII-B-2. Tout est permis sauf…▲
Ici, nous utilisons bien les listes noires, comme vu plus haut, avec les risques que nous avons déjà évoqués. Il s'agit sans doute de ce que vous préfèrerez mettre en place dans la plupart des cas.
VIII-C. StratĂ©gies de maintenance▲
Si vous allez jeter un œil dans les fichiers de blacklists, vous constaterez que certains sont très volumineux (pornographie, par exemple). Il est certes possible de modifier ces fichiers en fonction de vos observations, pour retirer des destinations qui ne devraient pas être bloquées, ou ajouter des destinations manquantes. L'inconvénient de ce système est qu'il faut reconstruire l'intégralité de la base de données (.db) associée à ce fichier après chaque modification, ce qui peut prendre du temps.
Une autre méthode consiste à utiliser des fichiers de différences. Cette méthode permet des corrections rapides, mais désynchronise les bases de données et les fichiers textes. Il suffit de créer un fichier domains.diff et/ou urls.diff dans le répertoire qui contient les URL et les domaines à ajouter (mettez un + devant) ou à enlever (mettez un - devant) puis de lancer squidguard -u. Cette opération permettra rapidement de mettre à jour les fichiers .db mais ne touchera pas aux fichiers texte correspondants. Il faudra ensuite enlever les fichiers .diff crées.
Si vous adoptez cette méthode sans plus de précautions, vos sources texte ne seront rapidement plus du tout l'image des bases de données Berkeley.
Exemple d'un fichier domains.diff :
-laposte.net
+playboy.comCe fichier placé dans le répertoire porn permettra rapidement d'ajouter playboy.com et de retirer laposte.net du fichier domains.db, par la commande :
squidGuard -usuivie de :
squid -k reconfigureL'opération est très rapide et vos modifications resteront pérennes après mise à jour des listes noires.
VIII-D. Outils de surveillance▲
Il existe plusieurs outils destinés à exploiter les logs de Squid, principalement le log access.log, parmi lesquels Calamaris, Mysar (MySQL Squid Access Report), et bien d'autres encore.
Calamaris comme Mysar offrent l'avantage de permettre de découvrir facilement quels sont les sites les plus visités et donc de trouver assez simplement les fuites de votre filtrage.
IX. Remerciements Developpez▲
Vous pouvez retrouver l'article original ici : L'Internet Rapide et Permanent. Christian Caleca a aimablement autorisé l'équipe « Réseaux » de Developpez.com à reprendre son article. Retrouvez tous les articles de Christian Caleca sur cette page.
Nos remerciements Ă ClaudeLELOUP pour sa relecture orthographique.
N'hésitez pas à commenter cet article ! 3 commentaires ![]()